 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMatch: Multihead Consistency Regularization Matching for Semi-Supervised Text Classification
Jun 09, 2025We introduce MultiMatch, a novel semi-supervised learning (SSL) algorithm combining the paradigms of co-training and consistency regularization with pseudo-labeling. At its core, MultiMatch features a three-fold pseudo-label weighting module designed for three key purposes: selecting and filtering pseudo-labels based on head agreement and model confidence, and weighting them according to the perceived classification difficulty. This novel module enhances and unifies three existing techniques -- heads agreement from Multihead Co-training, self-adaptive thresholds from FreeMatch, and Average Pseudo-Margins from MarginMatch -- resulting in a holistic approach that improves robustness and performance in SSL settings. Experimental results on benchmark datasets highlight the superior performance of MultiMatch, achieving state-of-the-art results on 9 out of 10 setups from 5 natural language processing datasets and ranking first according to the Friedman test among 19 methods. Furthermore, MultiMatch demonstrates exceptional robustness in highly imbalanced settings, outperforming the second-best approach by 3.26% -- and data imbalance is a key factor for many text classification tasks.
Deep learning for music generation. Four approaches and their comparative evaluation
Apr 03, 2025


This paper introduces four different artificial intelligence algorithms for music generation and aims to compare these methods not only based on the aesthetic quality of the generated music but also on their suitability for specific applications. The first set of melodies is produced by a slightly modified visual transformer neural network that is used as a language model. The second set of melodies is generated by combining chat sonification with a classic transformer neural network (the same method of music generation is presented in a previous research), the third set of melodies is generated by combining the Schillinger rhythm theory together with a classic transformer neural network, and the fourth set of melodies is generated using GPT3 transformer provided by OpenAI. A comparative analysis is performed on the melodies generated by these approaches and the results indicate that significant differences can be observed between them and regarding the aesthetic value of them, GPT3 produced the most pleasing melodies, and the newly introduced Schillinger method proved to generate better sounding music than previous sonification methods.
UPB at SemEval-2020 Task 8: Joint Textual and Visual Modeling in a Multi-Task Learning Architecture for Memotion Analysis
Sep 06, 2020

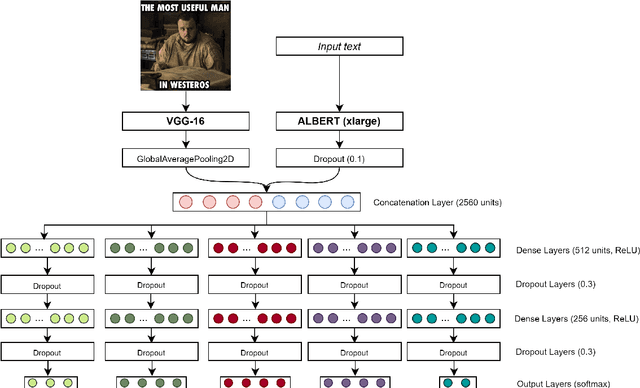

Users from the online environment can create different ways of expressing their thoughts, opinions, or conception of amusement. Internet memes were created specifically for these situations. Their main purpose is to transmit ideas by using combinations of images and texts such that they will create a certain state for the receptor, depending on the message the meme has to send. These posts can be related to various situations or events, thus adding a funny side to any circumstance our world is situated in. In this paper, we describe the system developed by our team for SemEval-2020 Task 8: Memotion Analysis. More specifically, we introduce a novel system to analyze these posts, a multimodal multi-task learning architecture that combines ALBERT for text encoding with VGG-16 for image representation. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the three subtasks of the current competition, ranking 11th for Subtask A (0.3453 macro F1-score), 1st for Subtask B (0.5183 macro F1-score), and 3rd for Subtask C (0.3171 macro F1-score) while exceeding the official baseline results by high margins.