 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting retrosynthetic pathways using a combined linguistic model and hyper-graph exploration strategy
Oct 17, 2019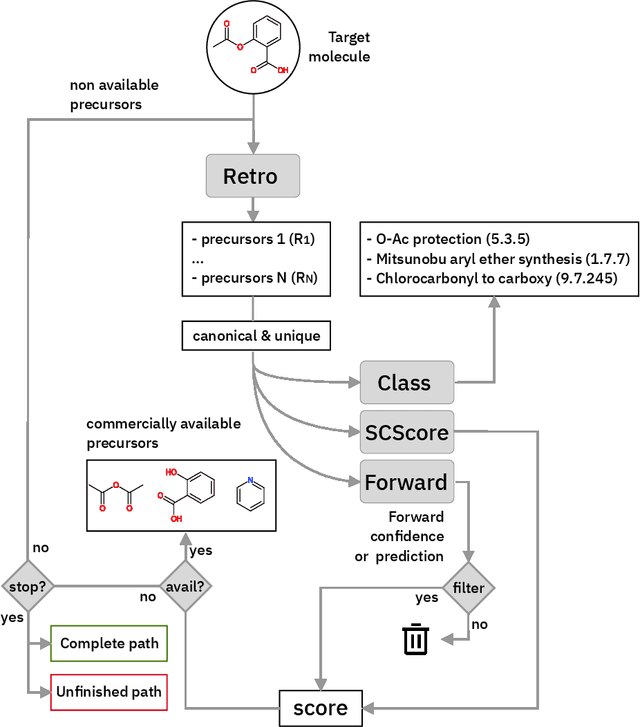
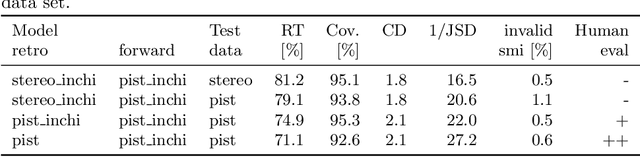
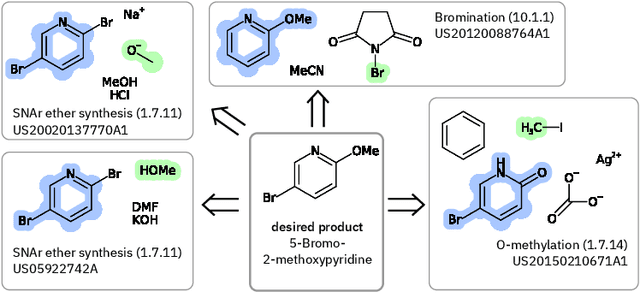
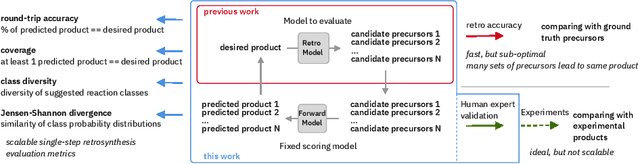
We present an extension of our Molecular Transformer architecture combined with a hyper-graph exploration strategy for automatic retrosynthesis route planning without human intervention. The single-step retrosynthetic model sets a new state of the art for predicting reactants as well as reagents, solvents and catalysts for each retrosynthetic step. We introduce new metrics (coverage, class diversity, round-trip accuracy and Jensen-Shannon divergence) to evaluate the single-step retrosynthetic models, using the forward prediction and a reaction classification model always based on the transformer architecture. The hypergraph is constructed on the fly, and the nodes are filtered and further expanded based on a Bayesian-like probability. We critically assessed the end-to-end framework with several retrosynthesis examples from literature and academic exams. Overall, the frameworks has a very good performance with few weaknesses due to the bias induced during the training process. The use of the newly introduced metrics opens up the possibility to optimize entire retrosynthetic frameworks through focusing on the performance of the single-step model only.
