 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtom dimension adaptation for infinite set dictionary learning
Sep 10, 2024



Recent work on dictionary learning with set-atoms has shown benefits in anomaly detection. Instead of viewing an atom as a single vector, these methods allow building sparse representations with atoms taken from a set around a central vector; the set can be a cone or may have a probability distribution associated to it. We propose a method for adaptively adjusting the size of set-atoms in Gaussian and cone dictionary learning. The purpose of the algorithm is to match the atom sizes with their contribution in representing the signals. The proposed algorithm not only decreases the representation error, but also improves anomaly detection, for a class of anomalies called `dependency'. We obtain better detection performance than state-of-the-art methods.
"Vorbeşti Româneşte?" A Recipe to Train Powerful Romanian LLMs with English Instructions
Jun 26, 2024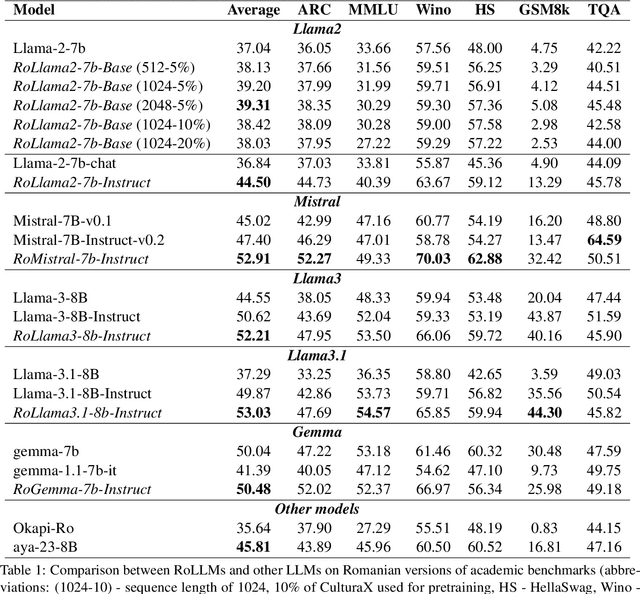
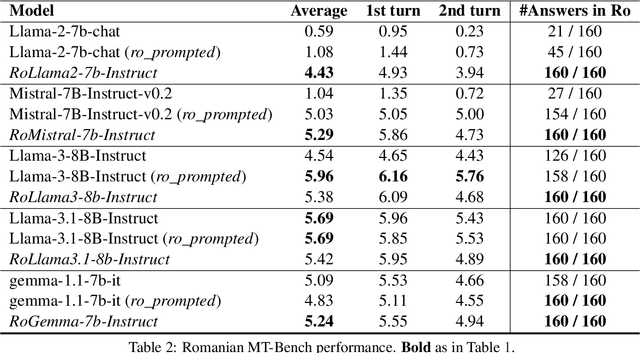
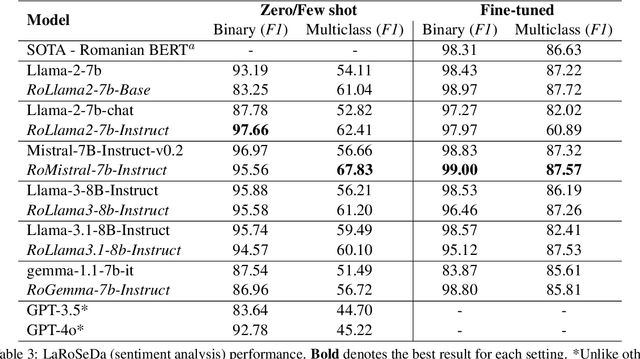
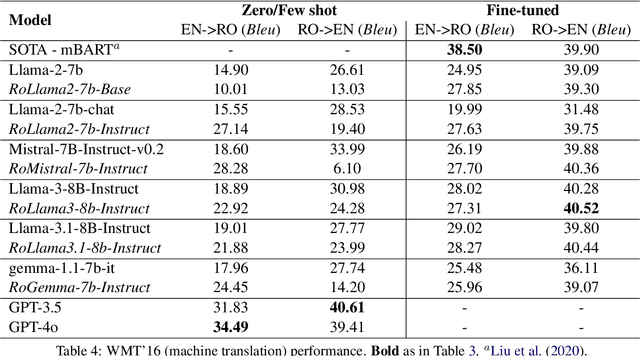
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English; hence, their performance in English greatly exceeds other languages. To our knowledge, we are the first to collect and translate a large collection of texts, instructions, and benchmarks and train, evaluate, and release open-source LLMs tailored for Romanian. We evaluate our methods on four different categories, including academic benchmarks, MT-Bench (manually translated), and a professionally built historical, cultural, and social benchmark adapted to Romanian. We argue for the usefulness and high performance of RoLLMs by obtaining state-of-the-art results across the board. We publicly release all resources (i.e., data, training and evaluation code, models) to support and encourage research on Romanian LLMs while concurrently creating a generalizable recipe, adequate for other low or less-resourced languages.
OpenLLM-Ro -- Technical Report on Open-source Romanian LLMs
May 17, 2024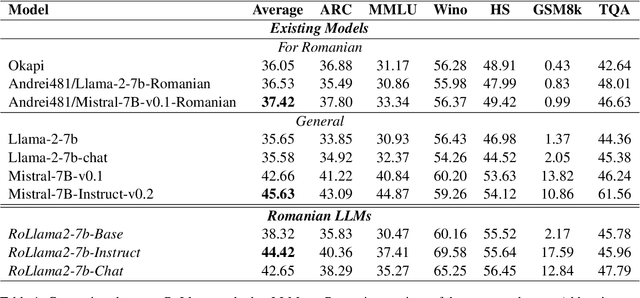

