 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTightly-Coupled, Speed-aided Monocular Visual-Inertial Localization in Topological Map
Nov 08, 2024



This paper proposes a novel algorithm for vehicle speed-aided monocular visual-inertial localization using a topological map. The proposed system aims to address the limitations of existing methods that rely heavily on expensive sensors like GPS and LiDAR by leveraging relatively inexpensive camera-based pose estimation. The topological map is generated offline from LiDAR point clouds and includes depth images, intensity images, and corresponding camera poses. This map is then used for real-time localization through correspondence matching between current camera images and the stored topological images. The system employs an Iterated Error State Kalman Filter (IESKF) for optimized pose estimation, incorporating correspondence among images and vehicle speed measurements to enhance accuracy. Experimental results using both open dataset and our collected data in challenging scenario, such as tunnel, demonstrate the proposed algorithm's superior performance in topological map generation and localization tasks.
3D Semantic Segmentation-Driven Representations for 3D Object Detection
Mar 11, 2024In autonomous driving, 3D detection provides more precise information to downstream tasks, including path planning and motion estimation, compared to 2D detection. Therefore, the need for 3D detection research has emerged. However, although single and multi-view images and depth maps obtained from the camera were used, detection accuracy was relatively low compared to other modality-based detectors due to the lack of geometric information. The proposed multi-modal 3D object detection combines semantic features obtained from images and geometric features obtained from point clouds, but there are difficulties in defining unified representation to fuse data existing in different domains and synchronization between them. In this paper, we propose SeSame : point-wise semantic feature as a new presentation to ensure sufficient semantic information of the existing LiDAR-only based 3D detection. Experiments show that our approach outperforms previous state-of-the-art at different levels of difficulty in car and performance improvement on the KITTI object detection benchmark. Our code is available at https://github.com/HAMA-DL-dev/SeSame
Neural Motion Planning for Autonomous Parking
Nov 16, 2021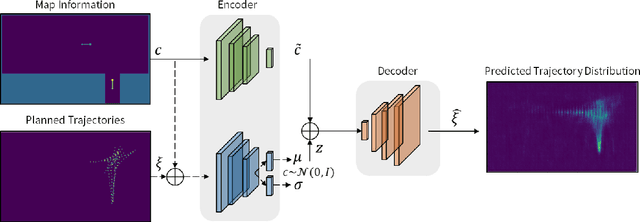
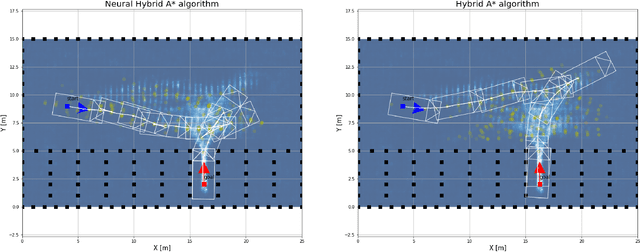
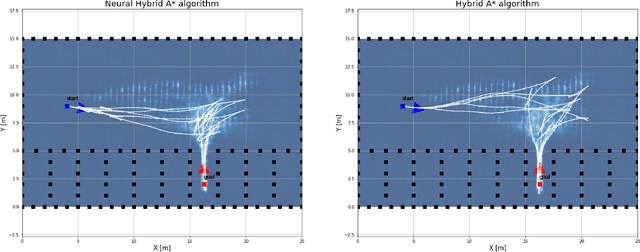
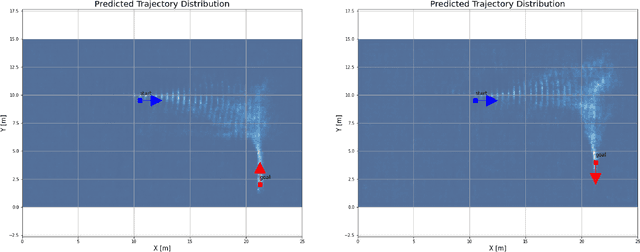
This paper presents a hybrid motion planning strategy that combines a deep generative network with a conventional motion planning method. Existing planning methods such as A* and Hybrid A* are widely used in path planning tasks because of their ability to determine feasible paths even in complex environments; however, they have limitations in terms of efficiency. To overcome these limitations, a path planning algorithm based on a neural network, namely the neural Hybrid A*, is introduced. This paper proposes using a conditional variational autoencoder (CVAE) to guide the search algorithm by exploiting the ability of CVAE to learn information about the planning space given the information of the parking environment. A non-uniform expansion strategy is utilized based on a distribution of feasible trajectories learned in the demonstrations. The proposed method effectively learns the representations of a given state, and shows improvement in terms of algorithm performance.
