 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Clipping for Improved Generalization in Machine Learning
Feb 27, 2023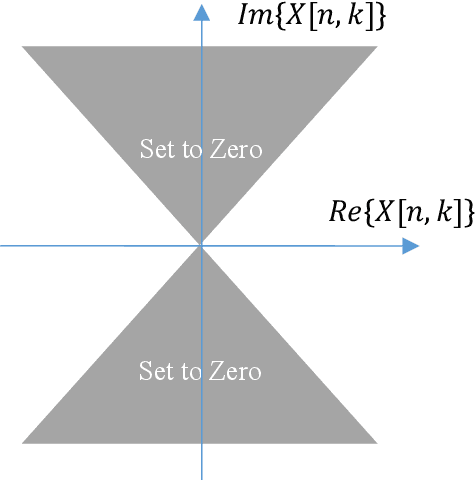
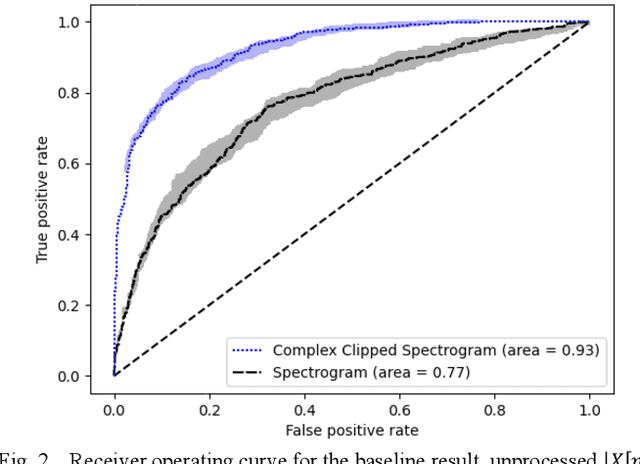
For many machine learning applications, a common input representation is a spectrogram. The underlying representation for a spectrogram is a short time Fourier transform (STFT) which gives complex values. The spectrogram uses the magnitude of these complex values, a commonly used detector. Modern machine learning systems are commonly overparameterized, where possible ill-conditioning problems are ameliorated by regularization. The common use of rectified linear unit (ReLU) activation functions between layers of a deep net has been shown to help this regularization, improving system performance. We extend this idea of ReLU activation to detection for the complex STFT, providing a simple-to-compute modified and regularized spectrogram, which potentially results in better behaved training. We then confirmed the benefit of this approach on a noisy acoustic data set used for a real-world application. Generalization performance improved substantially. This approach might benefit other applications which use time-frequency mappings, for acoustic, audio, and other applications.
Estimating and Analyzing Neural Flow Using Signal Processing on Graphs
May 27, 2022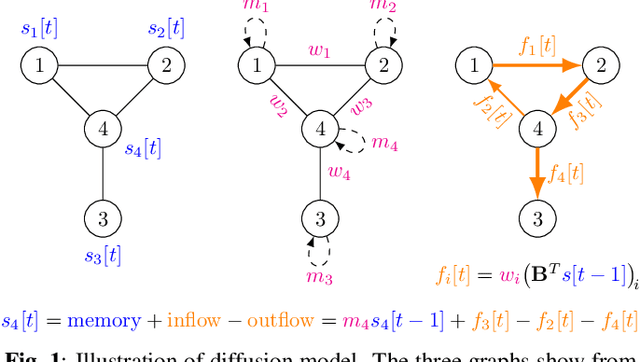
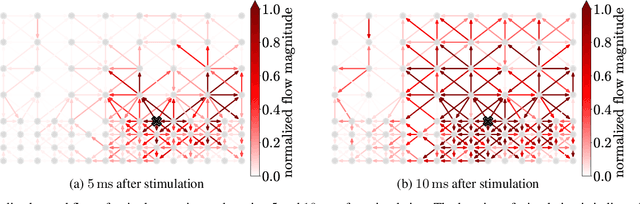