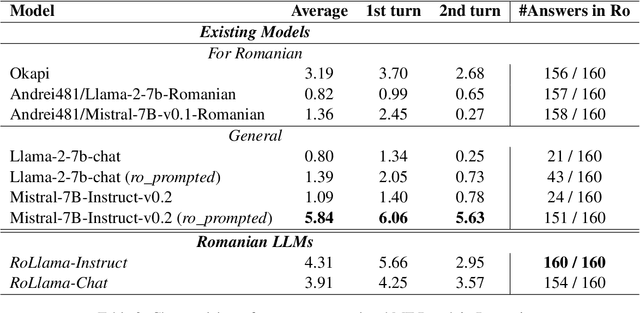
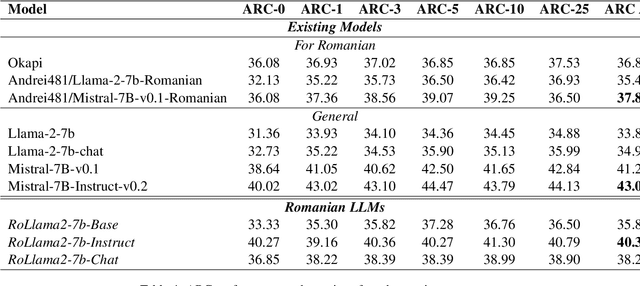
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English. Hence, their performance in English greatly exceeds their performance in other languages. This document presents our approach to training and evaluating the first foundational and chat LLM specialized for Romanian.
Classification with Incoherent Kernel Dictionary Learning
Jul 17, 2023In this paper we present a new classification method based on Dictionary Learning (DL). The main contribution consists of a kernel version of incoherent DL, derived from its standard linear counterpart. We also propose an improvement of the AK-SVD algorithm concerning the representation update. Our algorithms are tested on several popular databases of classification problems.
Anomaly Detection with Selective Dictionary Learning
Jul 17, 2023



In this paper we present new methods of anomaly detection based on Dictionary Learning (DL) and Kernel Dictionary Learning (KDL). The main contribution consists in the adaption of known DL and KDL algorithms in the form of unsupervised methods, used for outlier detection. We propose a reduced kernel version (RKDL), which is useful for problems with large data sets, due to the large kernel matrix. We also improve the DL and RKDL methods by the use of a random selection of signals, which aims to eliminate the outliers from the training procedure. All our algorithms are introduced in an anomaly detection toolbox and are compared to standard benchmark results.
Reduced Kernel Dictionary Learning
Jul 17, 2023



In this paper we present new algorithms for training reduced-size nonlinear representations in the Kernel Dictionary Learning (KDL) problem. Standard KDL has the drawback of a large size of the kernel matrix when the data set is large. There are several ways of reducing the kernel size, notably Nystr\"om sampling. We propose here a method more in the spirit of dictionary learning, where the kernel vectors are obtained with a trained sparse representation of the input signals. Moreover, we optimize directly the kernel vectors in the KDL process, using gradient descent steps. We show with three data sets that our algorithms are able to provide better representations, despite using a small number of kernel vectors, and also decrease the execution time with respect to KDL.
Kernel t-distributed stochastic neighbor embedding
Jul 13, 2023
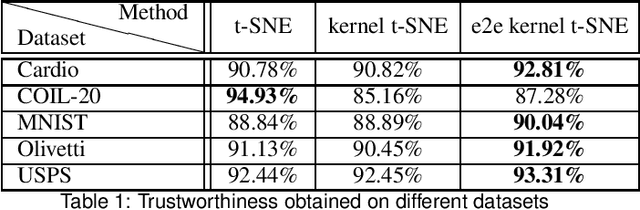


This paper presents a kernelized version of the t-SNE algorithm, capable of mapping high-dimensional data to a low-dimensional space while preserving the pairwise distances between the data points in a non-Euclidean metric. This can be achieved using a kernel trick only in the high dimensional space or in both spaces, leading to an end-to-end kernelized version. The proposed kernelized version of the t-SNE algorithm can offer new views on the relationships between data points, which can improve performance and accuracy in particular applications, such as classification problems involving kernel methods. The differences between t-SNE and its kernelized version are illustrated for several datasets, showing a neater clustering of points belonging to different classes.