 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Detection and Root-Cause Analysis of Flaky Tests in Quantum Software
Mar 09, 2026Like classical software, quantum software systems rely on automated testing. However, their inherently probabilistic outputs make them susceptible to quantum flakiness -- tests that pass or fail inconsistently without code changes. Such quantum flaky tests can mask real defects and reduce developer productivity, yet systematic tooling for their detection and diagnosis remains limited. This paper presents an automated pipeline to detect flaky-test-related issues and pull requests in quantum software repositories and to support the identification of their root causes. We aim to expand an existing quantum flaky test dataset and evaluate the capability of Large Language Models (LLMs) for flakiness classification and root-cause identification. Building on a prior manual analysis of 14 quantum software repositories, we automate the discovery of additional flaky test cases using LLMs and cosine similarity. We further evaluate a variety of LLMs from OpenAI GPT, Meta LLaMA, Google Gemini, and Anthropic Claude suites for classifying flakiness and identifying root causes from issue descriptions and code context. Classification performance is assessed using standard performance metrics, including F1-score. Using our pipeline, we identify 25 previously unknown flaky tests, increasing the original dataset size by 54%. The best-performing model, Google Gemini, achieves an F1-score of 0.9420 for flakiness detection and 0.9643 for root-cause identification, demonstrating that LLMs can provide practical support for triaging flaky reports and understanding their underlying causes in quantum software. The expanded dataset and automated pipeline provide reusable artifacts for the quantum software engineering community. Future work will focus on improving detection robustness and exploring automated repair of quantum flaky tests.
Benchmarking Anomaly Detection Across Heterogeneous Cloud Telemetry Datasets
Feb 07, 2026Anomaly detection is important for keeping cloud systems reliable and stable. Deep learning has improved time-series anomaly detection, but most models are evaluated on one dataset at a time. This raises questions about whether these models can handle different types of telemetry, especially in large-scale and high-dimensional environments. In this study, we evaluate four deep learning models, GRU, TCN, Transformer, and TSMixer. We also include Isolation Forest as a classical baseline. The models are tested across four telemetry datasets: the Numenta Anomaly Benchmark, Microsoft Cloud Monitoring dataset, Exathlon dataset, and IBM Console dataset. These datasets differ in structure, dimensionality, and labelling strategy. They include univariate time series, synthetic multivariate workloads, and real-world production telemetry with over 100,000 features. We use a unified training and evaluation pipeline across all datasets. The evaluation includes NAB-style metrics to capture early detection behaviour for datasets where anomalies persist over contiguous time intervals. This enables window-based scoring in settings where anomalies occur over contiguous time intervals, even when labels are recorded at the point level. The unified setup enables consistent analysis of model behaviour under shared scoring and calibration assumptions. Our results demonstrate that anomaly detection performance in cloud systems is governed not only by model architecture, but critically by calibration stability and feature-space geometry. By releasing our preprocessing pipelines, benchmark configuration, and evaluation artifacts, we aim to support reproducible and deployment-aware evaluation of anomaly detection systems for cloud environments.
On Sequence-to-Sequence Models for Automated Log Parsing
Feb 07, 2026Log parsing is a critical standard operating procedure in software systems, enabling monitoring, anomaly detection, and failure diagnosis. However, automated log parsing remains challenging due to heterogeneous log formats, distribution shifts between training and deployment data, and the brittleness of rule-based approaches. This study aims to systematically evaluate how sequence modelling architecture, representation choice, sequence length, and training data availability influence automated log parsing performance and computational cost. We conduct a controlled empirical study comparing four sequence modelling architectures: Transformer, Mamba state-space, monodirectional LSTM, and bidirectional LSTM models. In total, 396 models are trained across multiple dataset configurations and evaluated using relative Levenshtein edit distance with statistical significance testing. Transformer achieves the lowest mean relative edit distance (0.111), followed by Mamba (0.145), mono-LSTM (0.186), and bi-LSTM (0.265), where lower values are better. Mamba provides competitive accuracy with substantially lower computational cost. Character-level tokenization generally improves performance, sequence length has negligible practical impact on Transformer accuracy, and both Mamba and Transformer demonstrate stronger sample efficiency than recurrent models. Overall, Transformers reduce parsing error by 23.4%, while Mamba is a strong alternative under data or compute constraints. These results also clarify the roles of representation choice, sequence length, and sample efficiency, providing practical guidance for researchers and practitioners.