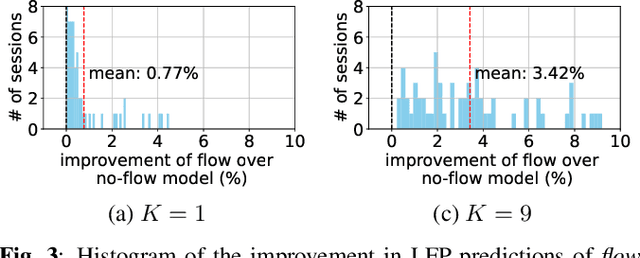

Neural communication is fundamentally linked to the brain's overall state and health status. We demonstrate how communication in the brain can be estimated from recorded neural activity using concepts from graph signal processing. The communication is modeled as a flow signals on the edges of a graph and naturally arises from a graph diffusion process. We apply the diffusion model to local field potential (LFP) measurements of brain activity of two non-human primates to estimate the communication flow during a stimulation experiment. Comparisons with a baseline model demonstrate that adding the neural flow can improve LFP predictions. Finally, we demonstrate how the neural flow can be decomposed into a gradient and rotational component and show that the gradient component depends on the location of stimulation.
Using a Novel COVID-19 Calculator to Measure Positive U.S. Socio-Economic Impact of a COVID-19 Pre-Screening Solution
Jan 21, 2022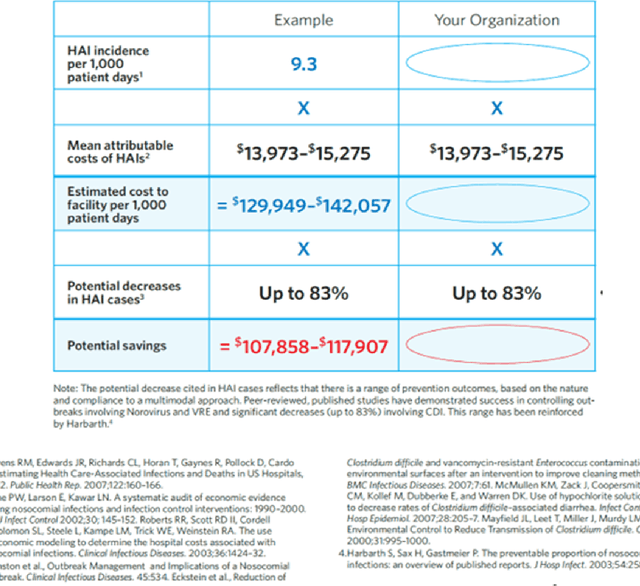

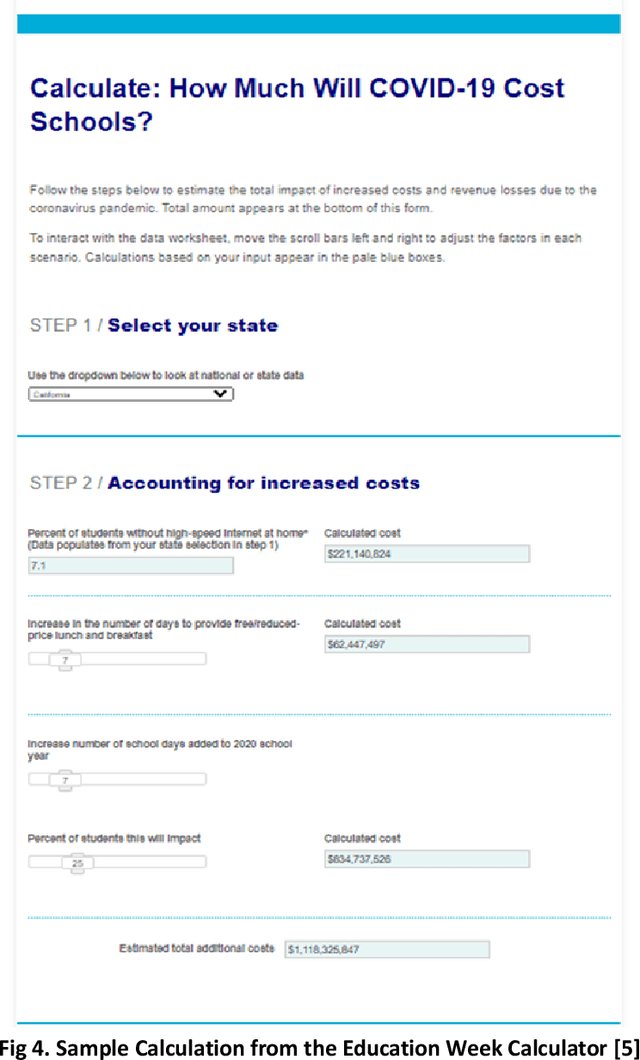
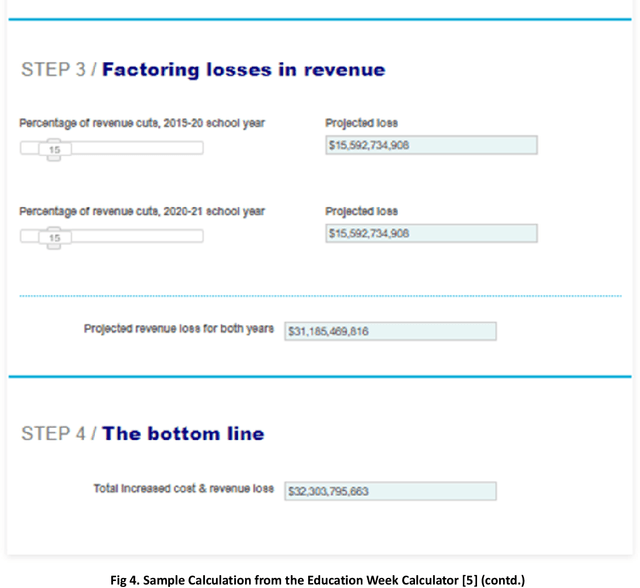
The COVID-19 pandemic has been a scourge upon humanity, claiming the lives of more than 5.1 million people worldwide; the global economy contracted by 3.5% in 2020. This paper presents a COVID-19 calculator, synthesizing existing published calculators and data points, to measure the positive U.S. socio-economic impact of a COVID-19 AI/ML pre-screening solution (algorithm & application).