Multi-Head Attention based Probabilistic Vehicle Trajectory Prediction
Apr 20, 2020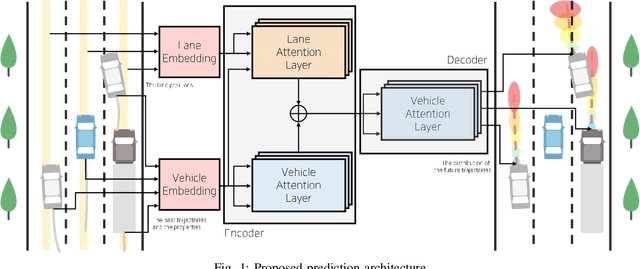
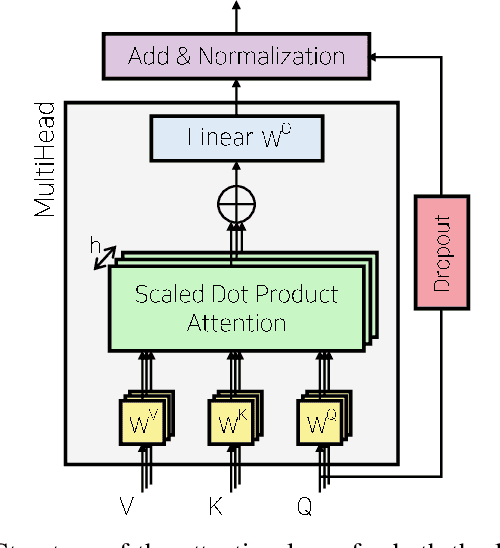

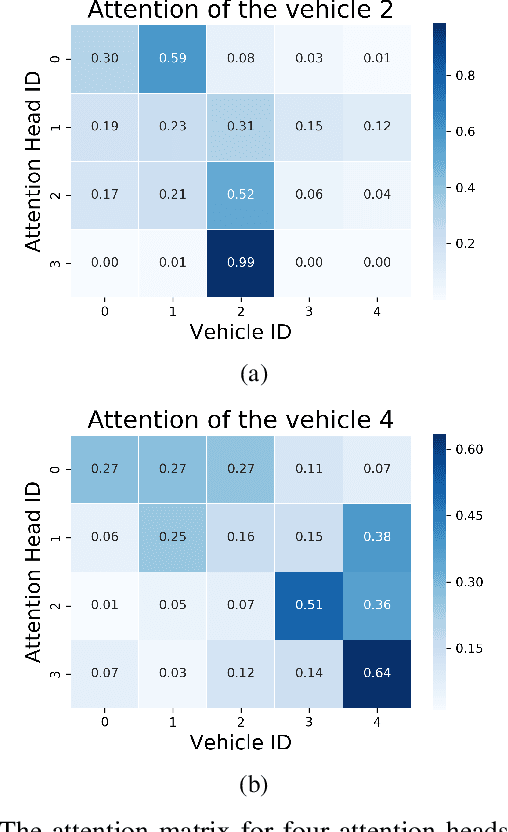
This paper presents online-capable deep learning model for probabilistic vehicle trajectory prediction. We propose a simple encoder-decoder architecture based on multi-head attention. The proposed model generates the distribution of the predicted trajectories for multiple vehicles in parallel. Our approach to model the interactions can learn to attend to a few influential vehicles in an unsupervised manner, which can improve the interpretability of the network. The experiments using naturalistic trajectories at highway show the clear improvement in terms of positional error on both longitudinal and lateral direction.