 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Guided Face Generation with Multi-modal Contour Conditions
Paper and Code

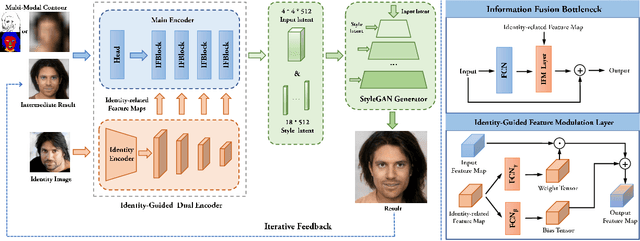
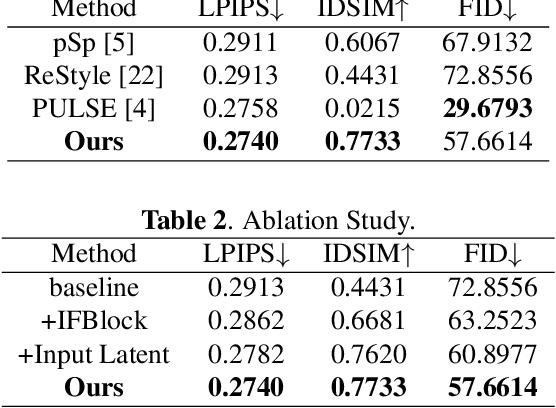

Recent face generation methods have tried to synthesize faces based on the given contour condition, like a low-resolution image or a sketch. However, the problem of identity ambiguity remains unsolved, which usually occurs when the contour is too vague to provide reliable identity information (e.g., when its resolution is extremely low). In this work, we propose a framework that takes the contour and an extra image specifying the identity as the inputs, where the contour can be of various modalities, including the low-resolution image, sketch, and semantic label map. This task especially fits the situation of tracking the known criminals or making intelligent creations for entertainment. Concretely, we propose a novel dual-encoder architecture, in which an identity encoder extracts the identity-related feature, accompanied by a main encoder to obtain the rough contour information and further fuse all the information together. The encoder output is iteratively fed into a pre-trained StyleGAN generator until getting a satisfying result. To the best of our knowledge, this is the first work that achieves identity-guided face generation conditioned on multi-modal contour images. Moreover, our method can produce photo-realistic results with 1024$\times$1024 resolution. Code will be available at https://git.io/Jo4yh.