 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Cloud Security through Topic Modelling
May 01, 2025



Protecting cloud applications is crucial in an age where security constantly threatens the digital world. The inevitable cyber-attacks throughout the CI/CD pipeline make cloud security innovations necessary. This research is motivated by applying Natural Language Processing (NLP) methodologies, such as Topic Modelling, to analyse cloud security data and predict future attacks. This research aims to use topic modelling, specifically Latent Dirichlet Allocation (LDA) and Probabilistic Latent Semantic Analysis (pLSA). Utilising LDA and PLSA, security-related text data, such as reports, logs, and other relevant documents, will be analysed and sorted into relevant topics (such as phishing or encryption). These algorithms may apply through Python using the Gensim framework. The topics shall be utilised to detect vulnerabilities within relevant CI/CD pipeline records or log data. This application of Topic Modelling anticipates providing a new form of vulnerability detection, improving overall security throughout the CI/CD pipeline.
Anomaly Detection in Large-Scale Cloud Systems: An Industry Case and Dataset
Nov 13, 2024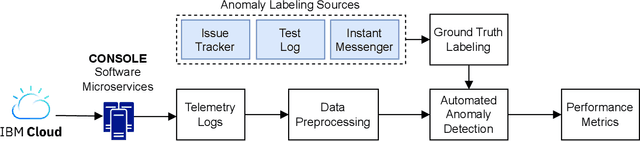
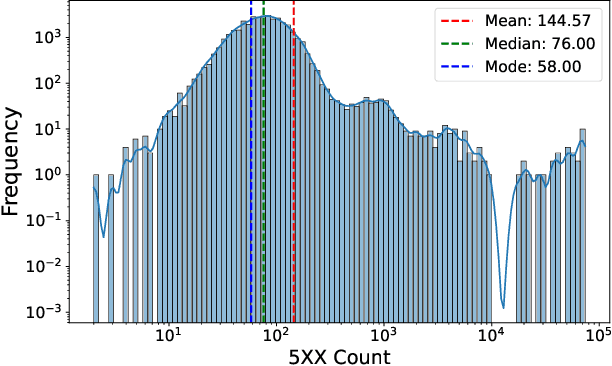
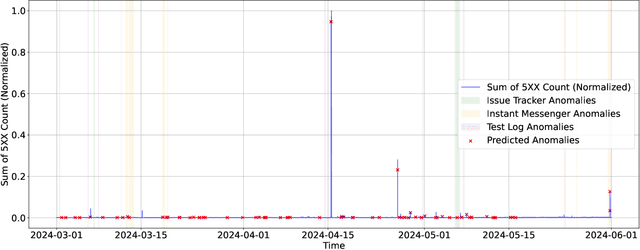
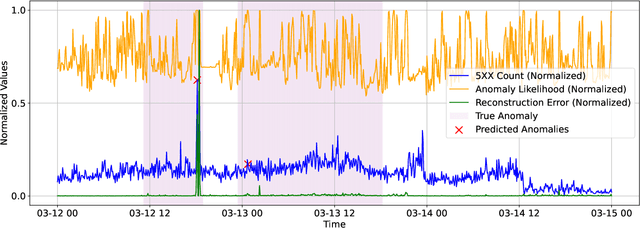
As Large-Scale Cloud Systems (LCS) become increasingly complex, effective anomaly detection is critical for ensuring system reliability and performance. However, there is a shortage of large-scale, real-world datasets available for benchmarking anomaly detection methods. To address this gap, we introduce a new high-dimensional dataset from IBM Cloud, collected over 4.5 months from the IBM Cloud Console. This dataset comprises 39,365 rows and 117,448 columns of telemetry data. Additionally, we demonstrate the application of machine learning models for anomaly detection and discuss the key challenges faced in this process. This study and the accompanying dataset provide a resource for researchers and practitioners in cloud system monitoring. It facilitates more efficient testing of anomaly detection methods in real-world data, helping to advance the development of robust solutions to maintain the health and performance of large-scale cloud infrastructures.
Attention is Not Always What You Need: Towards Efficient Classification of Domain-Specific Text
Mar 31, 2023For large-scale IT corpora with hundreds of classes organized in a hierarchy, the task of accurate classification of classes at the higher level in the hierarchies is crucial to avoid errors propagating to the lower levels. In the business world, an efficient and explainable ML model is preferred over an expensive black-box model, especially if the performance increase is marginal. A current trend in the Natural Language Processing (NLP) community is towards employing huge pre-trained language models (PLMs) or what is known as self-attention models (e.g., BERT) for almost any kind of NLP task (e.g., question-answering, sentiment analysis, text classification). Despite the widespread use of PLMs and the impressive performance in a broad range of NLP tasks, there is a lack of a clear and well-justified need to as why these models are being employed for domain-specific text classification (TC) tasks, given the monosemic nature of specialized words (i.e., jargon) found in domain-specific text which renders the purpose of contextualized embeddings (e.g., PLMs) futile. In this paper, we compare the accuracies of some state-of-the-art (SOTA) models reported in the literature against a Linear SVM classifier and TFIDF vectorization model on three TC datasets. Results show a comparable performance for the LinearSVM. The findings of this study show that for domain-specific TC tasks, a linear model can provide a comparable, cheap, reproducible, and interpretable alternative to attention-based models.
