Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerm Interrelations and Trends in Software Engineering
Aug 21, 2021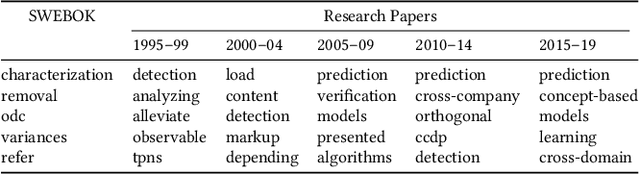
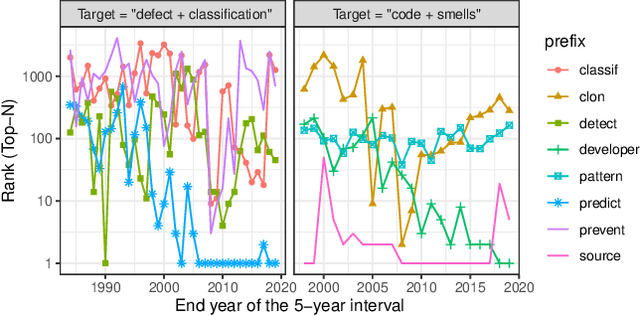
The Software Engineering (SE) community is prolific, making it challenging for experts to keep up with the flood of new papers and for neophytes to enter the field. Therefore, we posit that the community may benefit from a tool extracting terms and their interrelations from the SE community's text corpus and showing terms' trends. In this paper, we build a prototyping tool using the word embedding technique. We train the embeddings on the SE Body of Knowledge handbook and 15,233 research papers' titles and abstracts. We also create test cases necessary for validation of the training of the embeddings. We provide representative examples showing that the embeddings may aid in summarizing terms and uncovering trends in the knowledge base.
* In Proceedings of the 29th ACM Joint Meeting on European Software
Engineering Conference and Symposium on the Foundations of Software
Engineering (ESEC/FSE 2021), pp. 1471-1474
* Shortened version appeared in proceedings of ESEC/FSE 2021
* Shortened version appeared in proceedings of ESEC/FSE 2021
Via