 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in a Large-scale Cloud Platform
Oct 21, 2020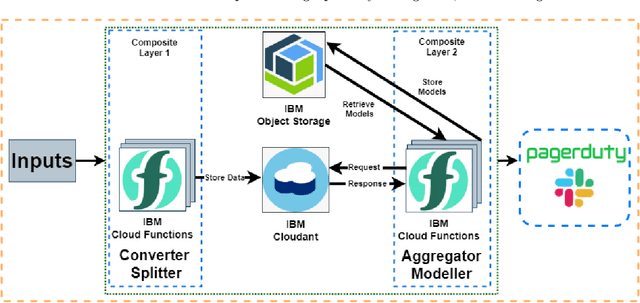
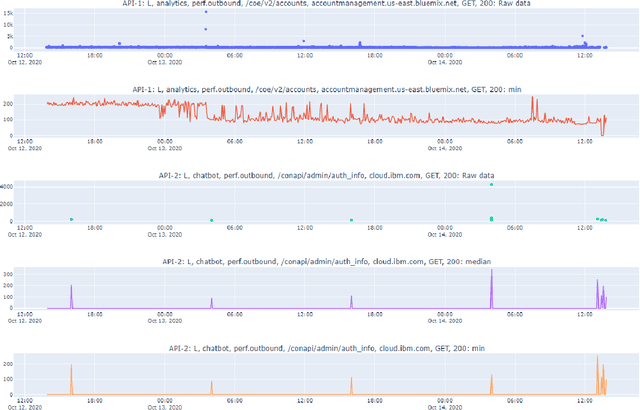
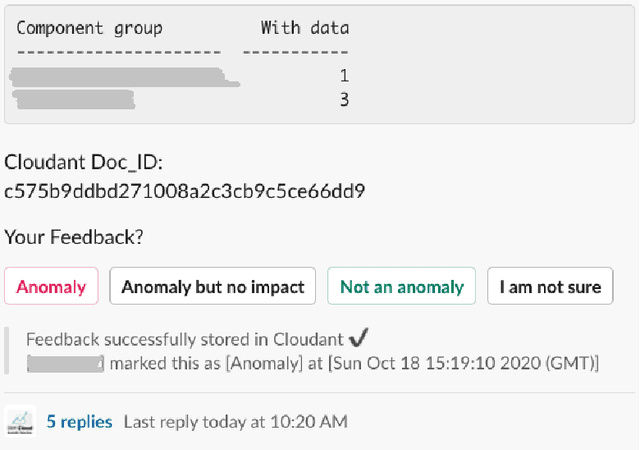
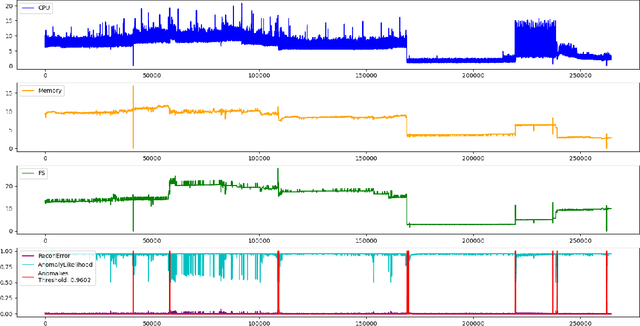
Cloud computing is ubiquitous: more and more companies are moving the workloads into the Cloud. However, this rise in popularity challenges Cloud service providers, as they need to monitor the quality of their ever-growing offerings effectively. To address the challenge, we designed and implemented an automated monitoring system for the IBM Cloud Platform. This monitoring system utilizes deep learning neural networks to detect anomalies in near-real-time in multiple Platform components simultaneously. After running the system for a year, we observed that the proposed solution frees the DevOps team's time and human resources from manually monitoring thousands of Cloud components. Moreover, it increases customer satisfaction by reducing the risk of Cloud outages. In this paper, we share our solutions' architecture, implementation notes, and best practices that emerged while evolving the monitoring system. They can be leveraged by other researchers and practitioners to build anomaly detectors for complex systems.