Deep Recurrent NMF for Speech Separation by Unfolding Iterative Thresholding
Sep 21, 2017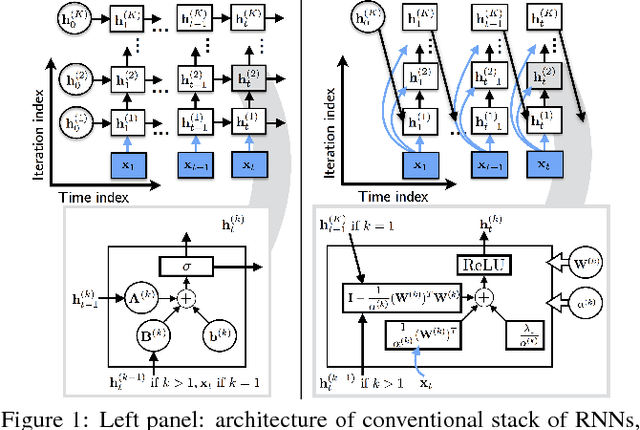
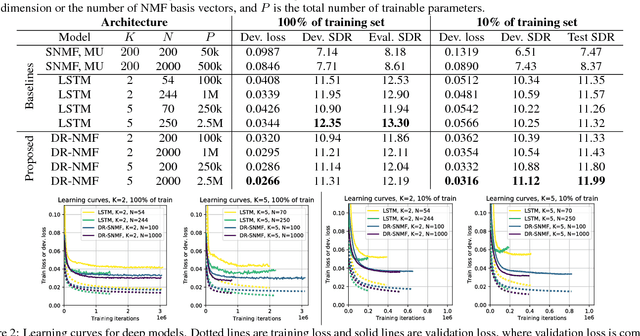
In this paper, we propose a novel recurrent neural network architecture for speech separation. This architecture is constructed by unfolding the iterations of a sequential iterative soft-thresholding algorithm (ISTA) that solves the optimization problem for sparse nonnegative matrix factorization (NMF) of spectrograms. We name this network architecture deep recurrent NMF (DR-NMF). The proposed DR-NMF network has three distinct advantages. First, DR-NMF provides better interpretability than other deep architectures, since the weights correspond to NMF model parameters, even after training. This interpretability also provides principled initializations that enable faster training and convergence to better solutions compared to conventional random initialization. Second, like many deep networks, DR-NMF is an order of magnitude faster at test time than NMF, since computation of the network output only requires evaluating a few layers at each time step. Third, when a limited amount of training data is available, DR-NMF exhibits stronger generalization and separation performance compared to sparse NMF and state-of-the-art long-short term memory (LSTM) networks. When a large amount of training data is available, DR-NMF achieves lower yet competitive separation performance compared to LSTM networks.