Constrained deep neural network architecture search for IoT devices accounting hardware calibration
Sep 24, 2019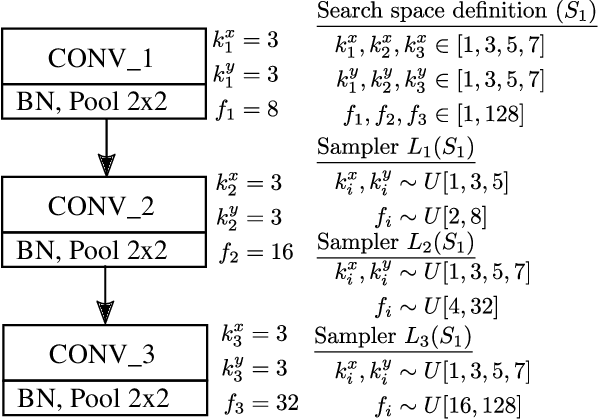
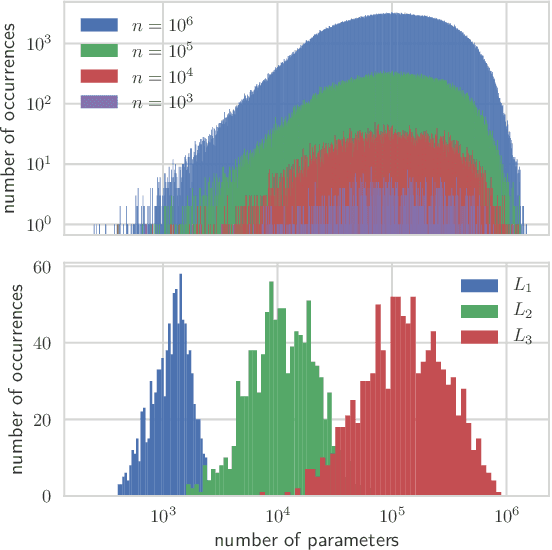
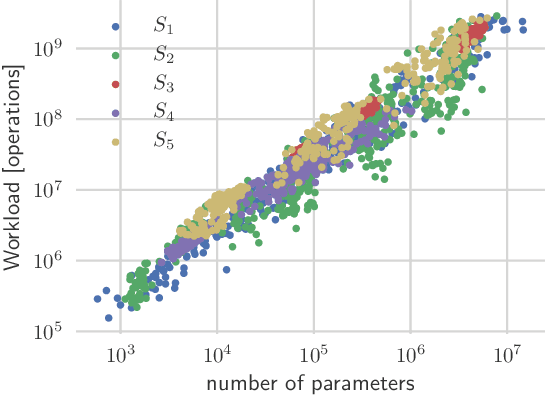
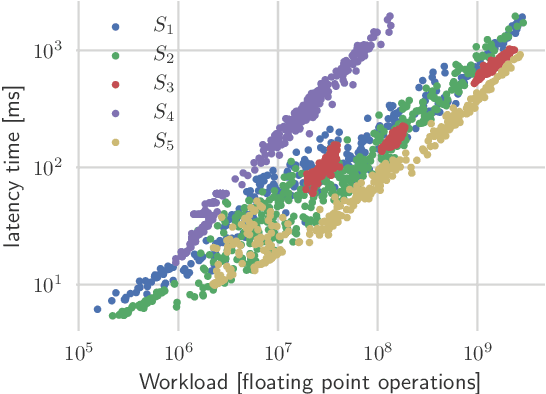
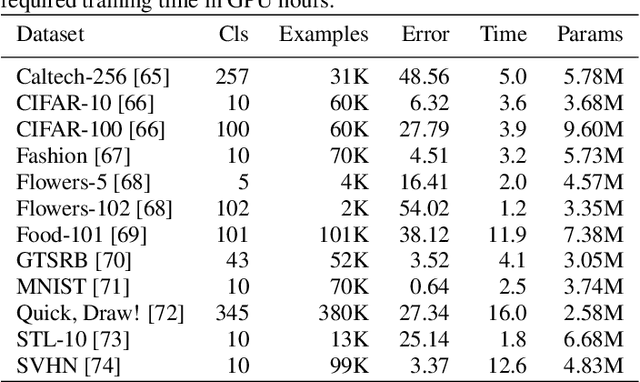
Deep neural networks achieve outstanding results in challenging image classification tasks. However, the design of network topologies is a complex task and the research community makes a constant effort in discovering top-accuracy topologies, either manually or employing expensive architecture searches. In this work, we propose a unique narrow-space architecture search that focuses on delivering low-cost and fast executing networks that respect strict memory and time requirements typical of Internet-of-Things (IoT) near-sensor computing platforms. Our approach provides solutions with classification latencies below 10ms running on a $35 device with 1GB RAM and 5.6GFLOPS peak performance. The narrow-space search of floating-point models improves the accuracy on CIFAR10 of an established IoT model from 70.64% to 74.87% respecting the same memory constraints. We further improve the accuracy to 82.07% by including 16-bit half types and we obtain the best accuracy of 83.45% by extending the search with model optimized IEEE 754 reduced types. To the best of our knowledge, we are the first that empirically demonstrate on over 3000 trained models that running with reduced precision pushes the Pareto optimal front by a wide margin. Under a given memory constraint, accuracy is improved by over 7% points for half and over 1% points further for running with the best model individual format.
