 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
VISAGNN: Versatile Staleness-Aware Efficient Training on Large-Scale Graphs
Nov 16, 2025Graph Neural Networks (GNNs) have shown exceptional success in graph representation learning and a wide range of real-world applications. However, scaling deeper GNNs poses challenges due to the neighbor explosion problem when training on large-scale graphs. To mitigate this, a promising class of GNN training algorithms utilizes historical embeddings to reduce computation and memory costs while preserving the expressiveness of the model. These methods leverage historical embeddings for out-of-batch nodes, effectively approximating full-batch training without losing any neighbor information-a limitation found in traditional sampling methods. However, the staleness of these historical embeddings often introduces significant bias, acting as a bottleneck that can adversely affect model performance. In this paper, we propose a novel VersatIle Staleness-Aware GNN, named VISAGNN, which dynamically and adaptively incorporates staleness criteria into the large-scale GNN training process. By embedding staleness into the message passing mechanism, loss function, and historical embeddings during training, our approach enables the model to adaptively mitigate the negative effects of stale embeddings, thereby reducing estimation errors and enhancing downstream accuracy. Comprehensive experiments demonstrate the effectiveness of our method in overcoming the staleness issue of existing historical embedding techniques, showcasing its superior performance and efficiency on large-scale benchmarks, along with significantly faster convergence.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
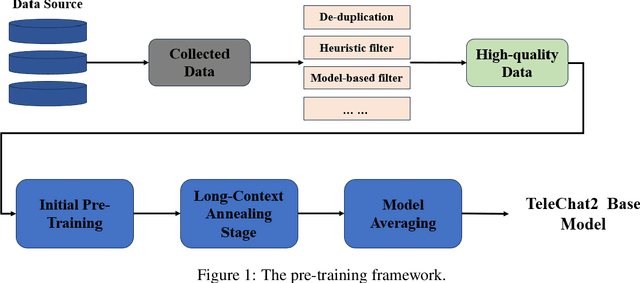

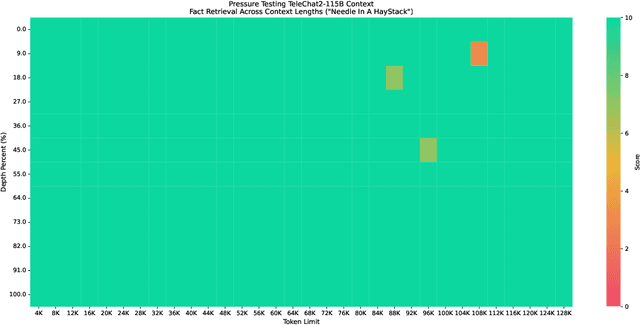
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
H$^3$GNNs: Harmonizing Heterophily and Homophily in GNNs via Joint Structural Node Encoding and Self-Supervised Learning
Apr 16, 2025Graph Neural Networks (GNNs) struggle to balance heterophily and homophily in representation learning, a challenge further amplified in self-supervised settings. We propose H$^3$GNNs, an end-to-end self-supervised learning framework that harmonizes both structural properties through two key innovations: (i) Joint Structural Node Encoding. We embed nodes into a unified space combining linear and non-linear feature projections with K-hop structural representations via a Weighted Graph Convolution Network(WGCN). A cross-attention mechanism enhances awareness and adaptability to heterophily and homophily. (ii) Self-Supervised Learning Using Teacher-Student Predictive Architectures with Node-Difficulty Driven Dynamic Masking Strategies. We use a teacher-student model, the student sees the masked input graph and predicts node features inferred by the teacher that sees the full input graph in the joint encoding space. To enhance learning difficulty, we introduce two novel node-predictive-difficulty-based masking strategies. Experiments on seven benchmarks (four heterophily datasets and three homophily datasets) confirm the effectiveness and efficiency of H$^3$GNNs across diverse graph types. Our H$^3$GNNs achieves overall state-of-the-art performance on the four heterophily datasets, while retaining on-par performance to previous state-of-the-art methods on the three homophily datasets.
