 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPB at SemEval-2020 Task 9: Identifying Sentiment in Code-Mixed Social Media Texts using Transformers and Multi-Task Learning
Sep 06, 2020
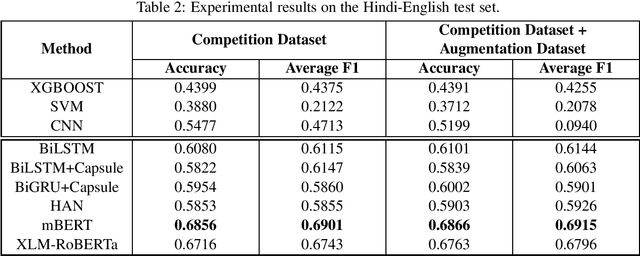


Sentiment analysis is a process widely used in opinion mining campaigns conducted today. This phenomenon presents applications in a variety of fields, especially in collecting information related to the attitude or satisfaction of users concerning a particular subject. However, the task of managing such a process becomes noticeably more difficult when it is applied in cultures that tend to combine two languages in order to express ideas and thoughts. By interleaving words from two languages, the user can express with ease, but at the cost of making the text far less intelligible for those who are not familiar with this technique, but also for standard opinion mining algorithms. In this paper, we describe the systems developed by our team for SemEval-2020 Task 9 that aims to cover two well-known code-mixed languages: Hindi-English and Spanish-English. We intend to solve this issue by introducing a solution that takes advantage of several neural network approaches, as well as pre-trained word embeddings. Our approach (multlingual BERT) achieves promising performance on the Hindi-English task, with an average F1-score of 0.6850, registered on the competition leaderboard, ranking our team 16th out of 62 participants. For the Spanish-English task, we obtained an average F1-score of 0.7064 ranking our team 17th out of 29 participants by using another multilingual Transformer-based model, XLM-RoBERTa.
UPB at SemEval-2020 Task 8: Joint Textual and Visual Modeling in a Multi-Task Learning Architecture for Memotion Analysis
Sep 06, 2020

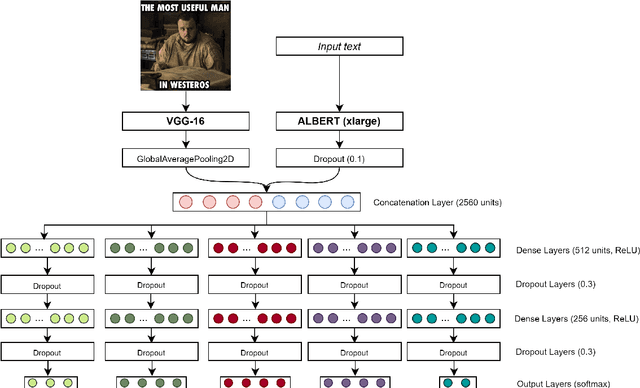

Users from the online environment can create different ways of expressing their thoughts, opinions, or conception of amusement. Internet memes were created specifically for these situations. Their main purpose is to transmit ideas by using combinations of images and texts such that they will create a certain state for the receptor, depending on the message the meme has to send. These posts can be related to various situations or events, thus adding a funny side to any circumstance our world is situated in. In this paper, we describe the system developed by our team for SemEval-2020 Task 8: Memotion Analysis. More specifically, we introduce a novel system to analyze these posts, a multimodal multi-task learning architecture that combines ALBERT for text encoding with VGG-16 for image representation. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the three subtasks of the current competition, ranking 11th for Subtask A (0.3453 macro F1-score), 1st for Subtask B (0.5183 macro F1-score), and 3rd for Subtask C (0.3171 macro F1-score) while exceeding the official baseline results by high margins.