Interpretable Recurrent Neural Networks Using Sequential Sparse Recovery
Nov 22, 2016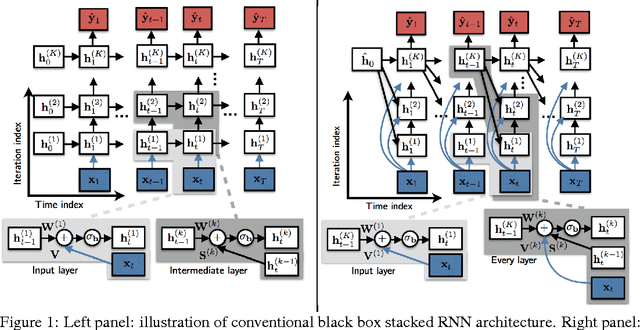
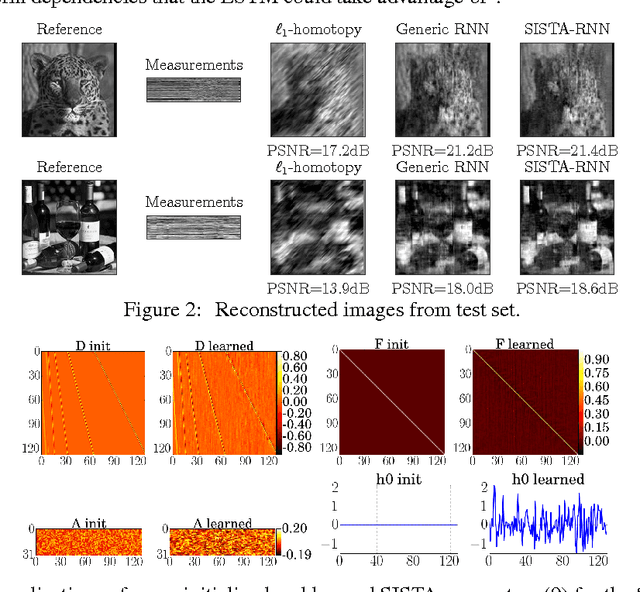
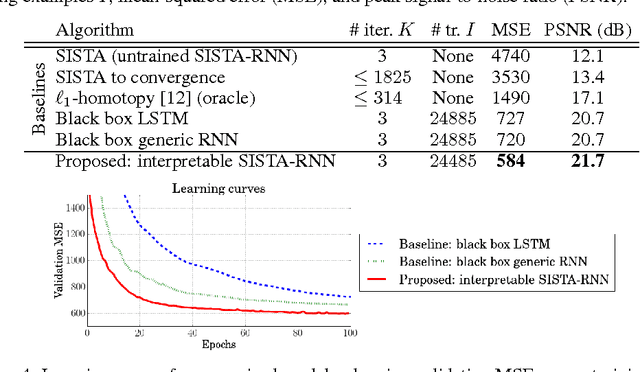
Recurrent neural networks (RNNs) are powerful and effective for processing sequential data. However, RNNs are usually considered "black box" models whose internal structure and learned parameters are not interpretable. In this paper, we propose an interpretable RNN based on the sequential iterative soft-thresholding algorithm (SISTA) for solving the sequential sparse recovery problem, which models a sequence of correlated observations with a sequence of sparse latent vectors. The architecture of the resulting SISTA-RNN is implicitly defined by the computational structure of SISTA, which results in a novel stacked RNN architecture. Furthermore, the weights of the SISTA-RNN are perfectly interpretable as the parameters of a principled statistical model, which in this case include a sparsifying dictionary, iterative step size, and regularization parameters. In addition, on a particular sequential compressive sensing task, the SISTA-RNN trains faster and achieves better performance than conventional state-of-the-art black box RNNs, including long-short term memory (LSTM) RNNs.