An Information Extraction and Knowledge Graph Platform for Accelerating Biochemical Discoveries
Jul 19, 2019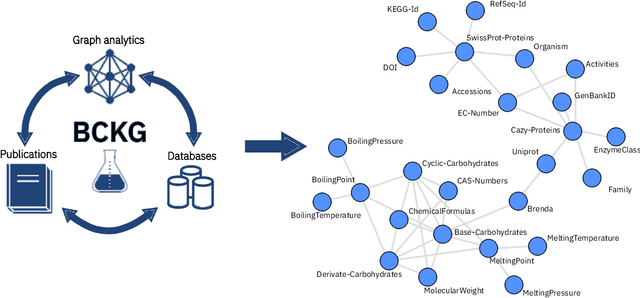
Information extraction and data mining in biochemical literature is a daunting task that demands resource-intensive computation and appropriate means to scale knowledge ingestion. Being able to leverage this immense source of technical information helps to drastically reduce costs and time to solution in multiple application fields from food safety to pharmaceutics. We present a scalable document ingestion system that integrates data from databases and publications (in PDF format) in a biochemistry knowledge graph (BCKG). The BCKG is a comprehensive source of knowledge that can be queried to retrieve known biochemical facts and to generate novel insights. After describing the knowledge ingestion framework, we showcase an application of our system in the field of carbohydrate enzymes. The BCKG represents a way to scale knowledge ingestion and automatically exploit prior knowledge to accelerate discovery in biochemical sciences.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019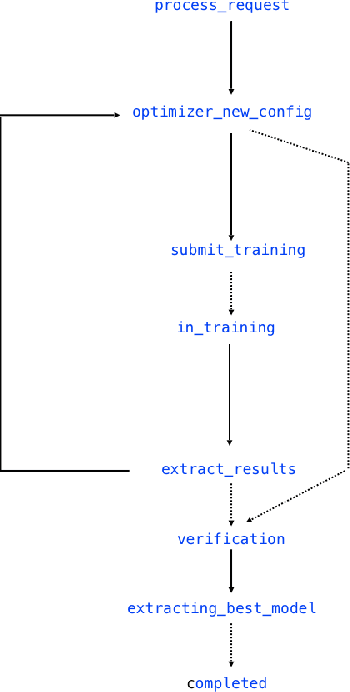
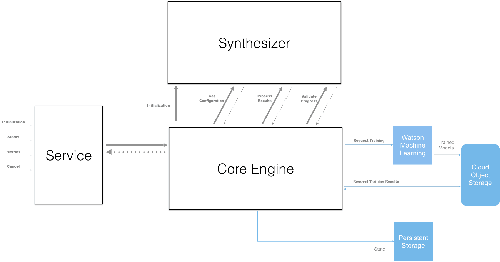
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.
