 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising based Sequence-to-Sequence Pre-training for Text Generation
Aug 22, 2019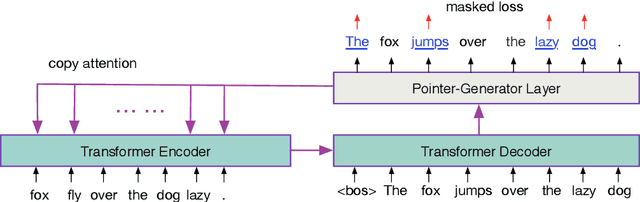


This paper presents a new sequence-to-sequence (seq2seq) pre-training method PoDA (Pre-training of Denoising Autoencoders), which learns representations suitable for text generation tasks. Unlike encoder-only (e.g., BERT) or decoder-only (e.g., OpenAI GPT) pre-training approaches, PoDA jointly pre-trains both the encoder and decoder by denoising the noise-corrupted text, and it also has the advantage of keeping the network architecture unchanged in the subsequent fine-tuning stage. Meanwhile, we design a hybrid model of Transformer and pointer-generator networks as the backbone architecture for PoDA. We conduct experiments on two text generation tasks: abstractive summarization, and grammatical error correction. Results on four datasets show that PoDA can improve model performance over strong baselines without using any task-specific techniques and significantly speed up convergence.
Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
Mar 01, 2019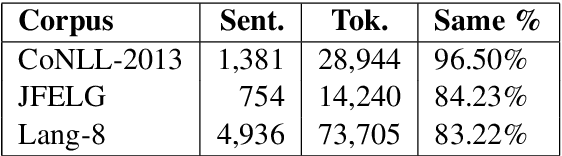
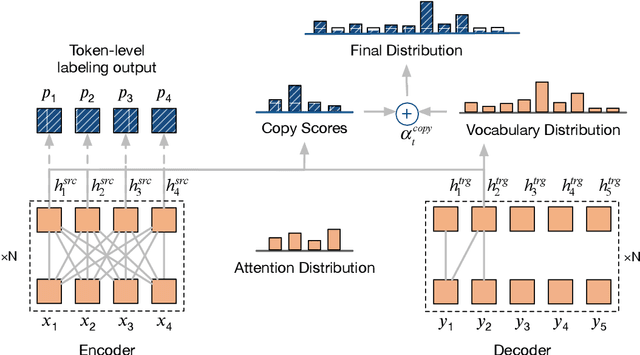
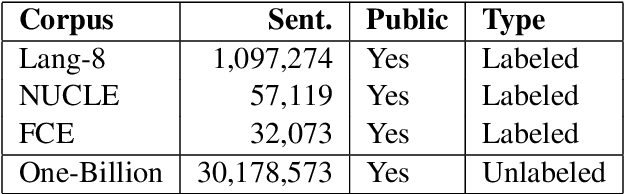
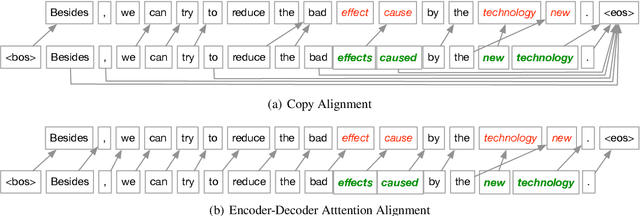
Neural machine translation systems have become state-of-the-art approaches for Grammatical Error Correction (GEC) task. In this paper, we propose a copy-augmented architecture for the GEC task by copying the unchanged words from the source sentence to the target sentence. Since the GEC suffers from not having enough labeled training data to achieve high accuracy. We pre-train the copy-augmented architecture with a denoising auto-encoder using the unlabeled One Billion Benchmark and make comparisons between the fully pre-trained model and a partially pre-trained model. It is the first time copying words from the source context and fully pre-training a sequence to sequence model are experimented on the GEC task. Moreover, We add token-level and sentence-level multi-task learning for the GEC task. The evaluation results on the CoNLL-2014 test set show that our approach outperforms all recently published state-of-the-art results by a large margin.
Multi-Perspective Context Aggregation for Semi-supervised Cloze-style Reading Comprehension
Aug 20, 2018
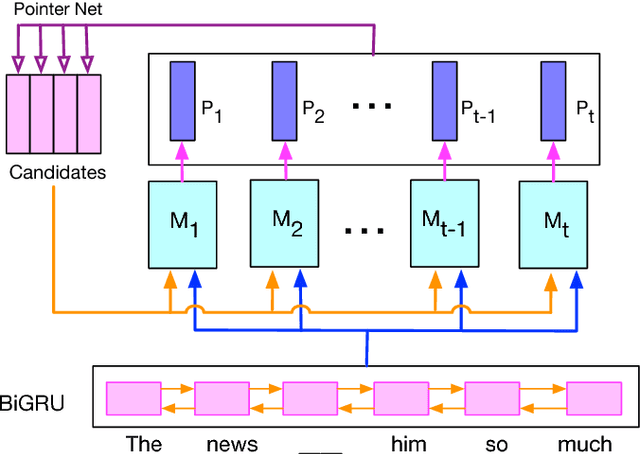
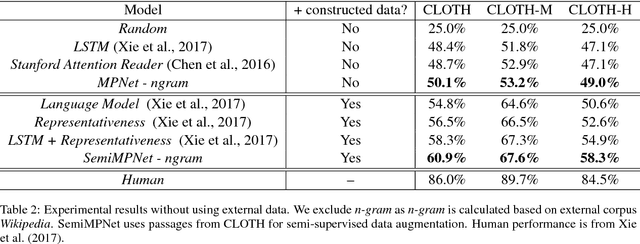
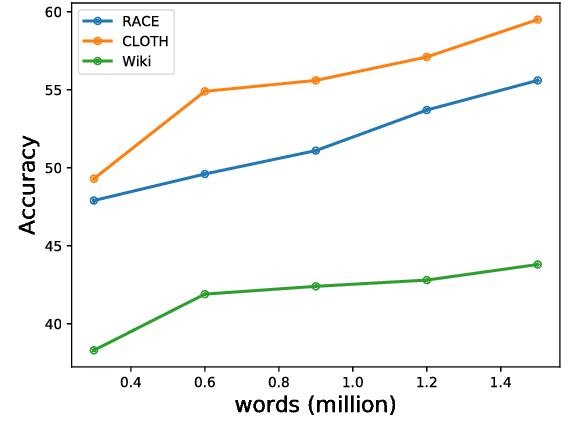
Cloze-style reading comprehension has been a popular task for measuring the progress of natural language understanding in recent years. In this paper, we design a novel multi-perspective framework, which can be seen as the joint training of heterogeneous experts and aggregate context information from different perspectives. Each perspective is modeled by a simple aggregation module. The outputs of multiple aggregation modules are fed into a one-timestep pointer network to get the final answer. At the same time, to tackle the problem of insufficient labeled data, we propose an efficient sampling mechanism to automatically generate more training examples by matching the distribution of candidates between labeled and unlabeled data. We conduct our experiments on a recently released cloze-test dataset CLOTH (Xie et al., 2017), which consists of nearly 100k questions designed by professional teachers. Results show that our method achieves new state-of-the-art performance over previous strong baselines.