Full-Capacity Unitary Recurrent Neural Networks
Oct 31, 2016Recurrent neural networks are powerful models for processing sequential data, but they are generally plagued by vanishing and exploding gradient problems. Unitary recurrent neural networks (uRNNs), which use unitary recurrence matrices, have recently been proposed as a means to avoid these issues. However, in previous experiments, the recurrence matrices were restricted to be a product of parameterized unitary matrices, and an open question remains: when does such a parameterization fail to represent all unitary matrices, and how does this restricted representational capacity limit what can be learned? To address this question, we propose full-capacity uRNNs that optimize their recurrence matrix over all unitary matrices, leading to significantly improved performance over uRNNs that use a restricted-capacity recurrence matrix. Our contribution consists of two main components. First, we provide a theoretical argument to determine if a unitary parameterization has restricted capacity. Using this argument, we show that a recently proposed unitary parameterization has restricted capacity for hidden state dimension greater than 7. Second, we show how a complete, full-capacity unitary recurrence matrix can be optimized over the differentiable manifold of unitary matrices. The resulting multiplicative gradient step is very simple and does not require gradient clipping or learning rate adaptation. We confirm the utility of our claims by empirically evaluating our new full-capacity uRNNs on both synthetic and natural data, achieving superior performance compared to both LSTMs and the original restricted-capacity uRNNs.
Enhancement and Recognition of Reverberant and Noisy Speech by Extending Its Coherence
Sep 02, 2015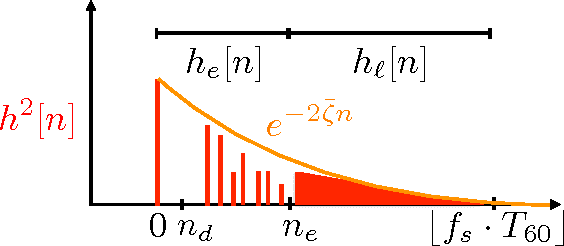
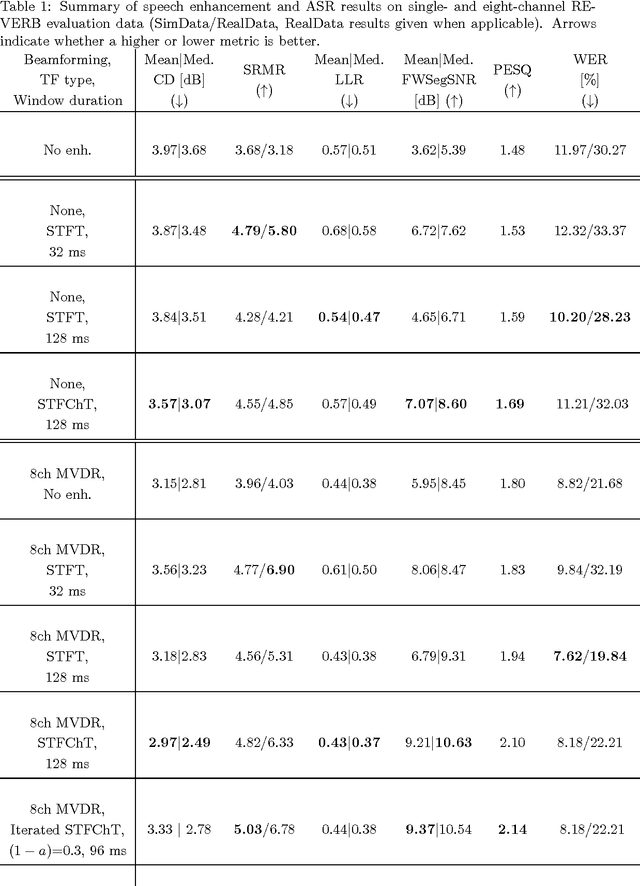
