 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Meta-Rule Selection Policy for Visual Generative Abductive Learning
Mar 09, 2025Visual generative abductive learning studies jointly training symbol-grounded neural visual generator and inducing logic rules from data, such that after learning, the visual generation process is guided by the induced logic rules. A major challenge for this task is to reduce the time cost of logic abduction during learning, an essential step when the logic symbol set is large and the logic rule to induce is complicated. To address this challenge, we propose a pre-training method for obtaining meta-rule selection policy for the recently proposed visual generative learning approach AbdGen [Peng et al., 2023], aiming at significantly reducing the candidate meta-rule set and pruning the search space. The selection model is built based on the embedding representation of both symbol grounding of cases and meta-rules, which can be effectively integrated with both neural model and logic reasoning system. The pre-training process is done on pure symbol data, not involving symbol grounding learning of raw visual inputs, making the entire learning process low-cost. An additional interesting observation is that the selection policy can rectify symbol grounding errors unseen during pre-training, which is resulted from the memorization ability of attention mechanism and the relative stability of symbolic patterns. Experimental results show that our method is able to effectively address the meta-rule selection problem for visual abduction, boosting the efficiency of visual generative abductive learning. Code is available at https://github.com/future-item/metarule-select.
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
Nov 27, 2024

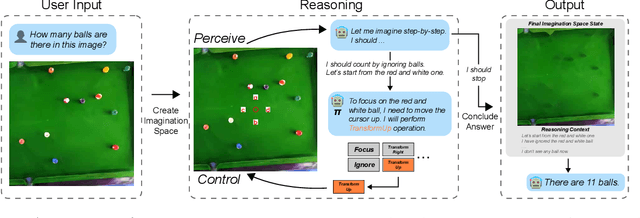

There have been recent efforts to extend the Chain-of-Thought (CoT) paradigm to Multimodal Large Language Models (MLLMs) by finding visual clues in the input scene, advancing the visual reasoning ability of MLLMs. However, current approaches are specially designed for the tasks where clue finding plays a major role in the whole reasoning process, leading to the difficulty in handling complex visual scenes where clue finding does not actually simplify the whole reasoning task. To deal with this challenge, we propose a new visual reasoning paradigm enabling MLLMs to autonomously modify the input scene to new ones based on its reasoning status, such that CoT is reformulated as conducting simple closed-loop decision-making and reasoning steps under a sequence of imagined visual scenes, leading to natural and general CoT construction. To implement this paradigm, we introduce a novel plug-and-play imagination space, where MLLMs conduct visual modifications through operations like focus, ignore, and transform based on their native reasoning ability without specific training. We validate our approach through a benchmark spanning dense counting, simple jigsaw puzzle solving, and object placement, challenging the reasoning ability beyond clue finding. The results verify that while existing techniques fall short, our approach enables MLLMs to effectively reason step by step through autonomous imagination. Project page: https://future-item.github.io/autoimagine-site.
SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models
Mar 04, 2022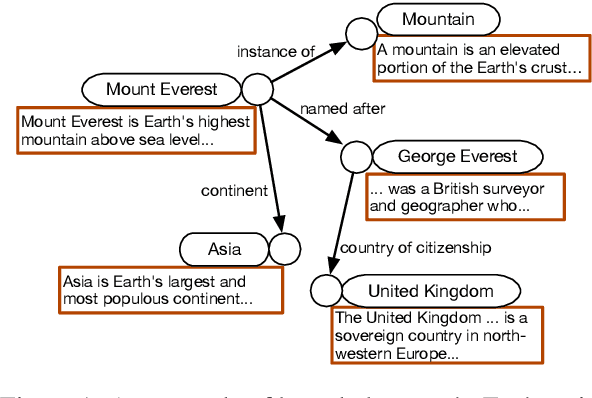

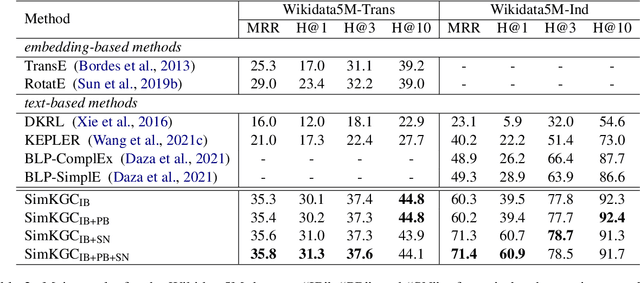
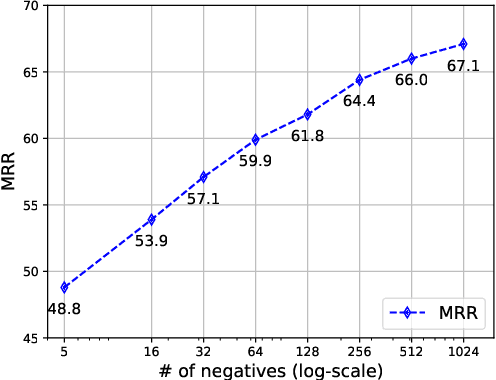
Knowledge graph completion (KGC) aims to reason over known facts and infer the missing links. Text-based methods such as KGBERT (Yao et al., 2019) learn entity representations from natural language descriptions, and have the potential for inductive KGC. However, the performance of text-based methods still largely lag behind graph embedding-based methods like TransE (Bordes et al., 2013) and RotatE (Sun et al., 2019b). In this paper, we identify that the key issue is efficient contrastive learning. To improve the learning efficiency, we introduce three types of negatives: in-batch negatives, pre-batch negatives, and self-negatives which act as a simple form of hard negatives. Combined with InfoNCE loss, our proposed model SimKGC can substantially outperform embedding-based methods on several benchmark datasets. In terms of mean reciprocal rank (MRR), we advance the state-of-the-art by +19% on WN18RR, +6.8% on the Wikidata5M transductive setting, and +22% on the Wikidata5M inductive setting. Thorough analyses are conducted to gain insights into each component. Our code is available at https://github.com/intfloat/SimKGC .
Aligning Cross-lingual Sentence Representations with Dual Momentum Contrast
Sep 01, 2021
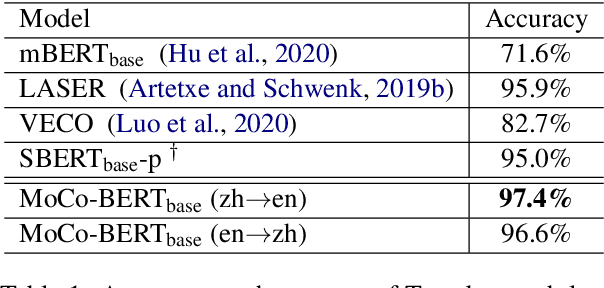
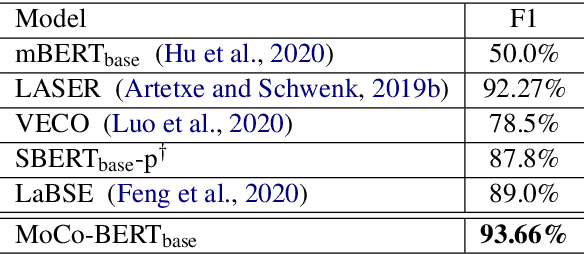
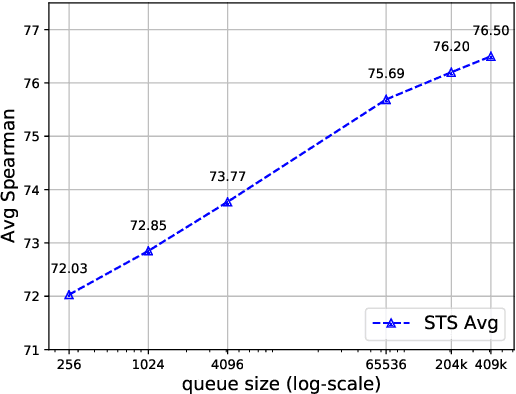
In this paper, we propose to align sentence representations from different languages into a unified embedding space, where semantic similarities (both cross-lingual and monolingual) can be computed with a simple dot product. Pre-trained language models are fine-tuned with the translation ranking task. Existing work (Feng et al., 2020) uses sentences within the same batch as negatives, which can suffer from the issue of easy negatives. We adapt MoCo (He et al., 2020) to further improve the quality of alignment. As the experimental results show, the sentence representations produced by our model achieve the new state-of-the-art on several tasks, including Tatoeba en-zh similarity search (Artetxe and Schwenk, 2019b), BUCC en-zh bitext mining, and semantic textual similarity on 7 datasets.
