 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWeddit : A Dataset of Triggering Stories Predominantly Shared by Women on Reddit
Jan 16, 2026Warning: This paper may contain examples and topics that may be disturbing to some readers, especially survivors of miscarriage and sexual violence. People affected by abortion, miscarriage, or sexual violence often share their experiences on social media to express emotions and seek support. On public platforms like Reddit, where users can post long, detailed narratives (up to 40,000 characters), readers may be exposed to distressing content. Although Reddit allows manual trigger warnings, many users omit them due to limited awareness or uncertainty about which categories apply. There is scarcity of datasets on Reddit stories labeled for triggering experiences. We propose a curated Reddit dataset, TWeddit, covering triggering experiences related to issues majorly faced by women. Our linguistic analyses show that annotated stories in TWeddit express distinct topics and moral foundations, making the dataset useful for a wide range of future research.
Extracting Incidents, Effects, and Requested Advice from MeToo Posts
Mar 19, 2023



Survivors of sexual harassment frequently share their experiences on social media, revealing their feelings and emotions and seeking advice. We observed that on Reddit, survivors regularly share long posts that describe a combination of (i) a sexual harassment incident, (ii) its effect on the survivor, including their feelings and emotions, and (iii) the advice being sought. We term such posts MeToo posts, even though they may not be so tagged and may appear in diverse subreddits. A prospective helper (such as a counselor or even a casual reader) must understand a survivor's needs from such posts. But long posts can be time-consuming to read and respond to. Accordingly, we address the problem of extracting key information from a long MeToo post. We develop a natural language-based model to identify sentences from a post that describe any of the above three categories. On ten-fold cross-validation of a dataset, our model achieves a macro F1 score of 0.82. In addition, we contribute MeThree, a dataset comprising 8,947 labeled sentences extracted from Reddit posts. We apply the LIWC-22 toolkit on MeThree to understand how different language patterns in sentences of the three categories can reveal differences in emotional tone, authenticity, and other aspects.
PACO: Provocation Involving Action, Culture, and Oppression
Mar 19, 2023In India, people identify with a particular group based on certain attributes such as religion. The same religious groups are often provoked against each other. Previous studies show the role of provocation in increasing tensions between India's two prominent religious groups: Hindus and Muslims. With the advent of the Internet, such provocation also surfaced on social media platforms such as WhatsApp. By leveraging an existing dataset of Indian WhatsApp posts, we identified three categories of provoking sentences against Indian Muslims. Further, we labeled 7,000 sentences for three provocation categories and called this dataset PACO. We leveraged PACO to train a model that can identify provoking sentences from a WhatsApp post. Our best model is fine-tuned RoBERTa and achieved a 0.851 average AUC score over five-fold cross-validation. Automatically identifying provoking sentences could stop provoking text from reaching out to the masses, and can prevent possible discrimination or violence against the target religious group. Further, we studied the provocative speech through a pragmatic lens, by identifying the dialog acts and impoliteness super-strategies used against the religious group.
Reappraising Domain Generalization in Neural Networks
Oct 15, 2021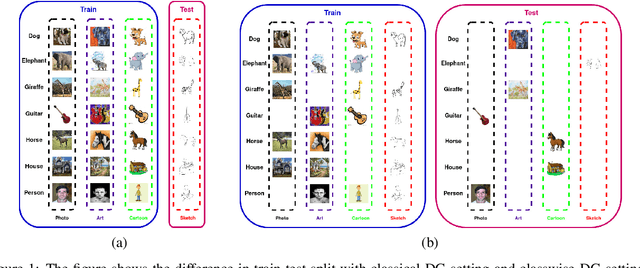


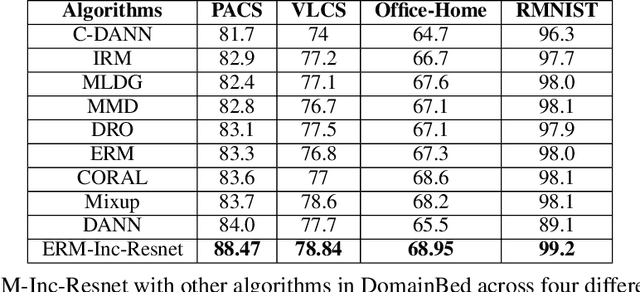
Domain generalization (DG) of machine learning algorithms is defined as their ability to learn a domain agnostic hypothesis from multiple training distributions, which generalizes onto data from an unseen domain. DG is vital in scenarios where the target domain with distinct characteristics has sparse data for training. Aligning with recent work~\cite{gulrajani2020search}, we find that a straightforward Empirical Risk Minimization (ERM) baseline consistently outperforms existing DG methods. We present ablation studies indicating that the choice of backbone, data augmentation, and optimization algorithms overshadows the many tricks and trades explored in the prior art. Our work leads to a new state of the art on the four popular DG datasets, surpassing previous methods by large margins. Furthermore, as a key contribution, we propose a classwise-DG formulation, where for each class, we randomly select one of the domains and keep it aside for testing. We argue that this benchmarking is closer to human learning and relevant in real-world scenarios. We comprehensively benchmark classwise-DG on the DomainBed and propose a method combining ERM and reverse gradients to achieve the state-of-the-art results. To our surprise, despite being exposed to all domains during training, the classwise DG is more challenging than traditional DG evaluation and motivates more fundamental rethinking on the problem of DG.