 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Embodied Perception in Dynamic Environments via Disentangled Weight Fusion
Apr 02, 2026Embodied perception systems face severe challenges of dynamic environment distribution drift when they continuously interact in open physical spaces. However, the existing domain incremental awareness methods often rely on the domain id obtained in advance during the testing phase, which limits their practicability in unknown interaction scenarios. At the same time, the model often overfits to the context-specific perceptual noise, which leads to insufficient generalization ability and catastrophic forgetting. To address these limitations, we propose a domain-id and exemplar-free incremental learning framework for embodied multimedia systems, which aims to achieve robust continuous environment adaptation. This method designs a disentangled representation mechanism to remove non-essential environmental style interference, and guide the model to focus on extracting semantic intrinsic features shared across scenes, thereby eliminating perceptual uncertainty and improving generalization. We further use the weight fusion strategy to dynamically integrate the old and new environment knowledge in the parameter space, so as to ensure that the model adapts to the new distribution without storing historical data and maximally retains the discrimination ability of the old environment. Extensive experiments on multiple standard benchmark datasets show that the proposed method significantly reduces catastrophic forgetting in a completely exemplar-free and domain-id free setting, and its accuracy is better than the existing state-of-the-art methods.
Embracing Aleatoric Uncertainty in Medical Multimodal Learning with Missing Modalities
Jan 29, 2026Medical multimodal learning faces significant challenges with missing modalities prevalent in clinical practice. Existing approaches assume equal contribution of modality and random missing patterns, neglecting inherent uncertainty in medical data acquisition. In this regard, we propose the Aleatoric Uncertainty Modeling (AUM) that explicitly quantifies unimodal aleatoric uncertainty to address missing modalities. Specifically, AUM models each unimodal representation as a multivariate Gaussian distribution to capture aleatoric uncertainty and enable principled modality reliability quantification. To adaptively aggregate captured information, we develop a dynamic message-passing mechanism within a bipartite patient-modality graph using uncertainty-aware aggregation mechanism. Through this process, missing modalities are naturally accommodated, while more reliable information from available modalities is dynamically emphasized to guide representation generation. Our AUM framework achieves an improvement of 2.26% AUC-ROC on MIMIC-IV mortality prediction and 2.17% gain on eICU, outperforming existing state-of-the-art approaches.
Robust Multimodal Representation Learning in Healthcare
Jan 29, 2026Medical multimodal representation learning aims to integrate heterogeneous data into unified patient representations to support clinical outcome prediction. However, real-world medical datasets commonly contain systematic biases from multiple sources, which poses significant challenges for medical multimodal representation learning. Existing approaches typically focus on effective multimodal fusion, neglecting inherent biased features that affect the generalization ability. To address these challenges, we propose a Dual-Stream Feature Decorrelation Framework that identifies and handles the biases through structural causal analysis introduced by latent confounders. Our method employs a causal-biased decorrelation framework with dual-stream neural networks to disentangle causal features from spurious correlations, utilizing generalized cross-entropy loss and mutual information minimization for effective decorrelation. The framework is model-agnostic and can be integrated into existing medical multimodal learning methods. Comprehensive experiments on MIMIC-IV, eICU, and ADNI datasets demonstrate consistent performance improvements.
Adaptive Weighted Parameter Fusion with CLIP for Class-Incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables the model to incrementally absorb knowledge from new classes and build a generic classifier across all previously encountered classes. When the model optimizes with new classes, the knowledge of previous classes is inevitably erased, leading to catastrophic forgetting. Addressing this challenge requires making a trade-off between retaining old knowledge and accommodating new information. However, this balancing process often requires sacrificing some information, which can lead to a partial loss in the model's ability to discriminate between classes. To tackle this issue, we design the adaptive weighted parameter fusion with Contrastive Language-Image Pre-training (CLIP), which not only takes into account the variability of the data distribution of different tasks, but also retains all the effective information of the parameter matrix to the greatest extent. In addition, we introduce a balance factor that can balance the data distribution alignment and distinguishability of adjacent tasks. Experimental results on several traditional benchmarks validate the superiority of the proposed method.
Feature Calibration enhanced Parameter Synthesis for CLIP-based Class-incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables models to continuously learn new class knowledge while memorizing previous classes, facilitating their adaptation and evolution in dynamic environments. Traditional CIL methods are mainly based on visual features, which limits their ability to handle complex scenarios. In contrast, Vision-Language Models (VLMs) show promising potential to promote CIL by integrating pretrained knowledge with textual features. However, previous methods make it difficult to overcome catastrophic forgetting while preserving the generalization capabilities of VLMs. To tackle these challenges, we propose Feature Calibration enhanced Parameter Synthesis (FCPS) in this paper. Specifically, our FCPS employs a specific parameter adjustment mechanism to iteratively refine the proportion of original visual features participating in the final class determination, ensuring the model's foundational generalization capabilities. Meanwhile, parameter integration across different tasks achieves a balance between learning new class knowledge and retaining old knowledge. Experimental results on popular benchmarks (e.g., CIFAR100 and ImageNet100) validate the superiority of the proposed method.
