 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Înţelegi Româneşte?'' A Recipe for Romanian Vision-Language Models
Jun 01, 2026Vision-Language Models (VLMs) largely follow the text-only LLM trajectory, excelling on English benchmarks but sharply degrading on low-resource languages, where neither large-scale image-text corpora nor culturally grounded evaluations exist. We present a systematic study of building a language-specific VLM for Romanian, covering the full pipeline from data construction to architectural choices. We translate established English VLM training and evaluation corpora into Romanian, applying machine translation to textual annotations and to in-image text, preserving visual grounding while adapting the textual content. Using this data, we train and ablate a series of VLMs to isolate the contribution of (i) vision backbones of varying scale and pretraining, (ii) language backbones from multilingual to Romanian-adapted LLMs, and (iii) OCR-style image-text data. We further curate HoraVQA, a culturally native evaluation set grounded in Romanian everyday scenes. Romanian-adapted VLMs consistently outperform their same-sized counterparts and, across all evaluated benchmarks, even surpass models from the next larger size category.
GTASA: Ground Truth Annotations for Spatiotemporal Analysis, Evaluation and Training of Video Models
Apr 12, 2026Generating complex multi-actor scenario videos remains difficult even for state-of-the-art neural generators, while evaluating them is hard due to the lack of ground truth for physical plausibility and semantic faithfulness. We introduce GTASA, a corpus of multi-actor videos with per-frame spatial relation graphs and event-level temporal mappings, and the system that produced it based on Graphs of Events in Space and Time (GEST): GEST-Engine. We compare our method with both open and closed source neural generators and prove both qualitatively (human evaluation of physical validity and semantic alignment) and quantitatively (via training video captioning models) the clear advantages of our method. Probing four frozen video encoders across 11 spatiotemporal reasoning tasks enabled by GTASA's exact 3D ground truth reveals that self-supervised encoders encode spatial structure significantly better than VLM visual encoders.
Agentic Video Generation: From Text to Executable Event Graphs via Tool-Constrained LLM Planning
Apr 11, 2026Existing multi-agent video generation systems use LLM agents to orchestrate neural video generators, producing visually impressive but semantically unreliable outputs with no ground truth annotations. We present an agentic system that inverts this paradigm: instead of generating pixels, the LLM constructs a formal Graph of Events in Space and Time (GEST) -- a structured specification of actors, actions, objects, and temporal constraints -- which is then executed deterministically in a 3D game engine. A staged LLM refinement pipeline fails entirely at this task (0 of 50 attempts produce an executable specification), motivating a fundamentally different architecture based on a separation of concerns: the LLM handles narrative planning through natural language reasoning, while a programmatic state backend enforces all simulator constraints through validated tool calls, guaranteeing that every generated specification is executable by construction. The system uses a hierarchical