Assessing how hyperparameters impact Large Language Models' sarcasm detection performance
Apr 08, 2025Sarcasm detection is challenging for both humans and machines. This work explores how model characteristics impact sarcasm detection in OpenAI's GPT, and Meta's Llama-2 models, given their strong natural language understanding, and popularity. We evaluate fine-tuned and zero-shot models across various sizes, releases, and hyperparameters. Experiments were conducted on the political and balanced (pol-bal) portion of the popular Self-Annotated Reddit Corpus (SARC2.0) sarcasm dataset. Fine-tuned performance improves monotonically with model size within a model family, while hyperparameter tuning also impacts performance. In the fine-tuning scenario, full precision Llama-2-13b achieves state-of-the-art accuracy and $F_1$-score, both measured at 0.83, comparable to average human performance. In the zero-shot setting, one GPT-4 model achieves competitive performance to prior attempts, yielding an accuracy of 0.70 and an $F_1$-score of 0.75. Furthermore, a model's performance may increase or decline with each release, highlighting the need to reassess performance after each release.
Anomaly Detection in Large-Scale Cloud Systems: An Industry Case and Dataset
Nov 13, 2024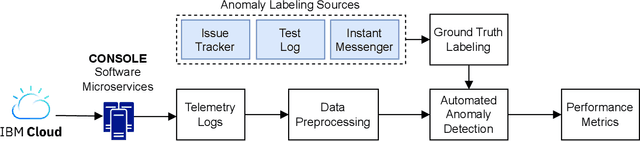
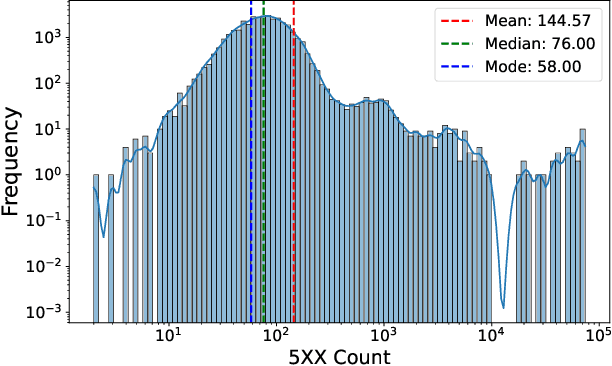
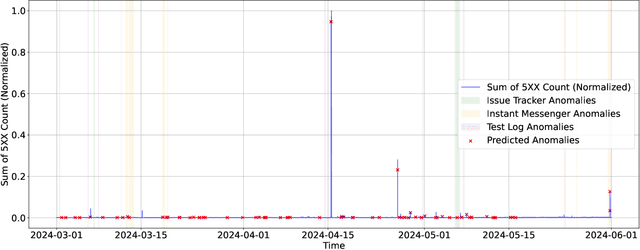
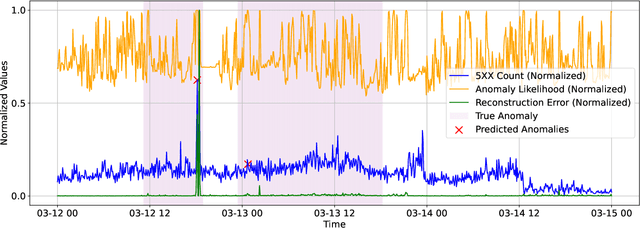
As Large-Scale Cloud Systems (LCS) become increasingly complex, effective anomaly detection is critical for ensuring system reliability and performance. However, there is a shortage of large-scale, real-world datasets available for benchmarking anomaly detection methods. To address this gap, we introduce a new high-dimensional dataset from IBM Cloud, collected over 4.5 months from the IBM Cloud Console. This dataset comprises 39,365 rows and 117,448 columns of telemetry data. Additionally, we demonstrate the application of machine learning models for anomaly detection and discuss the key challenges faced in this process. This study and the accompanying dataset provide a resource for researchers and practitioners in cloud system monitoring. It facilitates more efficient testing of anomaly detection methods in real-world data, helping to advance the development of robust solutions to maintain the health and performance of large-scale cloud infrastructures.
