 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Anomaly Detection Across Heterogeneous Cloud Telemetry Datasets
Feb 07, 2026Anomaly detection is important for keeping cloud systems reliable and stable. Deep learning has improved time-series anomaly detection, but most models are evaluated on one dataset at a time. This raises questions about whether these models can handle different types of telemetry, especially in large-scale and high-dimensional environments. In this study, we evaluate four deep learning models, GRU, TCN, Transformer, and TSMixer. We also include Isolation Forest as a classical baseline. The models are tested across four telemetry datasets: the Numenta Anomaly Benchmark, Microsoft Cloud Monitoring dataset, Exathlon dataset, and IBM Console dataset. These datasets differ in structure, dimensionality, and labelling strategy. They include univariate time series, synthetic multivariate workloads, and real-world production telemetry with over 100,000 features. We use a unified training and evaluation pipeline across all datasets. The evaluation includes NAB-style metrics to capture early detection behaviour for datasets where anomalies persist over contiguous time intervals. This enables window-based scoring in settings where anomalies occur over contiguous time intervals, even when labels are recorded at the point level. The unified setup enables consistent analysis of model behaviour under shared scoring and calibration assumptions. Our results demonstrate that anomaly detection performance in cloud systems is governed not only by model architecture, but critically by calibration stability and feature-space geometry. By releasing our preprocessing pipelines, benchmark configuration, and evaluation artifacts, we aim to support reproducible and deployment-aware evaluation of anomaly detection systems for cloud environments.
Anomaly Detection in Large-Scale Cloud Systems: An Industry Case and Dataset
Nov 13, 2024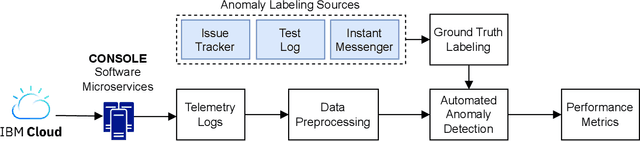
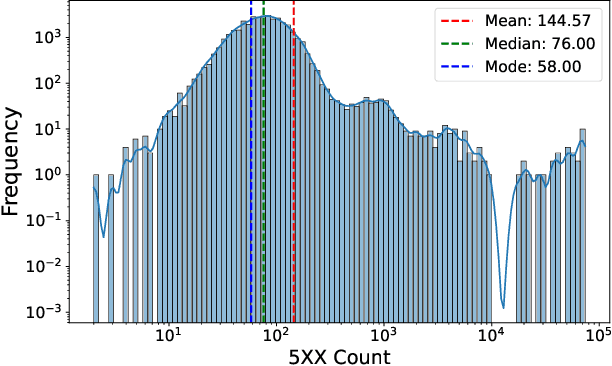
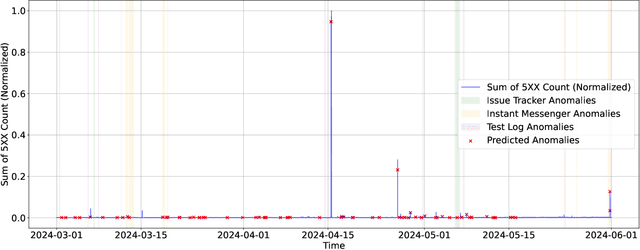
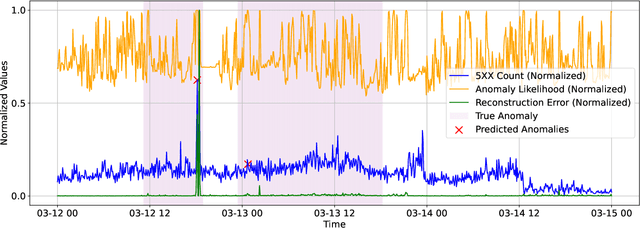
As Large-Scale Cloud Systems (LCS) become increasingly complex, effective anomaly detection is critical for ensuring system reliability and performance. However, there is a shortage of large-scale, real-world datasets available for benchmarking anomaly detection methods. To address this gap, we introduce a new high-dimensional dataset from IBM Cloud, collected over 4.5 months from the IBM Cloud Console. This dataset comprises 39,365 rows and 117,448 columns of telemetry data. Additionally, we demonstrate the application of machine learning models for anomaly detection and discuss the key challenges faced in this process. This study and the accompanying dataset provide a resource for researchers and practitioners in cloud system monitoring. It facilitates more efficient testing of anomaly detection methods in real-world data, helping to advance the development of robust solutions to maintain the health and performance of large-scale cloud infrastructures.