Molecular Transformer for Chemical Reaction Prediction and Uncertainty Estimation
Nov 06, 2018
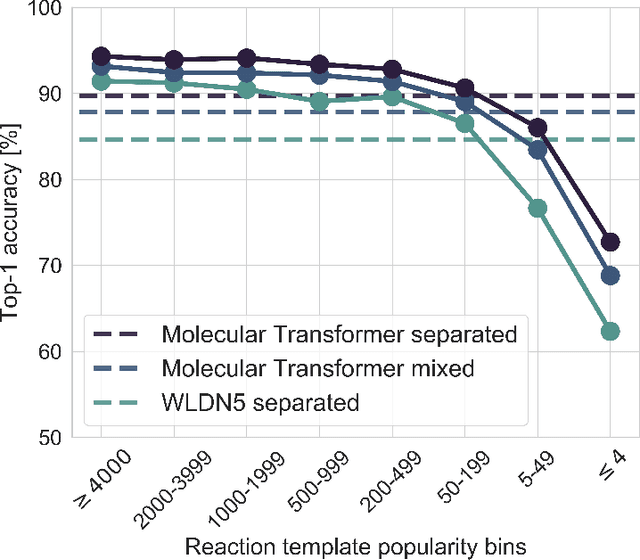
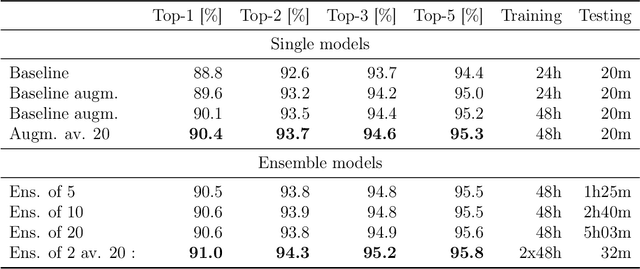
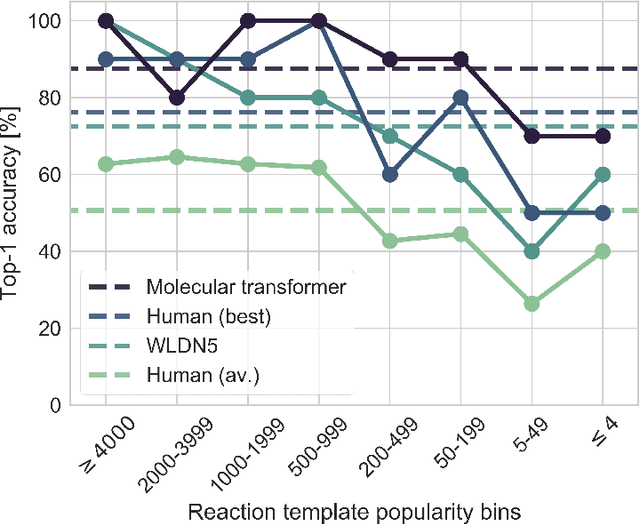
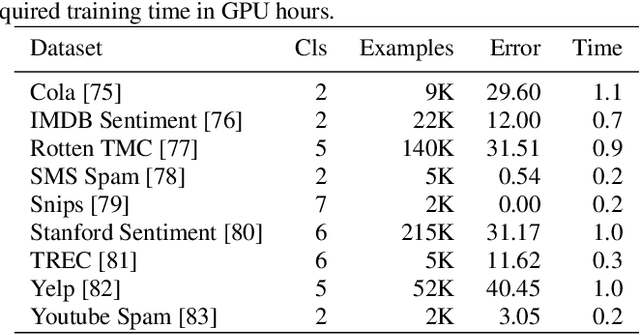
Organic synthesis is one of the key stumbling blocks in medicinal chemistry. A necessary yet unsolved step in planning synthesis is solving the forward problem: given reactants and reagents, predict the products. Similar to other works, we treat reaction prediction as a machine translation problem between SMILES strings of reactants-reagents and the products. We show that a multi-head attention Molecular Transformer model outperforms all algorithms in the literature, achieving a top-1 accuracy above 90% on a common benchmark dataset. Our algorithm requires no handcrafted rules, and accurately predicts subtle chemical transformations. Crucially, our model can accurately estimate its own uncertainty, with an uncertainty score that is 89% accurate in terms of classifying whether a prediction is correct. Furthermore, we show that the model is able to handle inputs without reactant-reagent split and including stereochemistry, which makes our method universally applicable.