two-agent architecture -- a Director that plans the story and a Scene Builder that constructs individual scenes through a round-based state machine -- with dedicated Relation Subagents that populate the logical and semantic edge types of the GEST formalism that procedural generation leaves empty, making this the first approach to exercise the full expressive capacity of the representation. We evaluate in two stages: autonomous generation against procedural baselines via a 3-model LLM jury, where agentic narratives win 79% of text and 74% of video comparisons; and seeded generation where the same text is given to our system, VEO 3.1, and WAN 2.2, with human annotations showing engine-generated videos substantially outperform neural generators on physical validity (58% vs 25% and 20%) and semantic alignment (3.75/5 vs 2.33 and 1.50).
Towards Zero-Shot & Explainable Video Description by Reasoning over Graphs of Events in Space and Time
Jan 14, 2025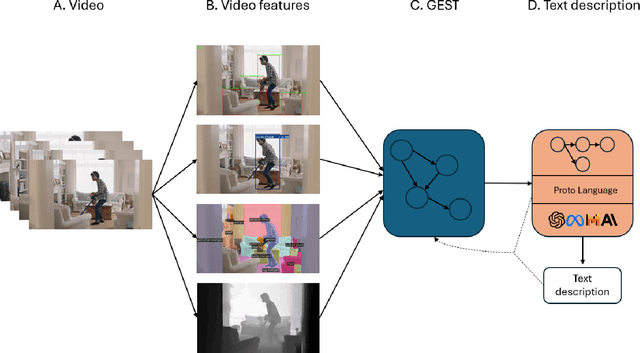
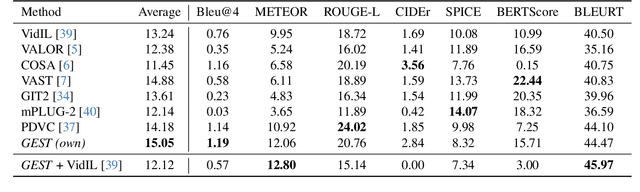
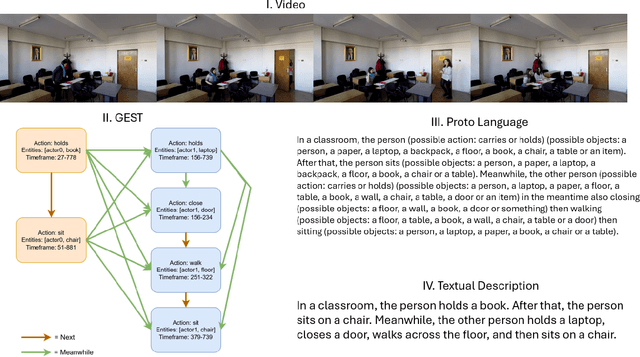
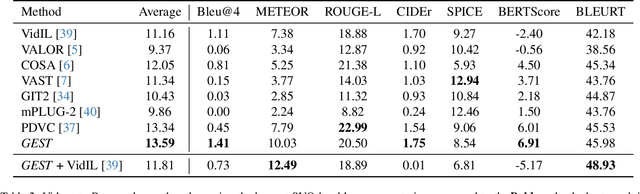
In the current era of Machine Learning, Transformers have become the de facto approach across a variety of domains, such as computer vision and natural language processing. Transformer-based solutions are the backbone of current state-of-the-art methods for language generation, image and video classification, segmentation, action and object recognition, among many others. Interestingly enough, while these state-of-the-art methods produce impressive results in their respective domains, the problem of understanding the relationship between vision and language is still beyond our reach. In this work, we propose a common ground between vision and language based on events in space and time in an explainable and programmatic way, to connect learning-based vision and language state of the art models and provide a solution to the long standing problem of describing videos in natural language. We validate that our algorithmic approach is able to generate coherent, rich and relevant textual descriptions on videos collected from a variety of datasets, using both standard metrics (e.g. Bleu, ROUGE) and the modern LLM-as-a-Jury approach.
"Vorbeşti Româneşte?" A Recipe to Train Powerful Romanian LLMs with English Instructions
Jun 26, 2024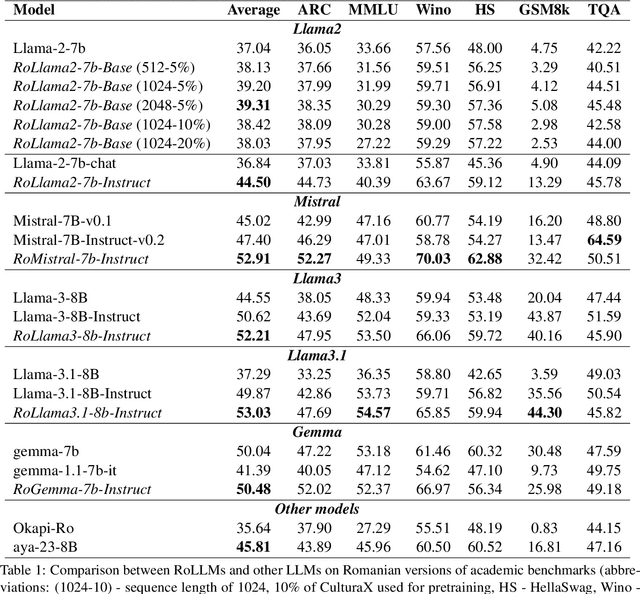
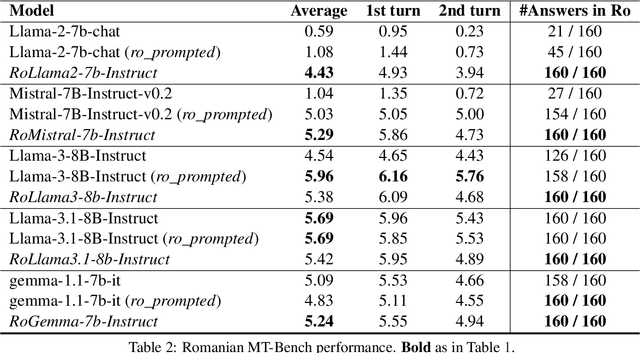
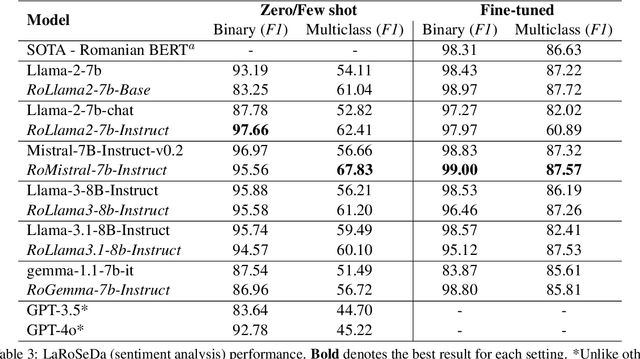
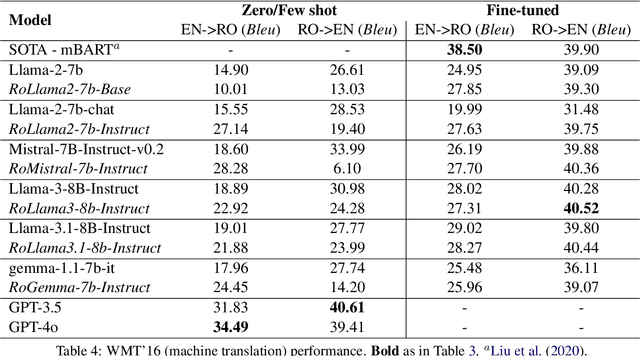
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English; hence, their performance in English greatly exceeds other languages. To our knowledge, we are the first to collect and translate a large collection of texts, instructions, and benchmarks and train, evaluate, and release open-source LLMs tailored for Romanian. We evaluate our methods on four different categories, including academic benchmarks, MT-Bench (manually translated), and a professionally built historical, cultural, and social benchmark adapted to Romanian. We argue for the usefulness and high performance of RoLLMs by obtaining state-of-the-art results across the board. We publicly release all resources (i.e., data, training and evaluation code, models) to support and encourage research on Romanian LLMs while concurrently creating a generalizable recipe, adequate for other low or less-resourced languages.
