 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidity Arguments For Constructed Response Scoring Using Generative Artificial Intelligence Applications
Jan 04, 2025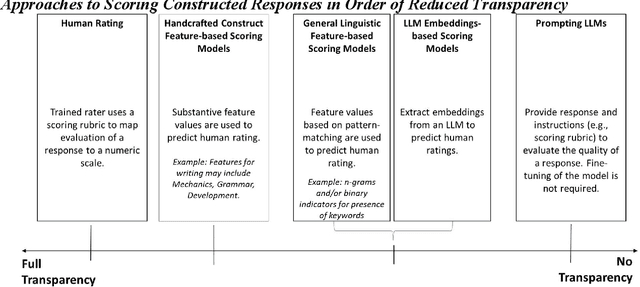
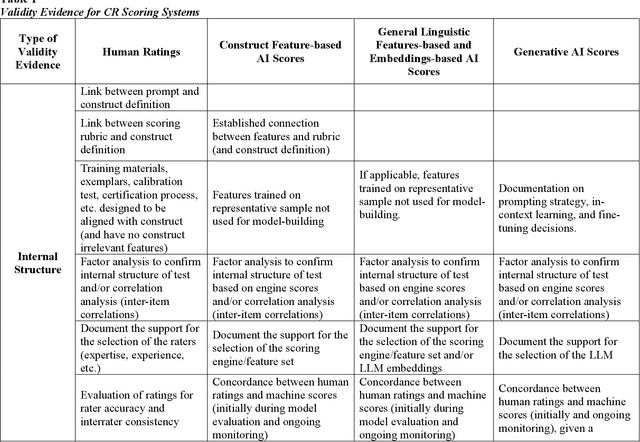
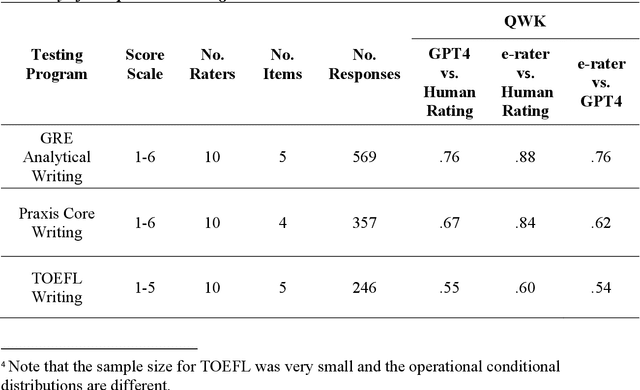
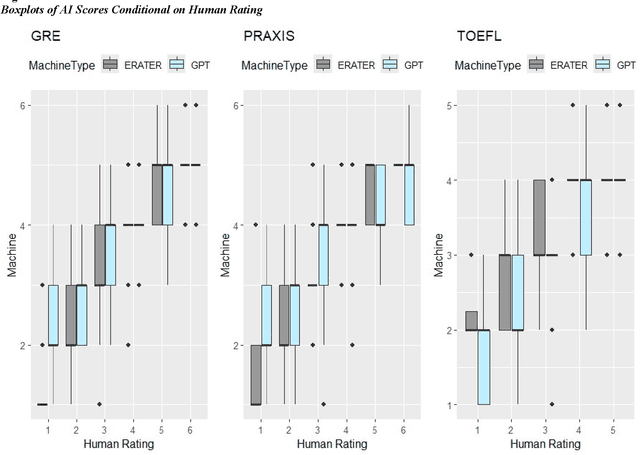
The rapid advancements in large language models and generative artificial intelligence (AI) capabilities are making their broad application in the high-stakes testing context more likely. Use of generative AI in the scoring of constructed responses is particularly appealing because it reduces the effort required for handcrafting features in traditional AI scoring and might even outperform those methods. The purpose of this paper is to highlight the differences in the feature-based and generative AI applications in constructed response scoring systems and propose a set of best practices for the collection of validity evidence to support the use and interpretation of constructed response scores from scoring systems using generative AI. We compare the validity evidence needed in scoring systems using human ratings, feature-based natural language processing AI scoring engines, and generative AI. The evidence needed in the generative AI context is more extensive than in the feature-based NLP scoring context because of the lack of transparency and other concerns unique to generative AI such as consistency. Constructed response score data from standardized tests demonstrate the collection of validity evidence for different types of scoring systems and highlights the numerous complexities and considerations when making a validity argument for these scores. In addition, we discuss how the evaluation of AI scores might include a consideration of how a contributory scoring approach combining multiple AI scores (from different sources) will cover more of the construct in the absence of human ratings.
The Rise of Artificial Intelligence in Educational Measurement: Opportunities and Ethical Challenges
Jun 27, 2024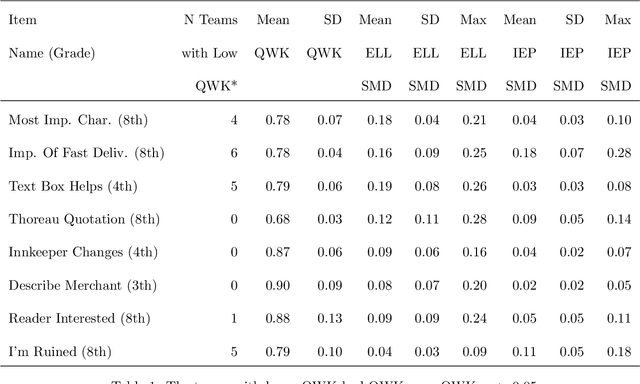
The integration of artificial intelligence (AI) in educational measurement has revolutionized assessment methods, enabling automated scoring, rapid content analysis, and personalized feedback through machine learning and natural language processing. These advancements provide timely, consistent feedback and valuable insights into student performance, thereby enhancing the assessment experience. However, the deployment of AI in education also raises significant ethical concerns regarding validity, reliability, transparency, fairness, and equity. Issues such as algorithmic bias and the opacity of AI decision-making processes pose risks of perpetuating inequalities and affecting assessment outcomes. Responding to these concerns, various stakeholders, including educators, policymakers, and organizations, have developed guidelines to ensure ethical AI use in education. The National Council of Measurement in Education's Special Interest Group on AI in Measurement and Education (AIME) also focuses on establishing ethical standards and advancing research in this area. In this paper, a diverse group of AIME members examines the ethical implications of AI-powered tools in educational measurement, explores significant challenges such as automation bias and environmental impact, and proposes solutions to ensure AI's responsible and effective use in education.