BAGAN: Data Augmentation with Balancing GAN
Jun 05, 2018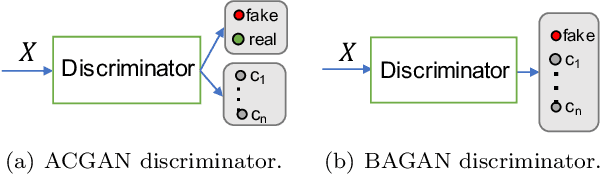
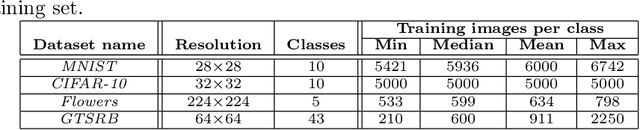

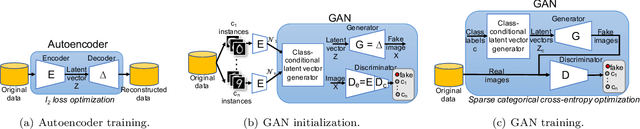
Image classification datasets are often imbalanced, characteristic that negatively affects the accuracy of deep-learning classifiers. In this work we propose balancing GAN (BAGAN) as an augmentation tool to restore balance in imbalanced datasets. This is challenging because the few minority-class images may not be enough to train a GAN. We overcome this issue by including during the adversarial training all available images of majority and minority classes. The generative model learns useful features from majority classes and uses these to generate images for minority classes. We apply class conditioning in the latent space to drive the generation process towards a target class. The generator in the GAN is initialized with the encoder module of an autoencoder that enables us to learn an accurate class-conditioning in the latent space. We compare the proposed methodology with state-of-the-art GANs and demonstrate that BAGAN generates images of superior quality when trained with an imbalanced dataset.
Corpus Conversion Service: A Machine Learning Platform to Ingest Documents at Scale
May 24, 2018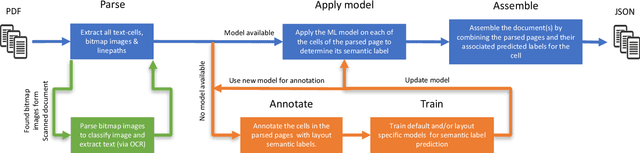
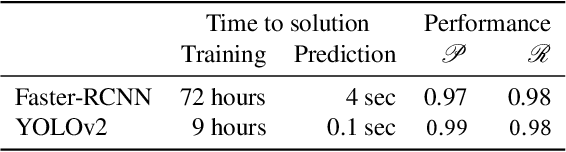

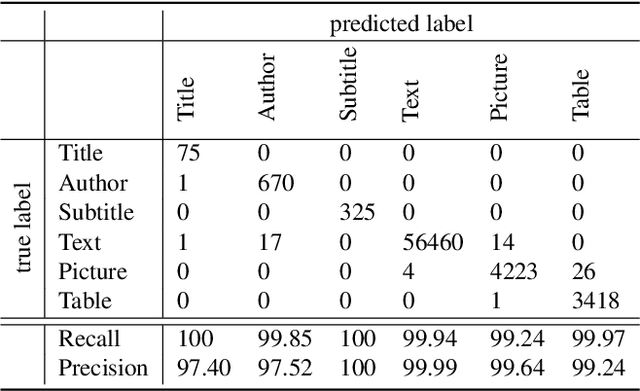
Over the past few decades, the amount of scientific articles and technical literature has increased exponentially in size. Consequently, there is a great need for systems that can ingest these documents at scale and make the contained knowledge discoverable. Unfortunately, both the format of these documents (e.g. the PDF format or bitmap images) as well as the presentation of the data (e.g. complex tables) make the extraction of qualitative and quantitive data extremely challenging. In this paper, we present a modular, cloud-based platform to ingest documents at scale. This platform, called the Corpus Conversion Service (CCS), implements a pipeline which allows users to parse and annotate documents (i.e. collect ground-truth), train machine-learning classification algorithms and ultimately convert any type of PDF or bitmap-documents to a structured content representation format. We will show that each of the modules is scalable due to an asynchronous microservice architecture and can therefore handle massive amounts of documents. Furthermore, we will show that our capability to gather ground-truth is accelerated by machine-learning algorithms by at least one order of magnitude. This allows us to both gather large amounts of ground-truth in very little time and obtain very good precision/recall metrics in the range of 99\% with regard to content conversion to structured output. The CCS platform is currently deployed on IBM internal infrastructure and serving more than 250 active users for knowledge-engineering project engagements.
Corpus Conversion Service: A machine learning platform to ingest documents at scale
May 15, 2018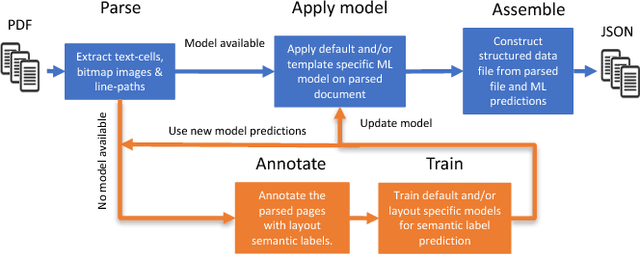
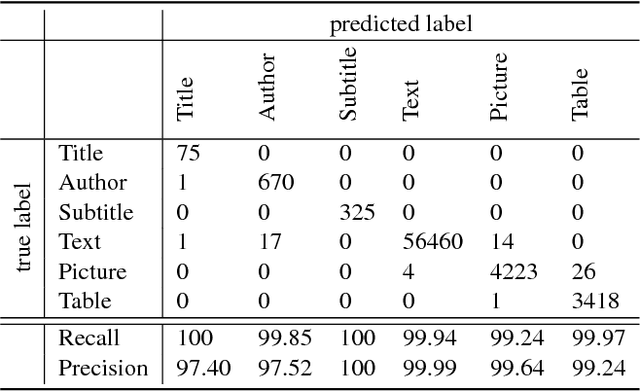
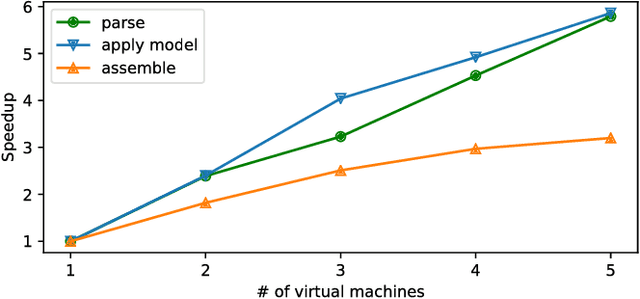

Over the past few decades, the amount of scientific articles and technical literature has increased exponentially in size. Consequently, there is a great need for systems that can ingest these documents at scale and make their content discoverable. Unfortunately, both the format of these documents (e.g. the PDF format or bitmap images) as well as the presentation of the data (e.g. complex tables) make the extraction of qualitative and quantitive data extremely challenging. We present a platform to ingest documents at scale which is powered by Machine Learning techniques and allows the user to train custom models on document collections. We show precision/recall results greater than 97% with regard to conversion to structured formats, as well as scaling evidence for each of the microservices constituting the platform.