OpenLLM-Ro -- Technical Report on Open-source Romanian LLMs
May 17, 2024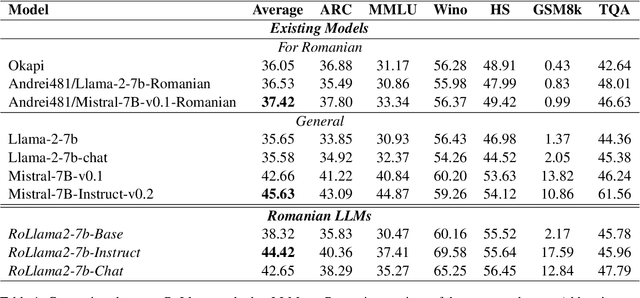

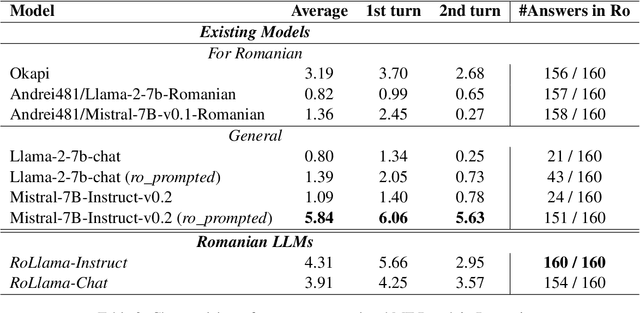
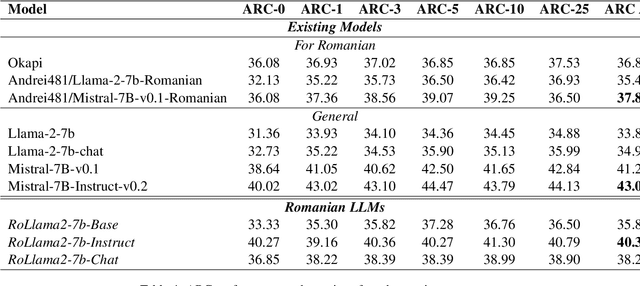
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English. Hence, their performance in English greatly exceeds their performance in other languages. This document presents our approach to training and evaluating the first foundational and chat LLM specialized for Romanian.
Improving Legal Judgement Prediction in Romanian with Long Text Encoders
Mar 04, 2024



In recent years,the entire field of Natural Language Processing (NLP) has enjoyed amazing novel results achieving almost human-like performance on a variety of tasks. Legal NLP domain has also been part of this process, as it has seen an impressive growth. However, general-purpose models are not readily applicable for legal domain. Due to the nature of the domain (e.g. specialized vocabulary, long documents) specific models and methods are often needed for Legal NLP. In this work we investigate both specialized and general models for predicting the final ruling of a legal case, task known as Legal Judgment Prediction (LJP). We particularly focus on methods to extend to sequence length of Transformer-based models to better understand the long documents present in legal corpora. Extensive experiments on 4 LJP datasets in Romanian, originating from 2 sources with significantly different sizes and document lengths, show that specialized models and handling long texts are critical for a good performance.
GEST: the Graph of Events in Space and Time as a Common Representation between Vision and Language
May 22, 2023



One of the essential human skills is the ability to seamlessly build an inner representation of the world. By exploiting this representation, humans are capable of easily finding consensus between visual, auditory and linguistic perspectives. In this work, we set out to understand and emulate this ability through an explicit representation for both vision and language - Graphs of Events in Space and Time (GEST). GEST alows us to measure the similarity between texts and videos in a semantic and fully explainable way, through graph matching. It also allows us to generate text and videos from a common representation that provides a well understood content. In this work we show that the graph matching similarity metrics based on GEST outperform classical text generation metrics and can also boost the performance of state of art, heavily trained metrics.