 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inception Attention for Image Synthesis and Image Recognition
Paper and Code


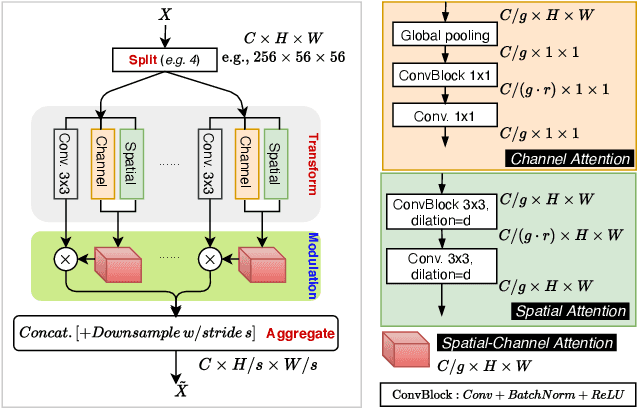

Image synthesis and image recognition have witnessed remarkable progress, but often at the expense of computationally expensive training and inference. Learning lightweight yet expressive deep model has emerged as an important and interesting direction. Inspired by the well-known split-transform-aggregate design heuristic in the Inception building block, this paper proposes a Skip-Layer Inception Module (SLIM) that facilitates efficient learning of image synthesis models, and a same-layer variant (dubbed as SLIM too) as a stronger alternative to the well-known ResNeXts for image recognition. In SLIM, the input feature map is first split into a number of groups (e.g., 4).Each group is then transformed to a latent style vector(via channel-wise attention) and a latent spatial mask (via spatial attention). The learned latent masks and latent style vectors are aggregated to modulate the target feature map. For generative learning, SLIM is built on a recently proposed lightweight Generative Adversarial Networks (i.e., FastGANs) which present a skip-layer excitation(SLE) module. For few-shot image synthesis tasks, the proposed SLIM achieves better performance than the SLE work and other related methods. For one-shot image synthesis tasks, it shows stronger capability of preserving images structures than prior arts such as the SinGANs. For image classification tasks, the proposed SLIM is used as a drop-in replacement for convolution layers in ResNets (resulting in ResNeXt-like models) and achieves better accuracy in theImageNet-1000 dataset, with significantly smaller model complexity