Automating Quantum Software Maintenance: Flakiness Detection and Root Cause Analysis
Oct 31, 2024Flaky tests, which pass or fail inconsistently without code changes, are a major challenge in software engineering in general and in quantum software engineering in particular due to their complexity and probabilistic nature, leading to hidden issues and wasted developer effort. We aim to create an automated framework to detect flaky tests in quantum software and an extended dataset of quantum flaky tests, overcoming the limitations of manual methods. Building on prior manual analysis of 14 quantum software repositories, we expanded the dataset and automated flaky test detection using transformers and cosine similarity. We conducted experiments with Large Language Models (LLMs) from the OpenAI GPT and Meta LLaMA families to assess their ability to detect and classify flaky tests from code and issue descriptions. Embedding transformers proved effective: we identified 25 new flaky tests, expanding the dataset by 54%. Top LLMs achieved an F1-score of 0.8871 for flakiness detection but only 0.5839 for root cause identification. We introduced an automated flaky test detection framework using machine learning, showing promising results but highlighting the need for improved root cause detection and classification in large quantum codebases. Future work will focus on improving detection techniques and developing automatic flaky test fixes.
On Using Quasirandom Sequences in Machine Learning for Model Weight Initialization
Aug 05, 2024The effectiveness of training neural networks directly impacts computational costs, resource allocation, and model development timelines in machine learning applications. An optimizer's ability to train the model adequately (in terms of trained model performance) depends on the model's initial weights. Model weight initialization schemes use pseudorandom number generators (PRNGs) as a source of randomness. We investigate whether substituting PRNGs for low-discrepancy quasirandom number generators (QRNGs) -- namely Sobol' sequences -- as a source of randomness for initializers can improve model performance. We examine Multi-Layer Perceptrons (MLP), Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), and Transformer architectures trained on MNIST, CIFAR-10, and IMDB datasets using SGD and Adam optimizers. Our analysis uses ten initialization schemes: Glorot, He, Lecun (both Uniform and Normal); Orthogonal, Random Normal, Truncated Normal, and Random Uniform. Models with weights set using PRNG- and QRNG-based initializers are compared pairwise for each combination of dataset, architecture, optimizer, and initialization scheme. Our findings indicate that QRNG-based neural network initializers either reach a higher accuracy or achieve the same accuracy more quickly than PRNG-based initializers in 60% of the 120 experiments conducted. Thus, using QRNG-based initializers instead of PRNG-based initializers can speed up and improve model training.
On Sarcasm Detection with OpenAI GPT-based Models
Dec 07, 2023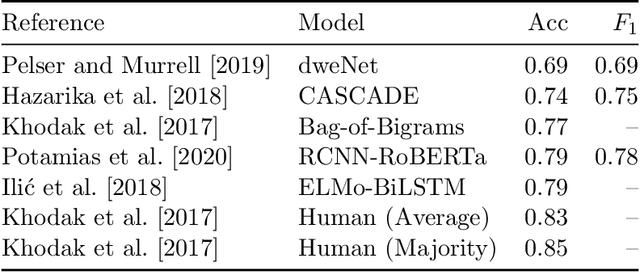

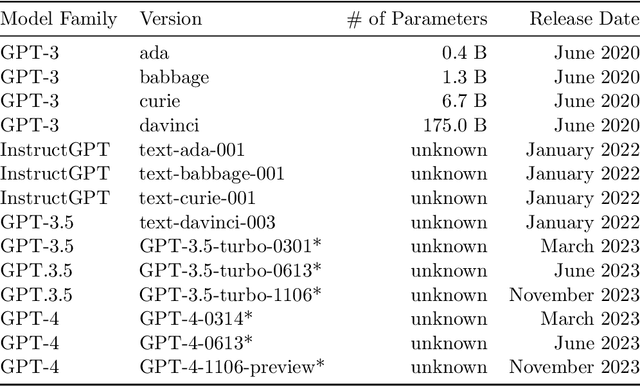

Sarcasm is a form of irony that requires readers or listeners to interpret its intended meaning by considering context and social cues. Machine learning classification models have long had difficulty detecting sarcasm due to its social complexity and contradictory nature. This paper explores the applications of the Generative Pretrained Transformer (GPT) models, including GPT-3, InstructGPT, GPT-3.5, and GPT-4, in detecting sarcasm in natural language. It tests fine-tuned and zero-shot models of different sizes and releases. The GPT models were tested on the political and balanced (pol-bal) portion of the popular Self-Annotated Reddit Corpus (SARC 2.0) sarcasm dataset. In the fine-tuning case, the largest fine-tuned GPT-3 model achieves accuracy and $F_1$-score of 0.81, outperforming prior models. In the zero-shot case, one of GPT-4 models yields an accuracy of 0.70 and $F_1$-score of 0.75. Other models score lower. Additionally, a model's performance may improve or deteriorate with each release, highlighting the need to reassess performance after each release.
