 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkMedBench: A Real-World Scenario Driven Benchmark for Evaluating Large Language Models
Mar 14, 2026While Large Language Models (LLMs) excel on standardized medical exams, high scores often fail to translate to high-quality responses for real-world medical queries. Current evaluations rely heavily on multiple-choice questions, failing to capture the unstructured, ambiguous, and long-tail complexities inherent in genuine user inquiries. To bridge this gap, we introduce QuarkMedBench, an ecologically valid benchmark tailored for real-world medical LLM assessment. We compiled a massive dataset spanning Clinical Care, Wellness Health, and Professional Inquiry, comprising 20,821 single-turn queries and 3,853 multi-turn sessions. To objectively evaluate open-ended answers, we propose an automated scoring framework that integrates multi-model consensus with evidence-based retrieval to dynamically generate 220,617 fine-grained scoring rubrics (~9.8 per query). During evaluation, hierarchical weighting and safety constraints structurally quantify medical accuracy, key-point coverage, and risk interception, effectively mitigating the high costs and subjectivity of human grading. Experimental results demonstrate that the generated rubrics achieve a 91.8% concordance rate with clinical expert blind audits, establishing highly dependable medical reliability. Crucially, baseline evaluations on this benchmark reveal significant performance disparities among state-of-the-art models when navigating real-world clinical nuances, highlighting the limitations of conventional exam-based metrics. Ultimately, QuarkMedBench establishes a rigorous, reproducible yardstick for measuring LLM performance on complex health issues, while its framework inherently supports dynamic knowledge updates to prevent benchmark obsolescence.
F10.7 Index Prediction: A Multiscale Decomposition Strategy with Wavelet Transform for Performance Optimization
Feb 24, 2026In this study, we construct Dataset A for training, validation, and testing, and Dataset B to evaluate generalization. We propose a novel F10.7 index forecasting method using wavelet decomposition, which feeds F10.7 together with its decomposed approximate and detail signals into the iTransformer model. We also incorporate the International Sunspot Number (ISN) and its wavelet-decomposed signals to assess their influence on prediction performance. Our optimal method is then compared with the latest method from S. Yan et al. (2025) and three operational models (SWPC, BGS, CLS). Additionally, we transfer our method to the PatchTST model used in H. Ye et al. (2024) and compare our method with theirs on Dataset B. Key findings include: (1) The wavelet-based combination methods overall outperform the baseline using only F10.7 index. The prediction performance improves as higher-level approximate and detail signals are incrementally added. The Combination 6 method integrating F10.7 with its first to fifth level approximate and detail signals outperforms methods using only approximate or detail signals. (2) Incorporating ISN and its wavelet-decomposed signals does not enhance prediction performance. (3) The Combination 6 method significantly surpasses S. Yan et al. (2025) and three operational models, with RMSE, MAE, and MAPE reduced by 18.22%, 15.09%, and 8.57%, respectively, against the former method. It also excels across four different conditions of solar activity. (4) Our method demonstrates superior generalization and prediction capability over the method of H. Ye et al. (2024) across all forecast horizons. To our knowledge, this is the first application of wavelet decomposition in F10.7 prediction, substantially improving forecast performance.
Prediction of Major Solar Flares Using Interpretable Class-dependent Reward Framework with Active Region Magnetograms and Domain Knowledge
Feb 18, 2026In this work, we develop, for the first time, a supervised classification framework with class-dependent rewards (CDR) to predict $\geq$MM flares within 24 hr. We construct multiple datasets, covering knowledge-informed features and line-of sight (LOS) magnetograms. We also apply three deep learning models (CNN, CNN-BiLSTM, and Transformer) and three CDR counterparts (CDR-CNN, CDR-CNN-BiLSTM, and CDR-Transformer). First, we analyze the importance of LOS magnetic field parameters with the Transformer, then compare its performance using LOS-only, vector-only, and combined magnetic field parameters. Second, we compare flare prediction performance based on CDR models versus deep learning counterparts. Third, we perform sensitivity analysis on reward engineering for CDR models. Fourth, we use the SHAP method for model interpretability. Finally, we conduct performance comparison between our models and NASA/CCMC. The main findings are: (1)Among LOS feature combinations, R_VALUE and AREA_ACR consistently yield the best results. (2)Transformer achieves better performance with combined LOS and vector magnetic field data than with either alone. (3)Models using knowledge-informed features outperform those using magnetograms. (4)While CNN and CNN-BiLSTM outperform their CDR counterparts on magnetograms, CDR-Transformer is slightly superior to its deep learning counterpart when using knowledge-informed features. Among all models, CDR-Transformer achieves the best performance. (5)The predictive performance of the CDR models is not overly sensitive to the reward choices.(6)Through SHAP analysis, the CDR model tends to regard TOTUSJH as more important, while the Transformer tends to prioritize R_VALUE more.(7)Under identical prediction time and active region (AR) number, the CDR-Transformer shows superior predictive capabilities compared to NASA/CCMC.
