 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Code Preference via Synthetic Evolution
Paper and Code
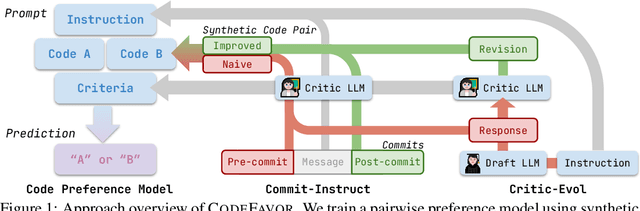

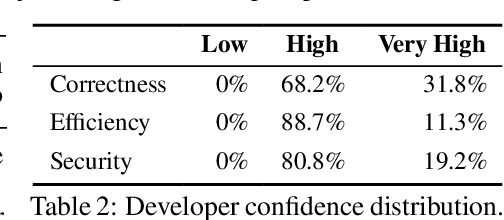
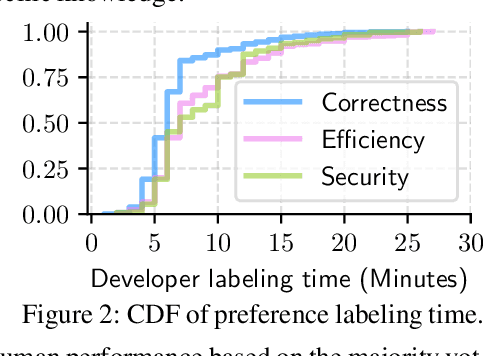
Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.