 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Recurrent NMF for Speech Separation by Unfolding Iterative Thresholding
Paper and Code
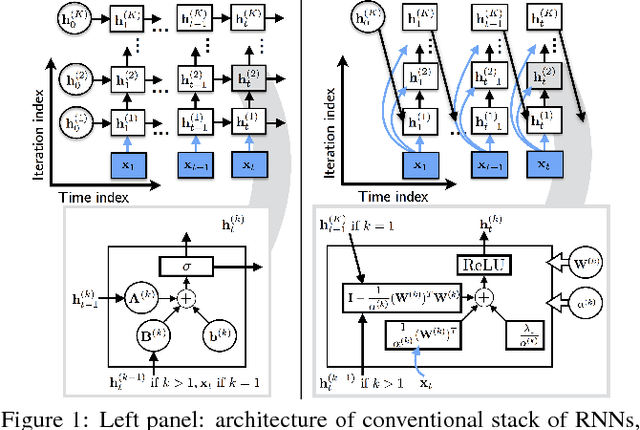
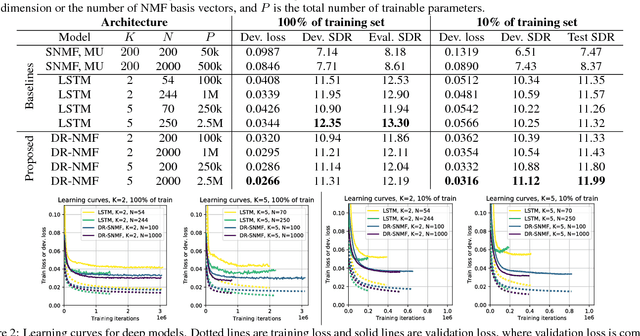
In this paper, we propose a novel recurrent neural network architecture for speech separation. This architecture is constructed by unfolding the iterations of a sequential iterative soft-thresholding algorithm (ISTA) that solves the optimization problem for sparse nonnegative matrix factorization (NMF) of spectrograms. We name this network architecture deep recurrent NMF (DR-NMF). The proposed DR-NMF network has three distinct advantages. First, DR-NMF provides better interpretability than other deep architectures, since the weights correspond to NMF model parameters, even after training. This interpretability also provides principled initializations that enable faster training and convergence to better solutions compared to conventional random initialization. Second, like many deep networks, DR-NMF is an order of magnitude faster at test time than NMF, since computation of the network output only requires evaluating a few layers at each time step. Third, when a limited amount of training data is available, DR-NMF exhibits stronger generalization and separation performance compared to sparse NMF and state-of-the-art long-short term memory (LSTM) networks. When a large amount of training data is available, DR-NMF achieves lower yet competitive separation performance compared to LSTM networks.