 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReappraising Domain Generalization in Neural Networks
Paper and Code
Oct 15, 2021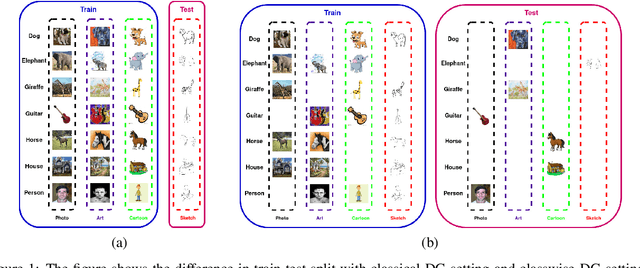


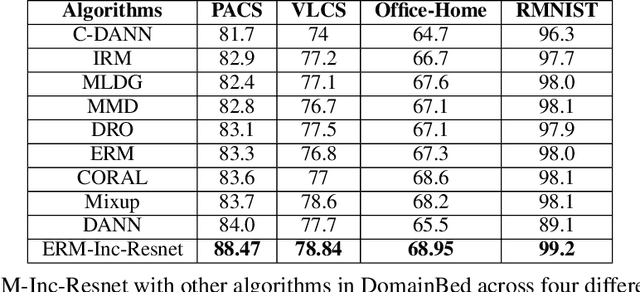
Domain generalization (DG) of machine learning algorithms is defined as their ability to learn a domain agnostic hypothesis from multiple training distributions, which generalizes onto data from an unseen domain. DG is vital in scenarios where the target domain with distinct characteristics has sparse data for training. Aligning with recent work~\cite{gulrajani2020search}, we find that a straightforward Empirical Risk Minimization (ERM) baseline consistently outperforms existing DG methods. We present ablation studies indicating that the choice of backbone, data augmentation, and optimization algorithms overshadows the many tricks and trades explored in the prior art. Our work leads to a new state of the art on the four popular DG datasets, surpassing previous methods by large margins. Furthermore, as a key contribution, we propose a classwise-DG formulation, where for each class, we randomly select one of the domains and keep it aside for testing. We argue that this benchmarking is closer to human learning and relevant in real-world scenarios. We comprehensively benchmark classwise-DG on the DomainBed and propose a method combining ERM and reverse gradients to achieve the state-of-the-art results. To our surprise, despite being exposed to all domains during training, the classwise DG is more challenging than traditional DG evaluation and motivates more fundamental rethinking on the problem of DG.