 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiFT: Differentiable Differential Feature Transform for Multi-View Stereo
Paper and Code
Mar 16, 2022
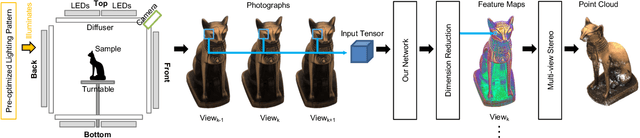
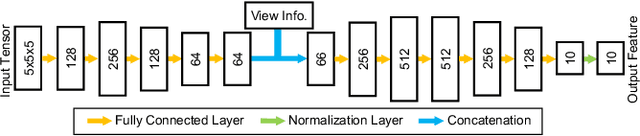

We present a novel framework to automatically learn to transform the differential cues from a stack of images densely captured with a rotational motion into spatially discriminative and view-invariant per-pixel features at each view. These low-level features can be directly fed to any existing multi-view stereo technique for enhanced 3D reconstruction. The lighting condition during acquisition can also be jointly optimized in a differentiable fashion. We sample from a dozen of pre-scanned objects with a wide variety of geometry and reflectance to synthesize a large amount of high-quality training data. The effectiveness of our features is demonstrated on a number of challenging objects acquired with a lightstage, comparing favorably with state-of-the-art techniques. Finally, we explore additional applications of geometric detail visualization and computational stylization of complex appearance.