CRCL: Causal Representation Consistency Learning for Anomaly Detection in Surveillance Videos
Mar 24, 2025Video Anomaly Detection (VAD) remains a fundamental yet formidable task in the video understanding community, with promising applications in areas such as information forensics and public safety protection. Due to the rarity and diversity of anomalies, existing methods only use easily collected regular events to model the inherent normality of normal spatial-temporal patterns in an unsupervised manner. Previous studies have shown that existing unsupervised VAD models are incapable of label-independent data offsets (e.g., scene changes) in real-world scenarios and may fail to respond to light anomalies due to the overgeneralization of deep neural networks. Inspired by causality learning, we argue that there exist causal factors that can adequately generalize the prototypical patterns of regular events and present significant deviations when anomalous instances occur. In this regard, we propose Causal Representation Consistency Learning (CRCL) to implicitly mine potential scene-robust causal variable in unsupervised video normality learning. Specifically, building on the structural causal models, we propose scene-debiasing learning and causality-inspired normality learning to strip away entangled scene bias in deep representations and learn causal video normality, respectively. Extensive experiments on benchmarks validate the superiority of our method over conventional deep representation learning. Moreover, ablation studies and extension validation show that the CRCL can cope with label-independent biases in multi-scene settings and maintain stable performance with only limited training data available.
A Survey on Video Analytics in Cloud-Edge-Terminal Collaborative Systems
Feb 10, 2025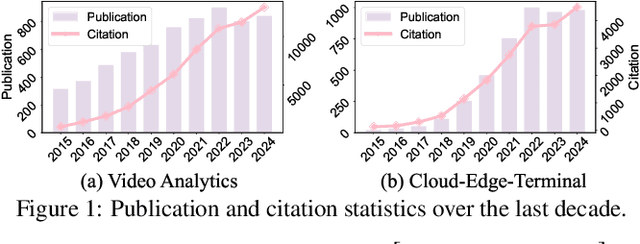
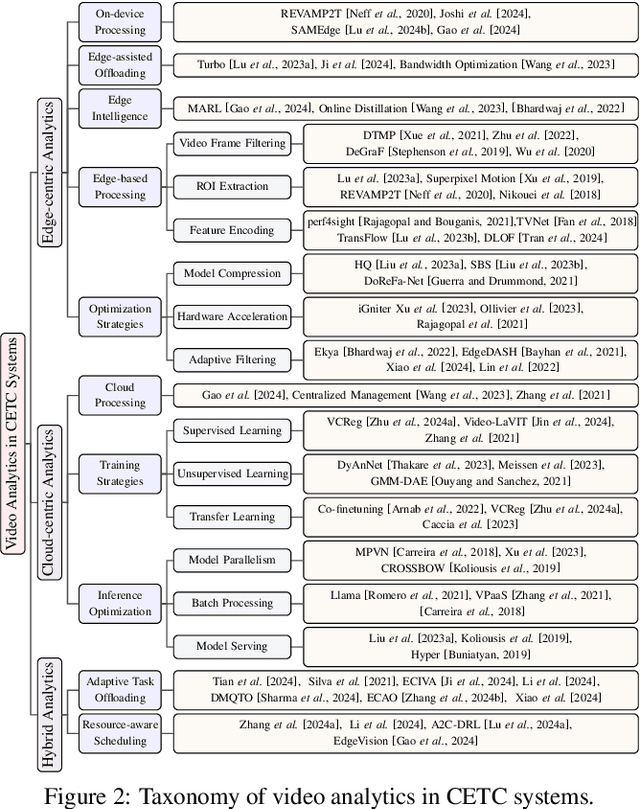
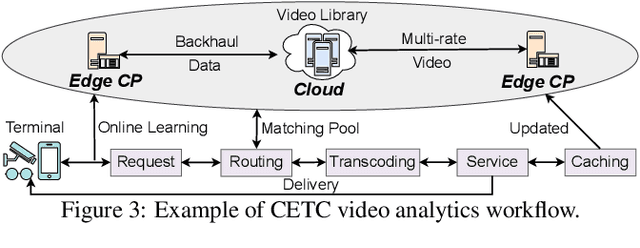
The explosive growth of video data has driven the development of distributed video analytics in cloud-edge-terminal collaborative (CETC) systems, enabling efficient video processing, real-time inference, and privacy-preserving analysis. Among multiple advantages, CETC systems can distribute video processing tasks and enable adaptive analytics across cloud, edge, and terminal devices, leading to breakthroughs in video surveillance, autonomous driving, and smart cities. In this survey, we first analyze fundamental architectural components, including hierarchical, distributed, and hybrid frameworks, alongside edge computing platforms and resource management mechanisms. Building upon these foundations, edge-centric approaches emphasize on-device processing, edge-assisted offloading, and edge intelligence, while cloud-centric methods leverage powerful computational capabilities for complex video understanding and model training. Our investigation also covers hybrid video analytics incorporating adaptive task offloading and resource-aware scheduling techniques that optimize performance across the entire system. Beyond conventional approaches, recent advances in large language models and multimodal integration reveal both opportunities and challenges in platform scalability, data protection, and system reliability. Future directions also encompass explainable systems, efficient processing mechanisms, and advanced video analytics, offering valuable insights for researchers and practitioners in this dynamic field.
Privacy-Preserving Video Anomaly Detection: A Survey
Nov 21, 2024



Video Anomaly Detection (VAD) aims to automatically analyze spatiotemporal patterns in surveillance videos collected from open spaces to detect anomalous events that may cause harm without physical contact. However, vision-based surveillance systems such as closed-circuit television often capture personally identifiable information. The lack of transparency and interpretability in video transmission and usage raises public concerns about privacy and ethics, limiting the real-world application of VAD. Recently, researchers have focused on privacy concerns in VAD by conducting systematic studies from various perspectives including data, features, and systems, making Privacy-Preserving Video Anomaly Detection (P2VAD) a hotspot in the AI community. However, current research in P2VAD is fragmented, and prior reviews have mostly focused on methods using RGB sequences, overlooking privacy leakage and appearance bias considerations. To address this gap, this article systematically reviews the progress of P2VAD for the first time, defining its scope and providing an intuitive taxonomy. We outline the basic assumptions, learning frameworks, and optimization objectives of various approaches, analyzing their strengths, weaknesses, and potential correlations. