 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cognitive Study on Semantic Similarity Analysis of Large Corpora: A Transformer-based Approach
Paper and Code
Jul 24, 2022

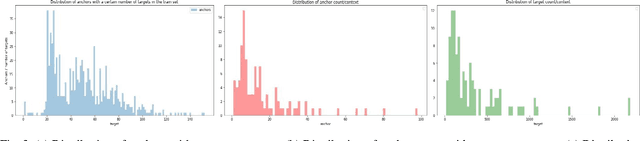
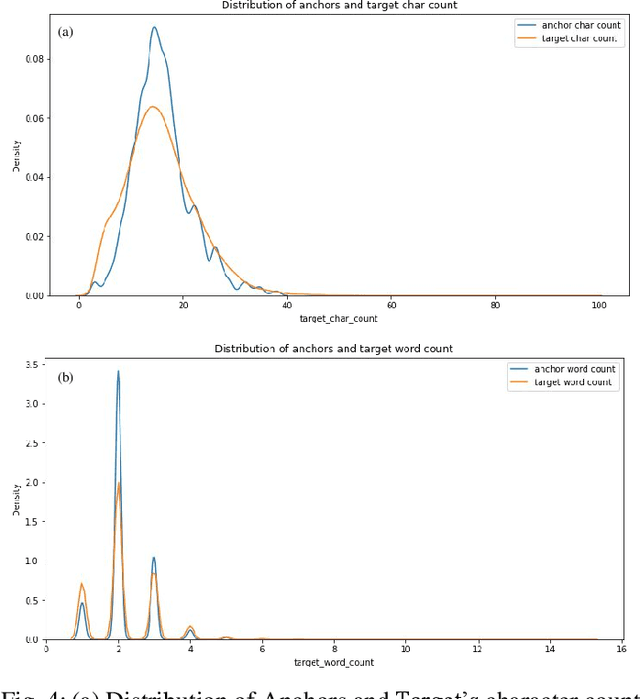
Semantic similarity analysis and modeling is a fundamentally acclaimed task in many pioneering applications of natural language processing today. Owing to the sensation of sequential pattern recognition, many neural networks like RNNs and LSTMs have achieved satisfactory results in semantic similarity modeling. However, these solutions are considered inefficient due to their inability to process information in a non-sequential manner, thus leading to the improper extraction of context. Transformers function as the state-of-the-art architecture due to their advantages like non-sequential data processing and self-attention. In this paper, we perform semantic similarity analysis and modeling on the U.S Patent Phrase to Phrase Matching Dataset using both traditional and transformer-based techniques. We experiment upon four different variants of the Decoding Enhanced BERT - DeBERTa and enhance its performance by performing K-Fold Cross-Validation. The experimental results demonstrate our methodology's enhanced performance compared to traditional techniques, with an average Pearson correlation score of 0.79.