Incremental Training of Deep Convolutional Neural Networks
Mar 27, 2018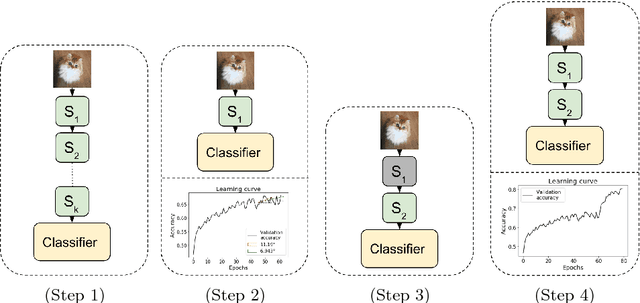
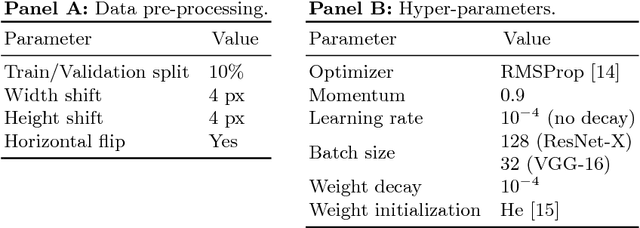
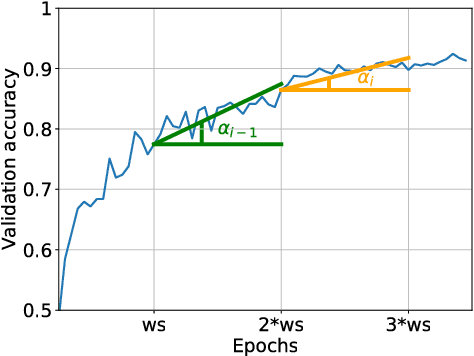
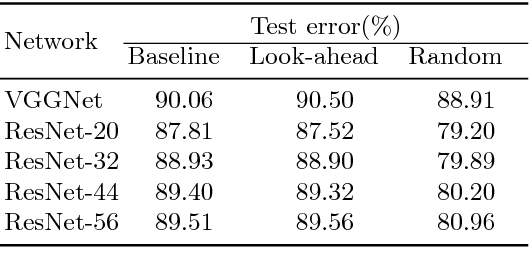
We propose an incremental training method that partitions the original network into sub-networks, which are then gradually incorporated in the running network during the training process. To allow for a smooth dynamic growth of the network, we introduce a look-ahead initialization that outperforms the random initialization. We demonstrate that our incremental approach reaches the reference network baseline accuracy. Additionally, it allows to identify smaller partitions of the original state-of-the-art network, that deliver the same final accuracy, by using only a fraction of the global number of parameters. This allows for a potential speedup of the training time of several factors. We report training results on CIFAR-10 for ResNet and VGGNet.
