 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Evaluation of Medical Image Synthesis: A Case Study in Wireless Capsule Endoscopy
Oct 31, 2024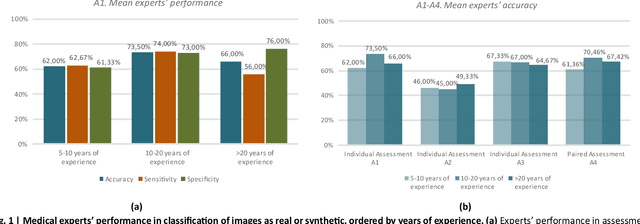

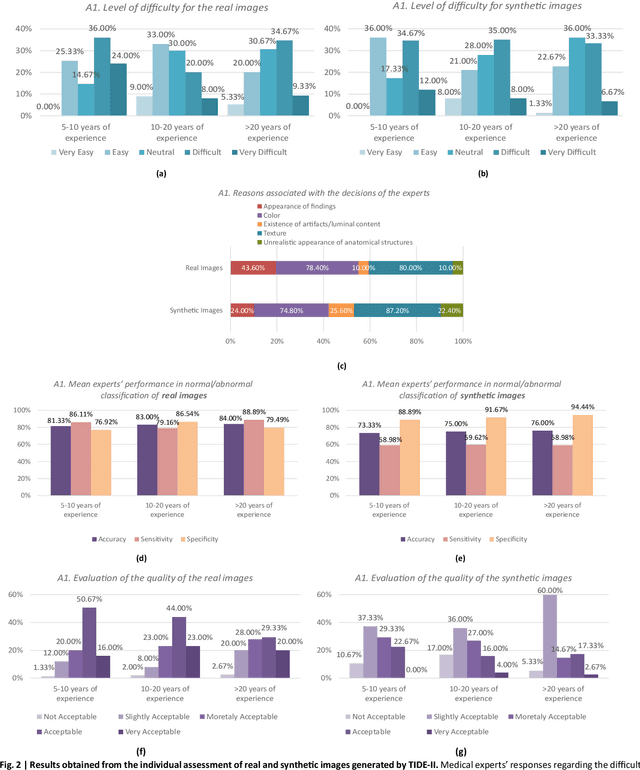

Sharing retrospectively acquired data is essential for both clinical research and training. Synthetic Data Generation (SDG), using Artificial Intelligence (AI) models, can overcome privacy barriers in sharing clinical data, enabling advancements in medical diagnostics. This study focuses on the clinical evaluation of medical SDG, with a proof-of-concept investigation on diagnosing Inflammatory Bowel Disease (IBD) using Wireless Capsule Endoscopy (WCE) images. The paper contributes by a) presenting a protocol for the systematic evaluation of synthetic images by medical experts and b) applying it to assess TIDE-II, a novel variational autoencoder-based model for high-resolution WCE image synthesis, with a comprehensive qualitative evaluation conducted by 10 international WCE specialists, focusing on image quality, diversity, realism, and clinical decision-making. The results show that TIDE-II generates clinically relevant WCE images, helping to address data scarcity and enhance diagnostic tools. The proposed protocol serves as a reference for future research on medical image-generation techniques.
Black or White but never neutral: How readers perceive identity from yellow or skin-toned emoji
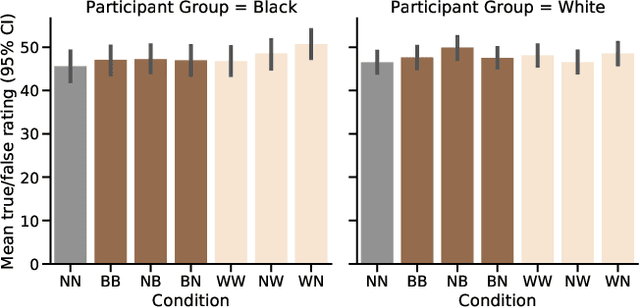
May 12, 2021Research in sociology and linguistics shows that people use language not only to express their own identity but to understand the identity of others. Recent work established a connection between expression of identity and emoji usage on social media, through use of emoji skin tone modifiers. Motivated by that finding, this work asks if, as with language, readers are sensitive to such acts of self-expression and use them to understand the identity of authors. In behavioral experiments (n=488), where text and emoji content of social media posts were carefully controlled before being presented to participants, we find in the affirmative -- emoji are a salient signal of author identity. That signal is distinct from, and complementary to, the one encoded in language. Participant groups (based on self-identified ethnicity) showed no differences in how they perceive this signal, except in the case of the default yellow emoji. While both groups associate this with a White identity, the effect was stronger in White participants. Our finding that emoji can index social variables will have experimental applications for researchers but also implications for designers: supposedly ``neutral`` defaults may be more representative of some users than others.