Ape210K: A Large-Scale and Template-Rich Dataset of Math Word Problems
Oct 09, 2020
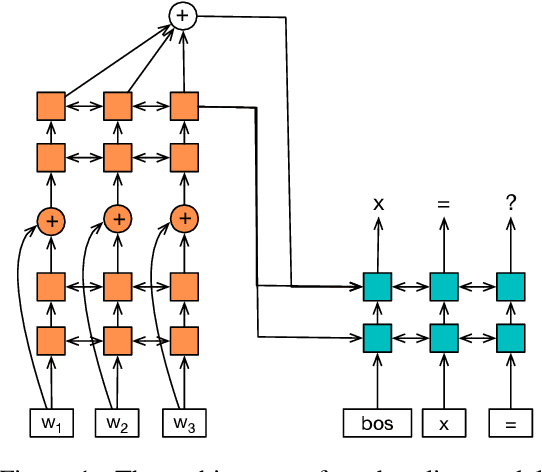


Automatic math word problem solving has attracted growing attention in recent years. The evaluation datasets used by previous works have serious limitations in terms of scale and diversity. In this paper, we release a new large-scale and template-rich math word problem dataset named Ape210K. It consists of 210K Chinese elementary school-level math problems, which is 9 times the size of the largest public dataset Math23K. Each problem contains both the gold answer and the equations needed to derive the answer. Ape210K is also of greater diversity with 56K templates, which is 25 times more than Math23K. Our analysis shows that solving Ape210K requires not only natural language understanding but also commonsense knowledge. We expect Ape210K to be a benchmark for math word problem solving systems. Experiments indicate that state-of-the-art models on the Math23K dataset perform poorly on Ape210K. We propose a copy-augmented and feature-enriched sequence to sequence (seq2seq) model, which outperforms existing models by 3.2% on the Math23K dataset and serves as a strong baseline of the Ape210K dataset. The gap is still significant between human and our baseline model, calling for further research efforts. We make Ape210K dataset publicly available at https://github.com/yuantiku/ape210k
Investigating Label Bias in Beam Search for Open-ended Text Generation
May 22, 2020



Beam search is an effective and widely used decoding algorithm in many sequence-to-sequence (seq2seq) text generation tasks. However, in open-ended text generation, beam search is often found to produce repetitive and generic texts, sampling-based decoding algorithms like top-k sampling and nucleus sampling are more preferred. Standard seq2seq models suffer from label bias due to its locally normalized probability formulation. This paper provides a series of empirical evidence that label bias is a major reason for such degenerate behaviors of beam search. By combining locally normalized maximum likelihood estimation and globally normalized sequence-level training, label bias can be reduced with almost no sacrifice in perplexity. To quantitatively measure label bias, we test the model's ability to discriminate the groundtruth text and a set of context-agnostic distractors. We conduct experiments on large-scale response generation datasets. Results show that beam search can produce more diverse and meaningful texts with our approach, in terms of both automatic and human evaluation metrics. Our analysis also suggests several future working directions towards the grand challenge of open-ended text generation.
Denoising based Sequence-to-Sequence Pre-training for Text Generation
Aug 22, 2019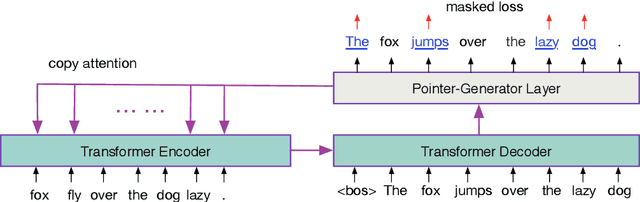


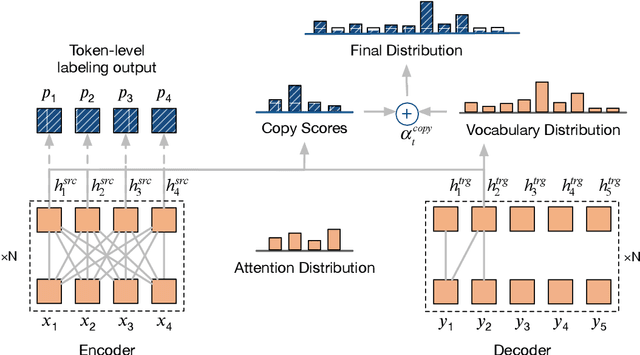
This paper presents a new sequence-to-sequence (seq2seq) pre-training method PoDA (Pre-training of Denoising Autoencoders), which learns representations suitable for text generation tasks. Unlike encoder-only (e.g., BERT) or decoder-only (e.g., OpenAI GPT) pre-training approaches, PoDA jointly pre-trains both the encoder and decoder by denoising the noise-corrupted text, and it also has the advantage of keeping the network architecture unchanged in the subsequent fine-tuning stage. Meanwhile, we design a hybrid model of Transformer and pointer-generator networks as the backbone architecture for PoDA. We conduct experiments on two text generation tasks: abstractive summarization, and grammatical error correction. Results on four datasets show that PoDA can improve model performance over strong baselines without using any task-specific techniques and significantly speed up convergence.
Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
Mar 01, 2019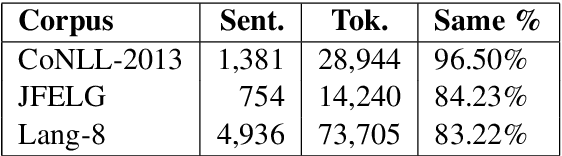
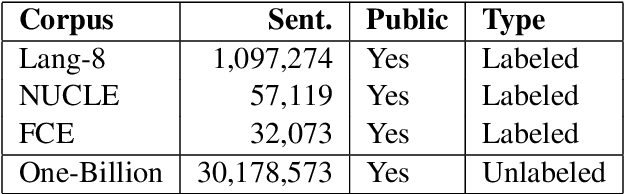
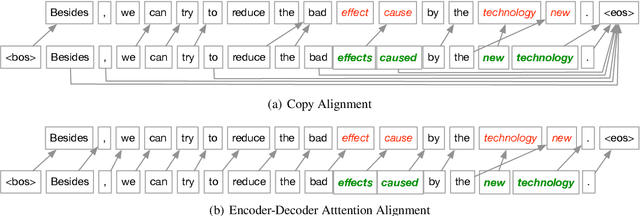
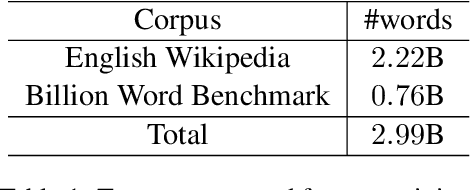
Neural machine translation systems have become state-of-the-art approaches for Grammatical Error Correction (GEC) task. In this paper, we propose a copy-augmented architecture for the GEC task by copying the unchanged words from the source sentence to the target sentence. Since the GEC suffers from not having enough labeled training data to achieve high accuracy. We pre-train the copy-augmented architecture with a denoising auto-encoder using the unlabeled One Billion Benchmark and make comparisons between the fully pre-trained model and a partially pre-trained model. It is the first time copying words from the source context and fully pre-training a sequence to sequence model are experimented on the GEC task. Moreover, We add token-level and sentence-level multi-task learning for the GEC task. The evaluation results on the CoNLL-2014 test set show that our approach outperforms all recently published state-of-the-art results by a large margin.