A Comparison of SVM against Pre-trained Language Models for Text Classification Tasks
Nov 04, 2022


The emergence of pre-trained language models (PLMs) has shown great success in many Natural Language Processing (NLP) tasks including text classification. Due to the minimal to no feature engineering required when using these models, PLMs are becoming the de facto choice for any NLP task. However, for domain-specific corpora (e.g., financial, legal, and industrial), fine-tuning a pre-trained model for a specific task has shown to provide a performance improvement. In this paper, we compare the performance of four different PLMs on three public domain-free datasets and a real-world dataset containing domain-specific words, against a simple SVM linear classifier with TFIDF vectorized text. The experimental results on the four datasets show that using PLMs, even fine-tuned, do not provide significant gain over the linear SVM classifier. Hence, we recommend that for text classification tasks, traditional SVM along with careful feature engineering can pro-vide a cheaper and superior performance than PLMs.
Anomaly Detection in a Large-scale Cloud Platform
Oct 21, 2020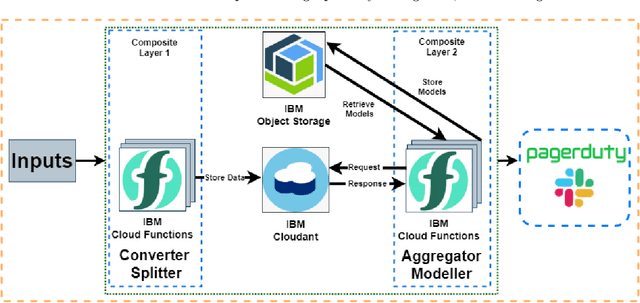
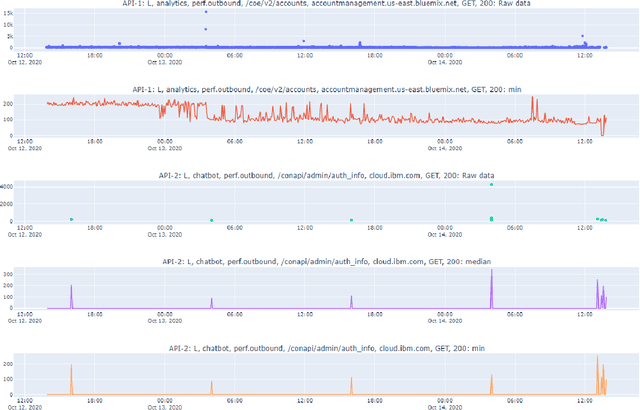
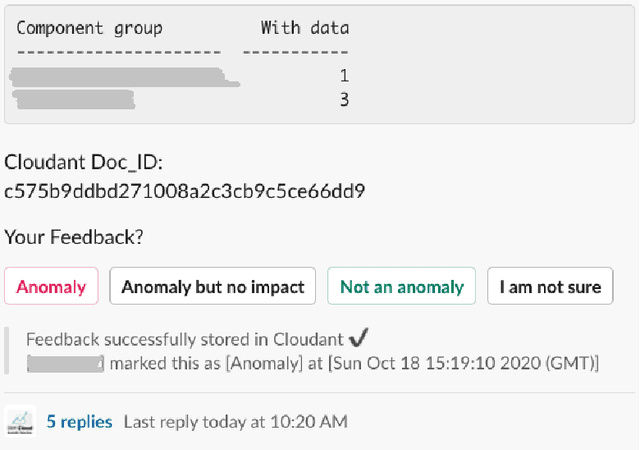
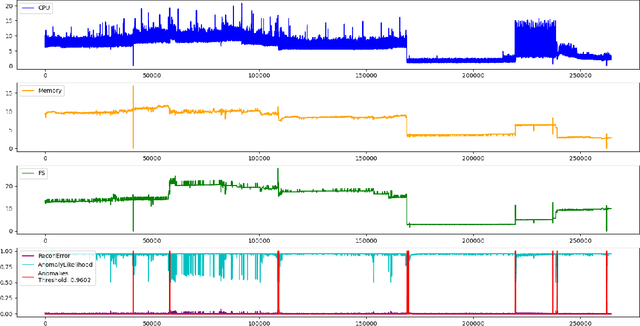
Cloud computing is ubiquitous: more and more companies are moving the workloads into the Cloud. However, this rise in popularity challenges Cloud service providers, as they need to monitor the quality of their ever-growing offerings effectively. To address the challenge, we designed and implemented an automated monitoring system for the IBM Cloud Platform. This monitoring system utilizes deep learning neural networks to detect anomalies in near-real-time in multiple Platform components simultaneously. After running the system for a year, we observed that the proposed solution frees the DevOps team's time and human resources from manually monitoring thousands of Cloud components. Moreover, it increases customer satisfaction by reducing the risk of Cloud outages. In this paper, we share our solutions' architecture, implementation notes, and best practices that emerged while evolving the monitoring system. They can be leveraged by other researchers and practitioners to build anomaly detectors for complex systems.