 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Prototype Learning for Zero-Shot Recognition
Paper and Code
Oct 24, 2019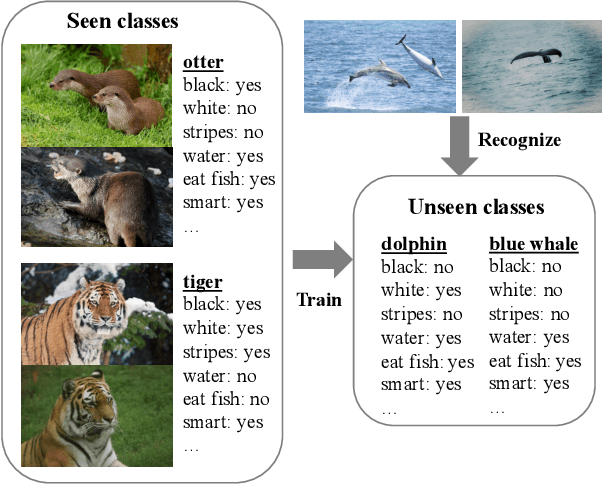

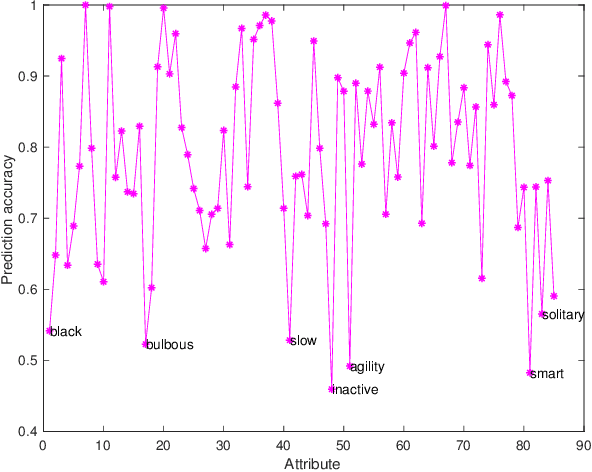
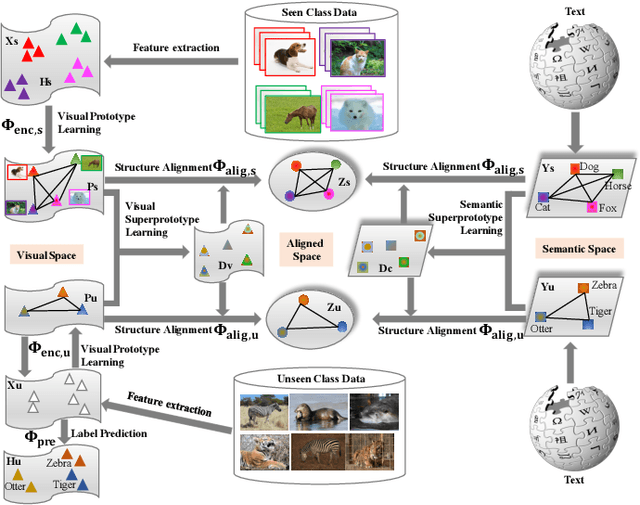
Zero-Shot Learning (ZSL) has received extensive attention and successes in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. Key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary semantic prototypes (e.g., word or attribute vectors). However, the popularly learned projection functions in previous works cannot generalize well due to non-visual components included in semantic prototypes. Besides, the incompleteness of provided prototypes and captured images has less been considered by the state-of-the-art approaches in ZSL. In this paper, we propose a hierarchical prototype learning formulation to provide a systematical solution (named HPL) for zero-shot recognition. Specifically, HPL is able to obtain discriminability on both seen and unseen class domains by learning visual prototypes respectively under the transductive setting. To narrow the gap of two domains, we further learn the interpretable super-prototypes in both visual and semantic spaces. Meanwhile, the two spaces are further bridged by maximizing their structural consistency. This not only facilitates the representativeness of visual prototypes, but also alleviates the loss of information of semantic prototypes. An extensive group of experiments are then carefully designed and presented, demonstrating that HPL obtains remarkably more favorable efficiency and effectiveness, over currently available alternatives under various settings.