 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Training of Deep Convolutional Neural Networks
Mar 27, 2018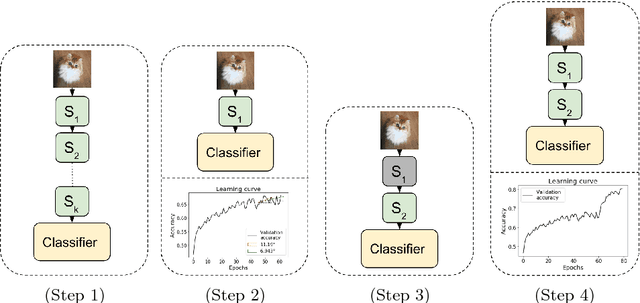
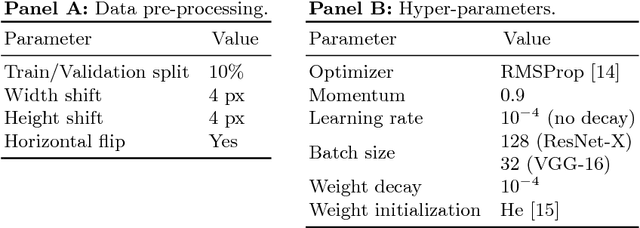
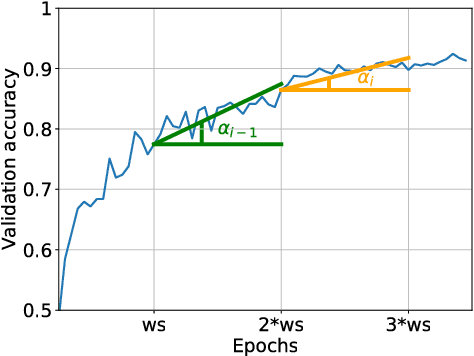
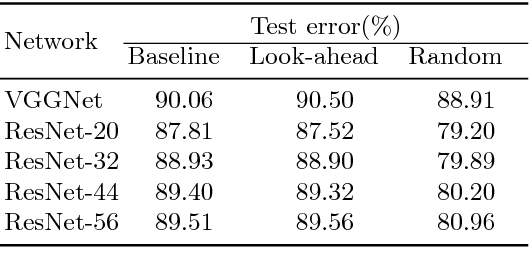
We propose an incremental training method that partitions the original network into sub-networks, which are then gradually incorporated in the running network during the training process. To allow for a smooth dynamic growth of the network, we introduce a look-ahead initialization that outperforms the random initialization. We demonstrate that our incremental approach reaches the reference network baseline accuracy. Additionally, it allows to identify smaller partitions of the original state-of-the-art network, that deliver the same final accuracy, by using only a fraction of the global number of parameters. This allows for a potential speedup of the training time of several factors. We report training results on CIFAR-10 for ResNet and VGGNet.