EP-PQM: Efficient Parametric Probabilistic Quantum Memory with Fewer Qubits and Gates
Jan 10, 2022



Machine learning (ML) classification tasks can be carried out on a quantum computer (QC) using Probabilistic Quantum Memory (PQM) and its extension, Parameteric PQM (P-PQM) by calculating the Hamming distance between an input pattern and a database of $r$ patterns containing $z$ features with $a$ distinct attributes. For accurate computations, the feature must be encoded using one-hot encoding, which is memory-intensive for multi-attribute datasets with $a>2$. We can easily represent multi-attribute data more compactly on a classical computer by replacing one-hot encoding with label encoding. However, replacing these encoding schemes on a QC is not straightforward as PQM and P-PQM operate at the quantum bit level. We present an enhanced P-PQM, called EP-PQM, that allows label encoding of data stored in a PQM data structure and reduces the circuit depth of the data storage and retrieval procedures. We show implementations for an ideal QC and a noisy intermediate-scale quantum (NISQ) device. Our complexity analysis shows that the EP-PQM approach requires $O\left(z \log_2(a)\right)$ qubits as opposed to $O(za)$ qubits for P-PQM. EP-PQM also requires fewer gates, reducing gate count from $O\left(rza\right)$ to $O\left(rz\log_2(a)\right)$. For five datasets, we demonstrate that training an ML classification model using EP-PQM requires 48% to 77% fewer qubits than P-PQM for datasets with $a>2$. EP-PQM reduces circuit depth in the range of 60% to 96%, depending on the dataset. The depth decreases further with a decomposed circuit, ranging between 94% and 99%. EP-PQM requires less space; thus, it can train on and classify larger datasets than previous PQM implementations on NISQ devices. Furthermore, reducing the number of gates speeds up the classification and reduces the noise associated with deep quantum circuits. Thus, EP-PQM brings us closer to scalable ML on a NISQ device.
Term Interrelations and Trends in Software Engineering
Aug 21, 2021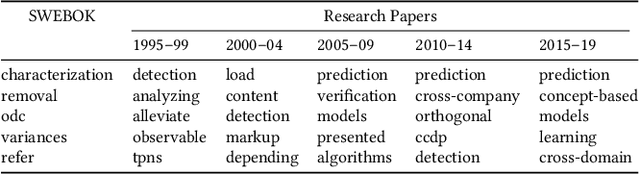
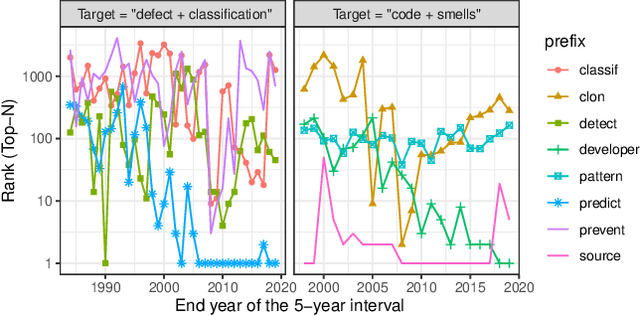
The Software Engineering (SE) community is prolific, making it challenging for experts to keep up with the flood of new papers and for neophytes to enter the field. Therefore, we posit that the community may benefit from a tool extracting terms and their interrelations from the SE community's text corpus and showing terms' trends. In this paper, we build a prototyping tool using the word embedding technique. We train the embeddings on the SE Body of Knowledge handbook and 15,233 research papers' titles and abstracts. We also create test cases necessary for validation of the training of the embeddings. We provide representative examples showing that the embeddings may aid in summarizing terms and uncovering trends in the knowledge base.
* Shortened version appeared in proceedings of ESEC/FSE 2021