Anomaly Detection in a Large-scale Cloud Platform
Oct 21, 2020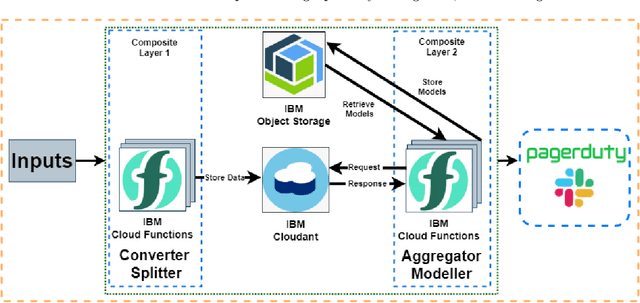
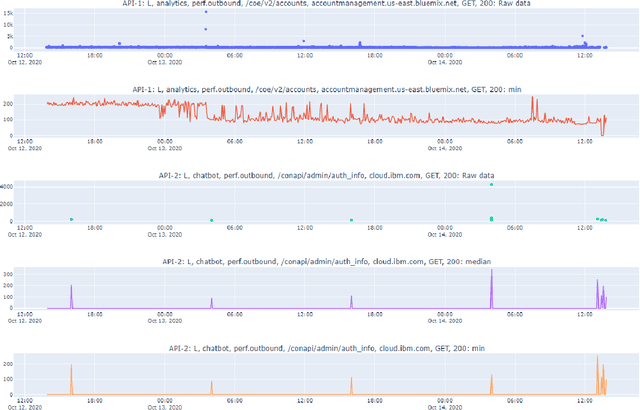
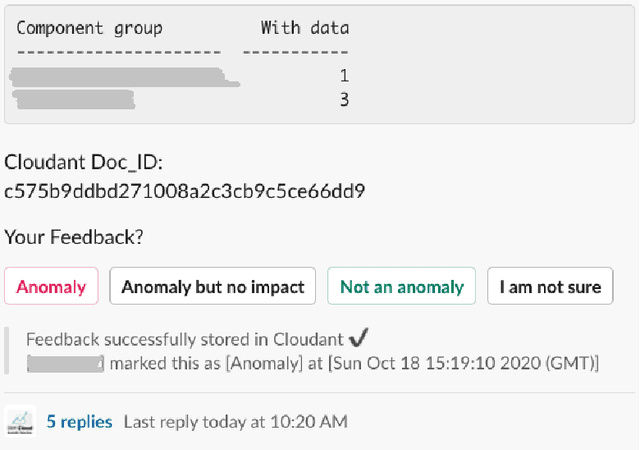
Cloud computing is ubiquitous: more and more companies are moving the workloads into the Cloud. However, this rise in popularity challenges Cloud service providers, as they need to monitor the quality of their ever-growing offerings effectively. To address the challenge, we designed and implemented an automated monitoring system for the IBM Cloud Platform. This monitoring system utilizes deep learning neural networks to detect anomalies in near-real-time in multiple Platform components simultaneously. After running the system for a year, we observed that the proposed solution frees the DevOps team's time and human resources from manually monitoring thousands of Cloud components. Moreover, it increases customer satisfaction by reducing the risk of Cloud outages. In this paper, we share our solutions' architecture, implementation notes, and best practices that emerged while evolving the monitoring system. They can be leveraged by other researchers and practitioners to build anomaly detectors for complex systems.
Anomaly Detection in Cloud Components
May 18, 2020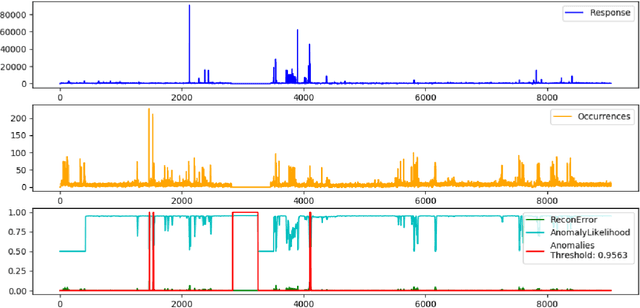
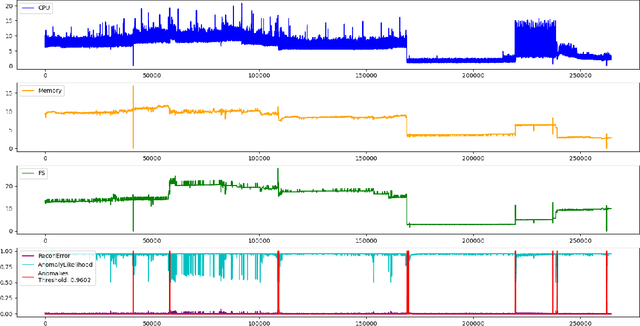
Cloud platforms, under the hood, consist of a complex inter-connected stack of hardware and software components. Each of these components can fail which may lead to an outage. Our goal is to improve the quality of Cloud services through early detection of such failures by analyzing resource utilization metrics. We tested Gated-Recurrent-Unit-based autoencoder with a likelihood function to detect anomalies in various multi-dimensional time series and achieved high performance.