 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models
Mar 04, 2022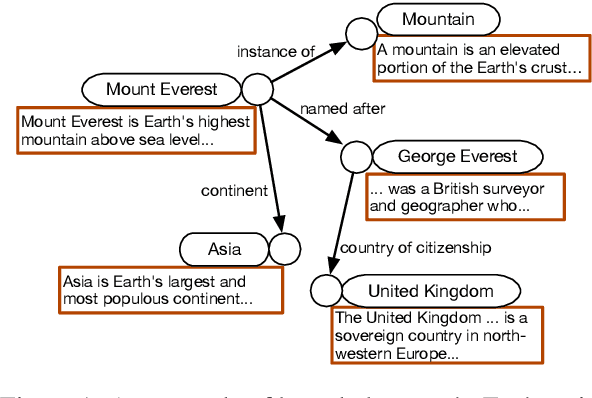

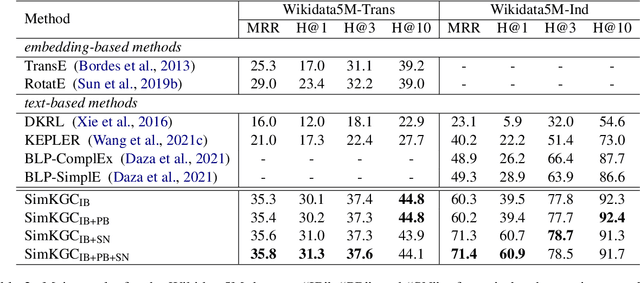
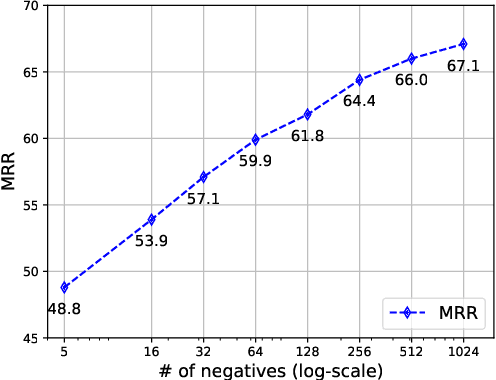
Knowledge graph completion (KGC) aims to reason over known facts and infer the missing links. Text-based methods such as KGBERT (Yao et al., 2019) learn entity representations from natural language descriptions, and have the potential for inductive KGC. However, the performance of text-based methods still largely lag behind graph embedding-based methods like TransE (Bordes et al., 2013) and RotatE (Sun et al., 2019b). In this paper, we identify that the key issue is efficient contrastive learning. To improve the learning efficiency, we introduce three types of negatives: in-batch negatives, pre-batch negatives, and self-negatives which act as a simple form of hard negatives. Combined with InfoNCE loss, our proposed model SimKGC can substantially outperform embedding-based methods on several benchmark datasets. In terms of mean reciprocal rank (MRR), we advance the state-of-the-art by +19% on WN18RR, +6.8% on the Wikidata5M transductive setting, and +22% on the Wikidata5M inductive setting. Thorough analyses are conducted to gain insights into each component. Our code is available at https://github.com/intfloat/SimKGC .