Multi-Perspective Context Aggregation for Semi-supervised Cloze-style Reading Comprehension
Aug 20, 2018
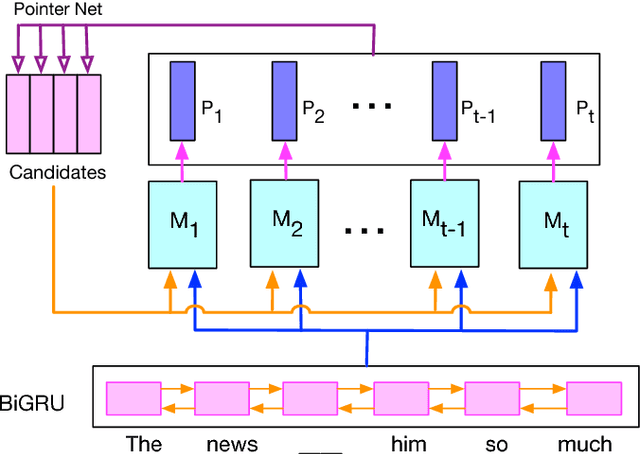
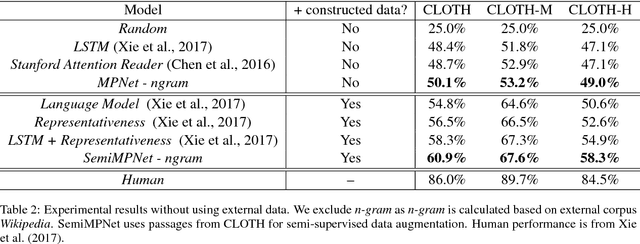
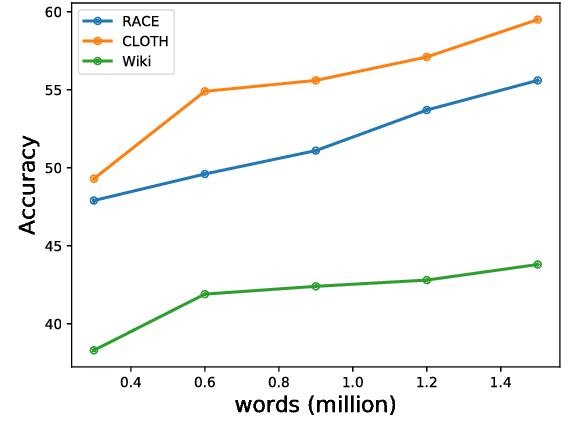
Cloze-style reading comprehension has been a popular task for measuring the progress of natural language understanding in recent years. In this paper, we design a novel multi-perspective framework, which can be seen as the joint training of heterogeneous experts and aggregate context information from different perspectives. Each perspective is modeled by a simple aggregation module. The outputs of multiple aggregation modules are fed into a one-timestep pointer network to get the final answer. At the same time, to tackle the problem of insufficient labeled data, we propose an efficient sampling mechanism to automatically generate more training examples by matching the distribution of candidates between labeled and unlabeled data. We conduct our experiments on a recently released cloze-test dataset CLOTH (Xie et al., 2017), which consists of nearly 100k questions designed by professional teachers. Results show that our method achieves new state-of-the-art performance over previous strong baselines.
Yuanfudao at SemEval-2018 Task 11: Three-way Attention and Relational Knowledge for Commonsense Machine Comprehension
May 15, 2018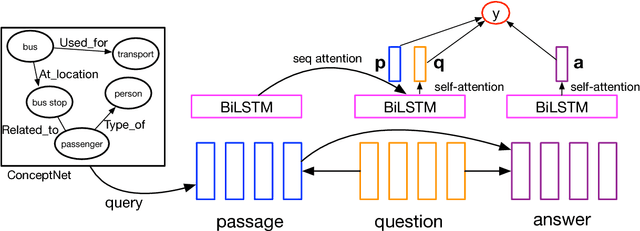
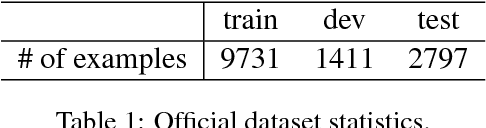
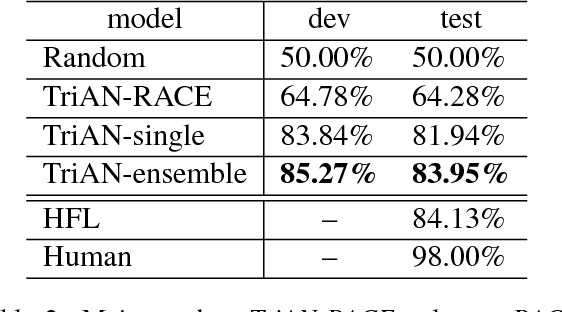
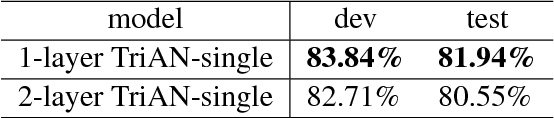
This paper describes our system for SemEval-2018 Task 11: Machine Comprehension using Commonsense Knowledge. We use Three-way Attentive Networks (TriAN) to model interactions between the passage, question and answers. To incorporate commonsense knowledge, we augment the input with relation embedding from the graph of general knowledge ConceptNet (Speer et al., 2017). As a result, our system achieves state-of-the-art performance with 83.95% accuracy on the official test data. Code is publicly available at https://github.com/intfloat/commonsense-rc