Haste Makes Waste: A Simple Approach for Scaling Graph Neural Networks
Oct 07, 2024Graph neural networks (GNNs) have demonstrated remarkable success in graph representation learning, and various sampling approaches have been proposed to scale GNNs to applications with large-scale graphs. A class of promising GNN training algorithms take advantage of historical embeddings to reduce the computation and memory cost while maintaining the model expressiveness of GNNs. However, they incur significant computation bias due to the stale feature history. In this paper, we provide a comprehensive analysis of their staleness and inferior performance on large-scale problems. Motivated by our discoveries, we propose a simple yet highly effective training algorithm (REST) to effectively reduce feature staleness, which leads to significantly improved performance and convergence across varying batch sizes. The proposed algorithm seamlessly integrates with existing solutions, boasting easy implementation, while comprehensive experiments underscore its superior performance and efficiency on large-scale benchmarks. Specifically, our improvements to state-of-the-art historical embedding methods result in a 2.7% and 3.6% performance enhancement on the ogbn-papers100M and ogbn-products dataset respectively, accompanied by notably accelerated convergence.
Linear-Time Graph Neural Networks for Scalable Recommendations
Feb 21, 2024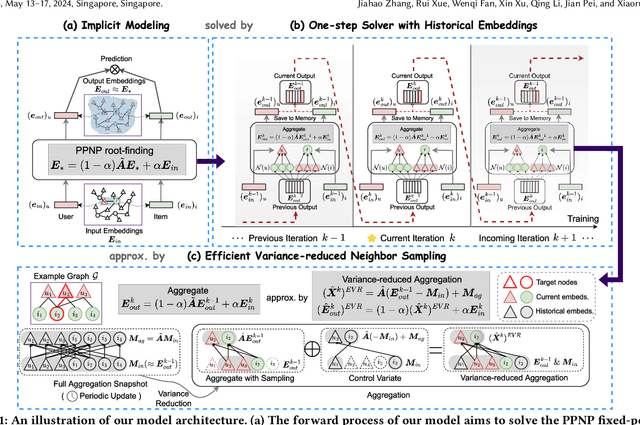



In an era of information explosion, recommender systems are vital tools to deliver personalized recommendations for users. The key of recommender systems is to forecast users' future behaviors based on previous user-item interactions. Due to their strong expressive power of capturing high-order connectivities in user-item interaction data, recent years have witnessed a rising interest in leveraging Graph Neural Networks (GNNs) to boost the prediction performance of recommender systems. Nonetheless, classic Matrix Factorization (MF) and Deep Neural Network (DNN) approaches still play an important role in real-world large-scale recommender systems due to their scalability advantages. Despite the existence of GNN-acceleration solutions, it remains an open question whether GNN-based recommender systems can scale as efficiently as classic MF and DNN methods. In this paper, we propose a Linear-Time Graph Neural Network (LTGNN) to scale up GNN-based recommender systems to achieve comparable scalability as classic MF approaches while maintaining GNNs' powerful expressiveness for superior prediction accuracy. Extensive experiments and ablation studies are presented to validate the effectiveness and scalability of the proposed algorithm. Our implementation based on PyTorch is available.
Efficient Large Language Models Fine-Tuning On Graphs
Dec 07, 2023Learning from Text-Attributed Graphs (TAGs) has attracted significant attention due to its wide range of real-world applications. The rapid evolution of large language models (LLMs) has revolutionized the way we process textual data, which indicates a strong potential to replace shallow text embedding generally used in Graph Neural Networks (GNNs). However, we find that existing LLM approaches that exploit text information in graphs suffer from inferior computation and data efficiency. In this work, we introduce a novel and efficient approach for the end-to-end fine-tuning of Large Language Models (LLMs) on TAGs, named LEADING. The proposed approach maintains computation cost and memory overhead comparable to the graph-less fine-tuning of LLMs. Moreover, it transfers the rick knowledge in LLMs to downstream graph learning tasks effectively with limited labeled data in semi-supervised learning. Its superior computation and data efficiency are demonstrated through comprehensive experiments, offering a promising solution for a wide range of LLMs and graph learning tasks on TAGs.
LazyGNN: Large-Scale Graph Neural Networks via Lazy Propagation
Feb 03, 2023Recent works have demonstrated the benefits of capturing long-distance dependency in graphs by deeper graph neural networks (GNNs). But deeper GNNs suffer from the long-lasting scalability challenge due to the neighborhood explosion problem in large-scale graphs. In this work, we propose to capture long-distance dependency in graphs by shallower models instead of deeper models, which leads to a much more efficient model, LazyGNN, for graph representation learning. Moreover, we demonstrate that LazyGNN is compatible with existing scalable approaches (such as sampling methods) for further accelerations through the development of mini-batch LazyGNN. Comprehensive experiments demonstrate its superior prediction performance and scalability on large-scale benchmarks. LazyGNN also achieves state-of-art performance on the OGB leaderboard.