Identity Signals in Emoji Do not Influence Perception of Factual Truth on Twitter
May 07, 2021
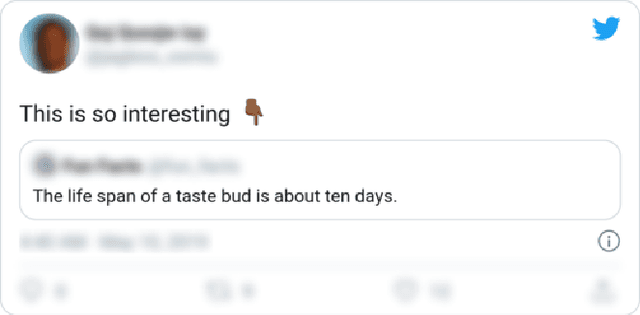
Prior work has shown that Twitter users use skin-toned emoji as an act of self-representation to express their racial/ethnic identity. We test whether this signal of identity can influence readers' perceptions about the content of a post containing that signal. In a large scale (n=944) pre-registered controlled experiment, we manipulate the presence of skin-toned emoji and profile photos in a task where readers rate obscure trivia facts (presented as tweets) as true or false. Using a Bayesian statistical analysis, we find that neither emoji nor profile photo has an effect on how readers rate these facts. This result will be of some comfort to anyone concerned about the manipulation of online users through the crafting of fake profiles.
Semantic Journeys: Quantifying Change in Emoji Meaning from 2012-2018
May 04, 2021



The semantics of emoji has, to date, been considered from a static perspective. We offer the first longitudinal study of how emoji semantics changes over time, applying techniques from computational linguistics to six years of Twitter data. We identify five patterns in emoji semantic development and find evidence that the less abstract an emoji is, the more likely it is to undergo semantic change. In addition, we analyse select emoji in more detail, examining the effect of seasonality and world events on emoji semantics. To aid future work on emoji and semantics, we make our data publicly available along with a web-based interface that anyone can use to explore semantic change in emoji.
Scaling Systematic Literature Reviews with Machine Learning Pipelines
Oct 09, 2020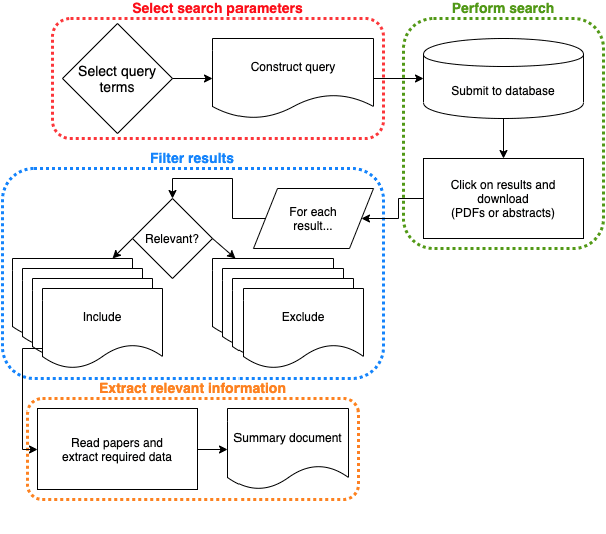
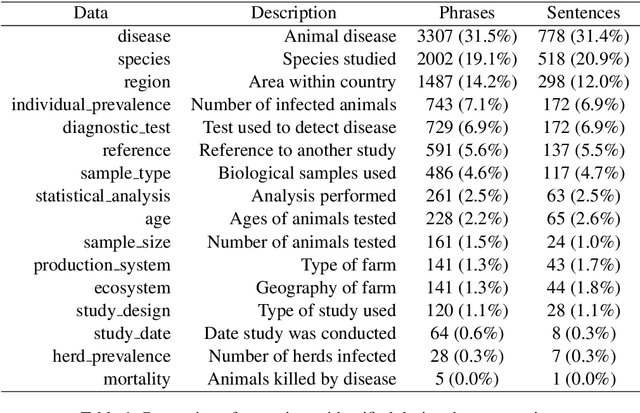
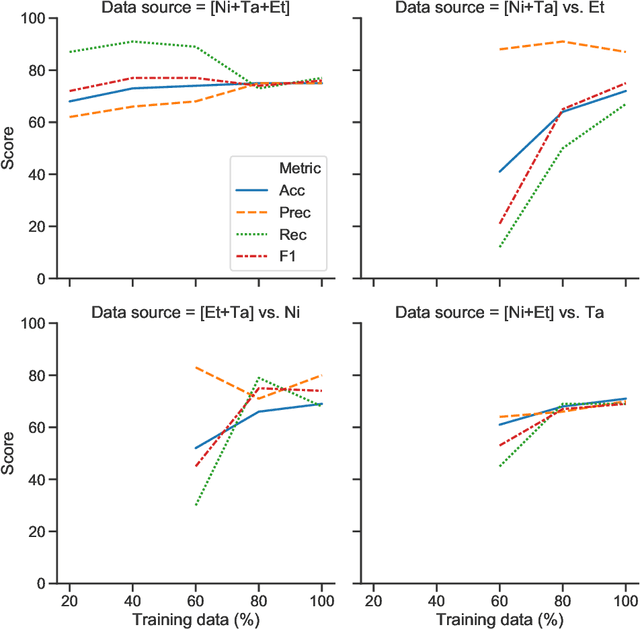
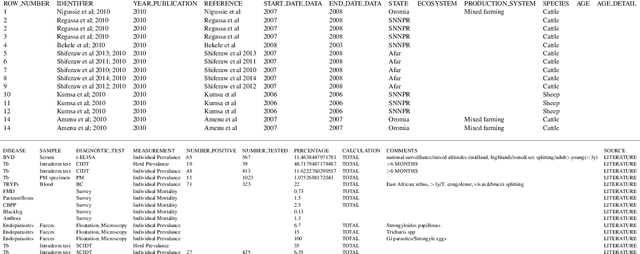
Systematic reviews, which entail the extraction of data from large numbers of scientific documents, are an ideal avenue for the application of machine learning. They are vital to many fields of science and philanthropy, but are very time-consuming and require experts. Yet the three main stages of a systematic review are easily done automatically: searching for documents can be done via APIs and scrapers, selection of relevant documents can be done via binary classification, and extraction of data can be done via sequence-labelling classification. Despite the promise of automation for this field, little research exists that examines the various ways to automate each of these tasks. We construct a pipeline that automates each of these aspects, and experiment with many human-time vs. system quality trade-offs. We test the ability of classifiers to work well on small amounts of data and to generalise to data from countries not represented in the training data. We test different types of data extraction with varying difficulty in annotation, and five different neural architectures to do the extraction. We find that we can get surprising accuracy and generalisability of the whole pipeline system with only 2 weeks of human-expert annotation, which is only 15% of the time it takes to do the whole review manually and can be repeated and extended to new data with no additional effort.
The Language of Dialogue Is Complex
Jun 05, 2019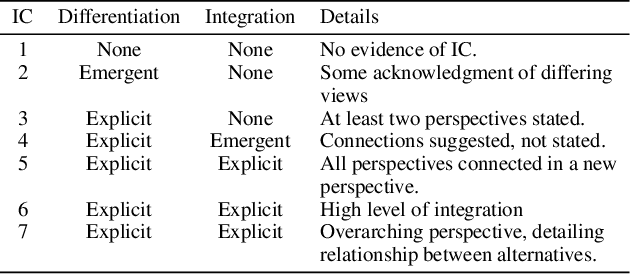
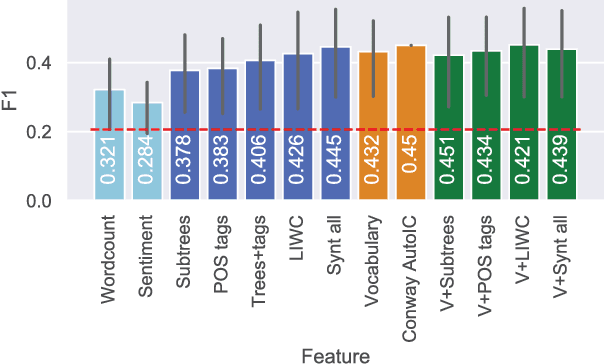
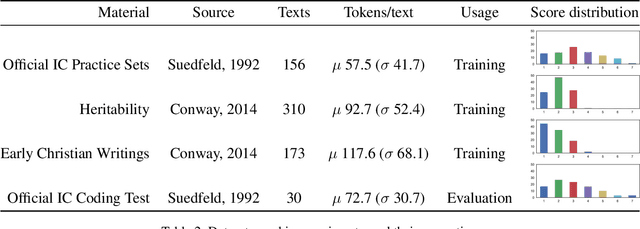
Integrative Complexity (IC) is a psychometric that measures the ability of a person to recognize multiple perspectives and connect them, thus identifying paths for conflict resolution. IC has been linked to a wide variety of political, social and personal outcomes but evaluating it is a time-consuming process requiring skilled professionals to manually score texts, a fact which accounts for the limited exploration of IC at scale on social media.We combine natural language processing and machine learning to train an IC classification model that achieves state-of-the-art performance on unseen data and more closely adheres to the established structure of the IC coding process than previous automated approaches. When applied to the content of 400k+ comments from online fora about depression and knowledge exchange, our model was capable of replicating key findings of prior work, thus providing the first example of using IC tools for large-scale social media analytics.
