 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel-S$^2$fM: Structure from Motion on Neural Level Set of Implicit Surfaces
Paper and Code
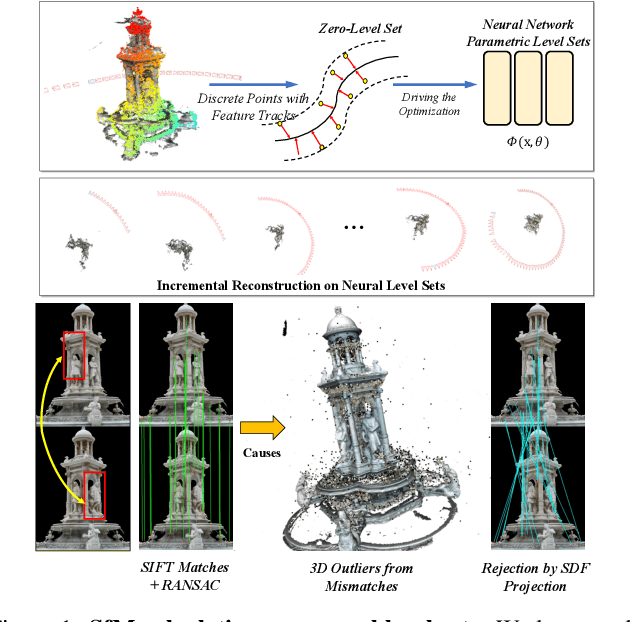
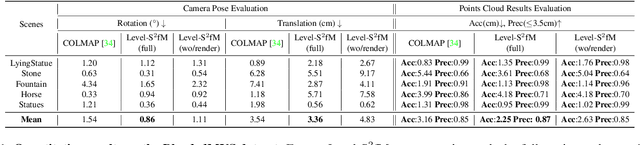
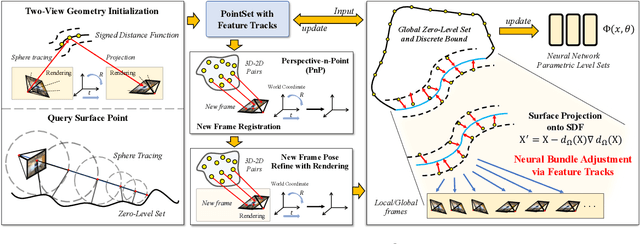
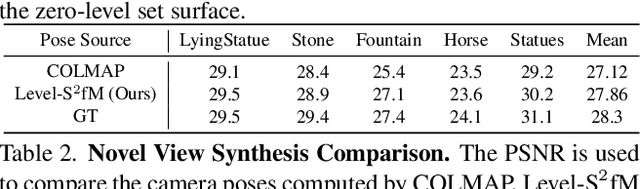
This paper presents a neural incremental Structure-from-Motion (SfM) approach, Level-S$^2$fM. In our formulation, we aim at simultaneously learning coordinate MLPs for the implicit surfaces and the radiance fields, and estimating the camera poses and scene geometry, which is mainly sourced from the established keypoint correspondences by SIFT. Our formulation would face some new challenges due to inevitable two-view and few-view configurations at the beginning of incremental SfM pipeline for the optimization of coordinate MLPs, but we found that the strong inductive biases conveying in the 2D correspondences are feasible and promising to avoid those challenges by exploiting the relationship between the ray sampling schemes used in volumetric rendering and the sphere tracing of finding the zero-level set of implicit surfaces. Based on this, we revisit the pipeline of incremental SfM and renew the key components of two-view geometry initialization, the camera pose registration, and the 3D points triangulation, as well as the Bundle Adjustment in a novel perspective of neural implicit surfaces. Because the coordinate MLPs unified the scene geometry in small MLP networks, our Level-S$^2$fM treats the zero-level set of the implicit surface as an informative top-down regularization to manage the reconstructed 3D points, reject the outlier of correspondences by querying SDF, adjust the estimated geometries by NBA (Neural BA), finally yielding promising results of 3D reconstruction. Furthermore, our Level-S$^2$fM alleviated the requirement of camera poses for neural 3D reconstruction.