 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT4SD: Generative Toolkit for Scientific Discovery
Jul 08, 2022
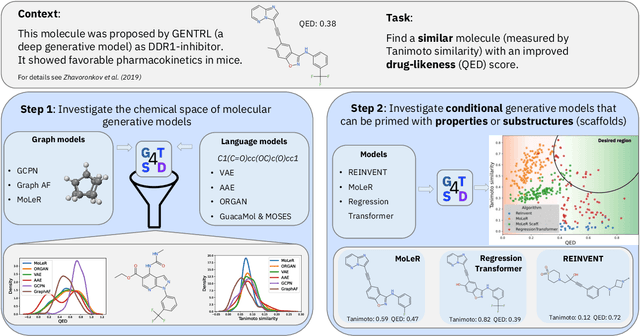
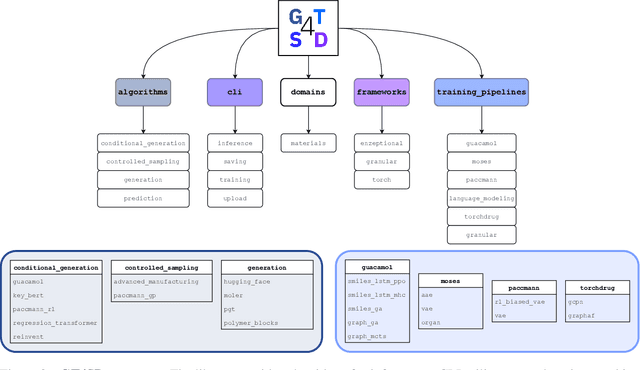
With the growing availability of data within various scientific domains, generative models hold enormous potential to accelerate scientific discovery at every step of the scientific method. Perhaps their most valuable application lies in the speeding up of what has traditionally been the slowest and most challenging step of coming up with a hypothesis. Powerful representations are now being learned from large volumes of data to generate novel hypotheses, which is making a big impact on scientific discovery applications ranging from material design to drug discovery. The GT4SD (https://github.com/GT4SD/gt4sd-core) is an extensible open-source library that enables scientists, developers and researchers to train and use state-of-the-art generative models for hypothesis generation in scientific discovery. GT4SD supports a variety of uses of generative models across material science and drug discovery, including molecule discovery and design based on properties related to target proteins, omic profiles, scaffold distances, binding energies and more.
An Information Extraction and Knowledge Graph Platform for Accelerating Biochemical Discoveries
Jul 19, 2019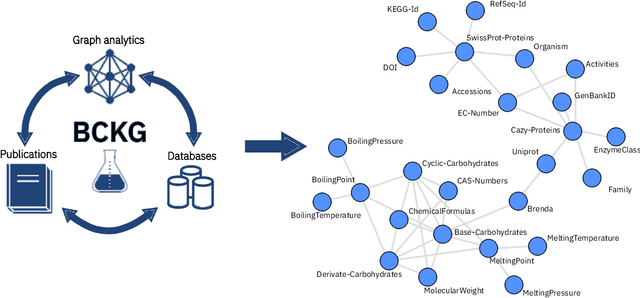
Information extraction and data mining in biochemical literature is a daunting task that demands resource-intensive computation and appropriate means to scale knowledge ingestion. Being able to leverage this immense source of technical information helps to drastically reduce costs and time to solution in multiple application fields from food safety to pharmaceutics. We present a scalable document ingestion system that integrates data from databases and publications (in PDF format) in a biochemistry knowledge graph (BCKG). The BCKG is a comprehensive source of knowledge that can be queried to retrieve known biochemical facts and to generate novel insights. After describing the knowledge ingestion framework, we showcase an application of our system in the field of carbohydrate enzymes. The BCKG represents a way to scale knowledge ingestion and automatically exploit prior knowledge to accelerate discovery in biochemical sciences.