* 12 pages, 9 figures, 10 tables
Evaluating historical text normalization systems: How well do they generalize?
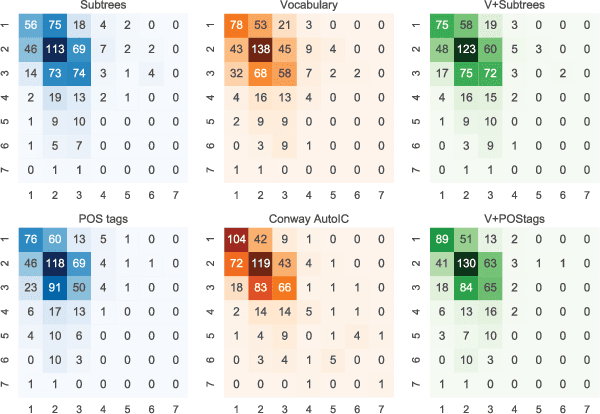
Apr 13, 2018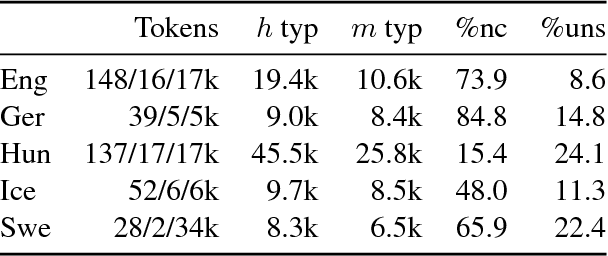
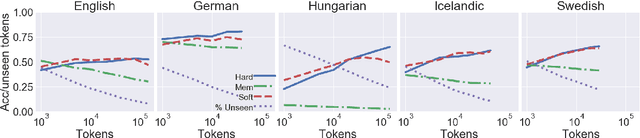
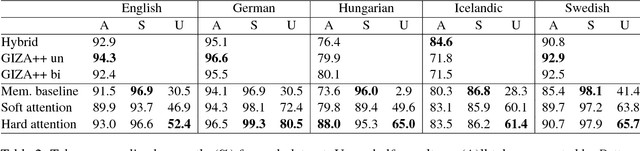
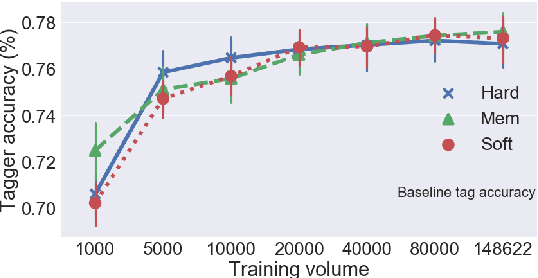
We highlight several issues in the evaluation of historical text normalization systems that make it hard to tell how well these systems would actually work in practice---i.e., for new datasets or languages; in comparison to more na\"ive systems; or as a preprocessing step for downstream NLP tools. We illustrate these issues and exemplify our proposed evaluation practices by comparing two neural models against a na\"ive baseline system. We show that the neural models generalize well to unseen words in tests on five languages; nevertheless, they provide no clear benefit over the na\"ive baseline for downstream POS tagging of an English historical collection. We conclude that future work should include more rigorous evaluation, including both intrinsic and extrinsic measures where possible.