 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Aware Speech Representation Learning For Language Identification
Paper and Code
Jun 07, 2023

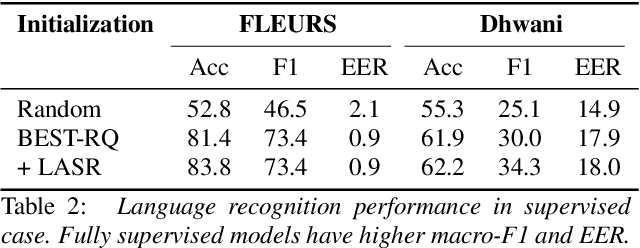

Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.