Efficient Image Dataset Classification Difficulty Estimation for Predicting Deep-Learning Accuracy
Mar 26, 2018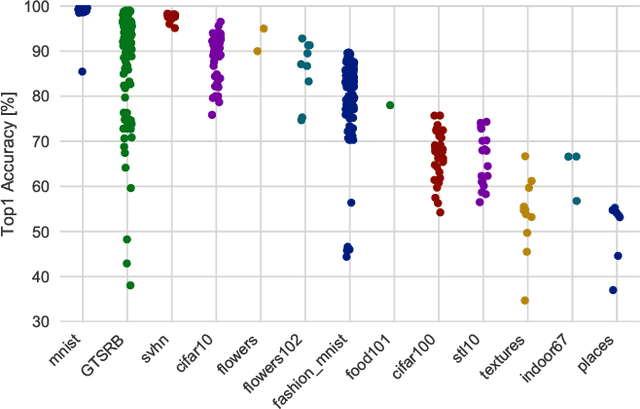
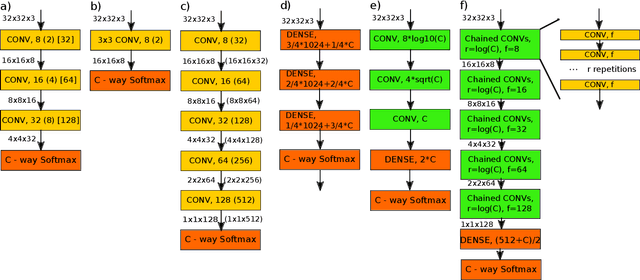
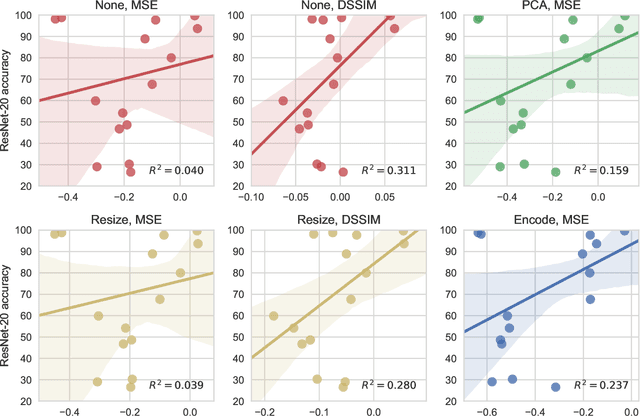
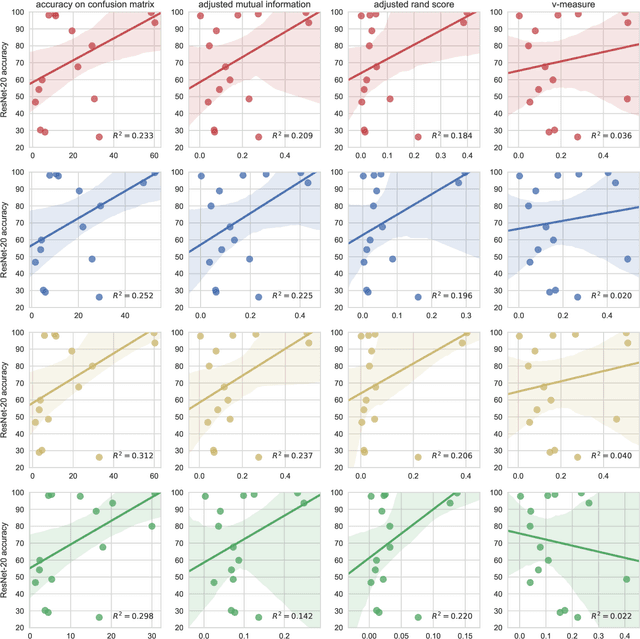
In the deep-learning community new algorithms are published at an incredible pace. Therefore, solving an image classification problem for new datasets becomes a challenging task, as it requires to re-evaluate published algorithms and their different configurations in order to find a close to optimal classifier. To facilitate this process, before biasing our decision towards a class of neural networks or running an expensive search over the network space, we propose to estimate the classification difficulty of the dataset. Our method computes a single number that characterizes the dataset difficulty 27x faster than training state-of-the-art networks. The proposed method can be used in combination with network topology and hyper-parameter search optimizers to efficiently drive the search towards promising neural-network configurations.