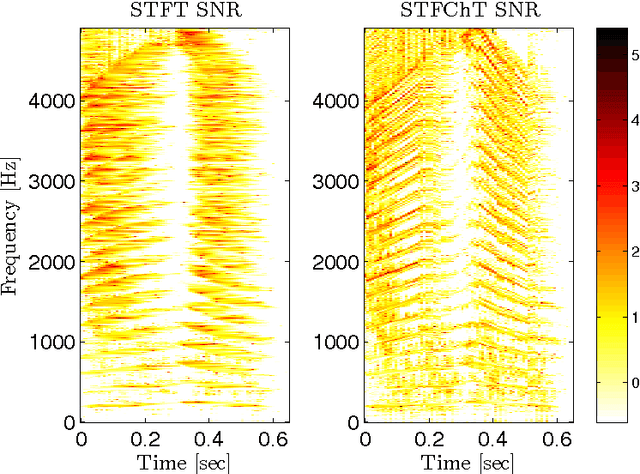
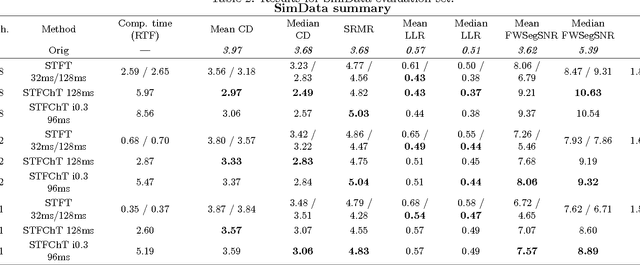
Most speech enhancement algorithms make use of the short-time Fourier transform (STFT), which is a simple and flexible time-frequency decomposition that estimates the short-time spectrum of a signal. However, the duration of short STFT frames are inherently limited by the nonstationarity of speech signals. The main contribution of this paper is a demonstration of speech enhancement and automatic speech recognition in the presence of reverberation and noise by extending the length of analysis windows. We accomplish this extension by performing enhancement in the short-time fan-chirp transform (STFChT) domain, an overcomplete time-frequency representation that is coherent with speech signals over longer analysis window durations than the STFT. This extended coherence is gained by using a linear model of fundamental frequency variation of voiced speech signals. Our approach centers around using a single-channel minimum mean-square error log-spectral amplitude (MMSE-LSA) estimator proposed by Habets, which scales coefficients in a time-frequency domain to suppress noise and reverberation. In the case of multiple microphones, we preprocess the data with either a minimum variance distortionless response (MVDR) beamformer, or a delay-and-sum beamformer (DSB). We evaluate our algorithm on both speech enhancement and recognition tasks for the REVERB challenge dataset. Compared to the same processing done in the STFT domain, our approach achieves significant improvement in terms of objective enhancement metrics (including PESQ---the ITU-T standard measurement for speech quality). In terms of automatic speech recognition (ASR) performance as measured by word error rate (WER), our experiments indicate that the STFT with a long window is more effective for ASR.