 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Inference-time Category-wise Safety Steering for Large Language Models
Paper and Code
Oct 02, 2024


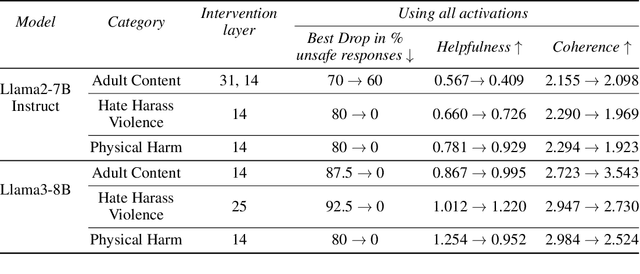
While large language models (LLMs) have seen unprecedented advancements in capabilities and applications across a variety of use-cases, safety alignment of these models is still an area of active research. The fragile nature of LLMs, even models that have undergone extensive alignment and safety training regimes, warrants additional safety steering steps via training-free, inference-time methods. While recent work in the area of mechanistic interpretability has investigated how activations in latent representation spaces may encode concepts, and thereafter performed representation engineering to induce such concepts in LLM outputs, the applicability of such for safety is relatively under-explored. Unlike recent inference-time safety steering works, in this paper we explore safety steering of LLM outputs using: (i) category-specific steering vectors, thereby enabling fine-grained control over the steering, and (ii) sophisticated methods for extracting informative steering vectors for more effective safety steering while retaining quality of the generated text. We demonstrate our exploration on multiple LLMs and datasets, and showcase the effectiveness of the proposed steering method, along with a discussion on the implications and best practices.