SFMP: Fine-Grained, Hardware-Friendly and Search-Free Mixed-Precision Quantization for Large Language Models
Feb 01, 2026Mixed-precision quantization is a promising approach for compressing large language models under tight memory budgets. However, existing mixed-precision methods typically suffer from one of two limitations: they either rely on expensive discrete optimization to determine precision allocation, or introduce hardware inefficiencies due to irregular memory layouts. We propose SFMP, a search-free and hardware-friendly mixed-precision quantization framework for large language models. The framework is built upon four novel ideas: Fractional bit-width, which extends integer bit-width for weight matrix to fractional value and transforms discrete precision allocation as a continuous problem; 2)Block-wise mixed-precision, enabling fine-grained precision within weight matrices while remaining hardware-friendly; 3)Row-column weight reordering, which aggregates salient weights via row and column reordering, incurring only a small activation reordering overhead during inference; 4)Unified GEMM kernel, which supports mixed-precision GEMM at arbitrary average bit-width. Extensive experiments demonstrate that SFMP outperforms state-of-the-art layer-wise mixed-precision methods under the same memory constraints, while significantly reducing quantization cost and improving inference efficiency. Code is available at https://github.com/Nkniexin/SFMP
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Enhancing Vehicular Platooning with Wireless Federated Learning: A Resource-Aware Control Framework
Jul 01, 2025This paper aims to enhance the performance of Vehicular Platooning (VP) systems integrated with Wireless Federated Learning (WFL). In highly dynamic environments, vehicular platoons experience frequent communication changes and resource constraints, which significantly affect information exchange and learning model synchronization. To address these challenges, we first formulate WFL in VP as a joint optimization problem that simultaneously considers Age of Information (AoI) and Federated Learning Model Drift (FLMD) to ensure timely and accurate control. Through theoretical analysis, we examine the impact of FLMD on convergence performance and develop a two-stage Resource-Aware Control framework (RACE). The first stage employs a Lagrangian dual decomposition method for resource configuration, while the second stage implements a multi-agent deep reinforcement learning approach for vehicle selection. The approach integrates Multi-Head Self-Attention and Long Short-Term Memory networks to capture spatiotemporal correlations in communication states. Experimental results demonstrate that, compared to baseline methods, the proposed framework improves AoI optimization by up to 45%, accelerates learning convergence, and adapts more effectively to dynamic VP environments on the AI4MARS dataset.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
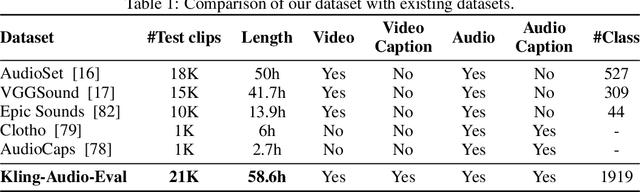
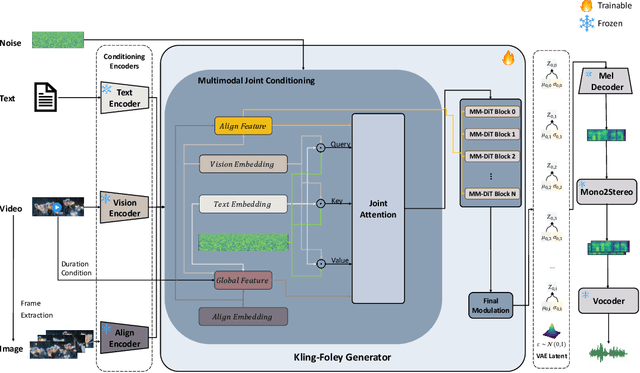
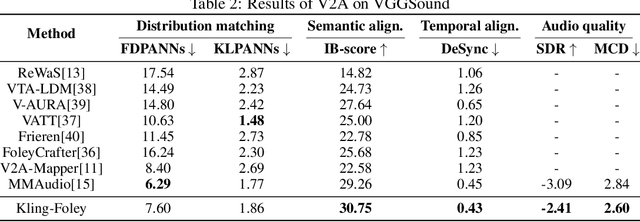
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.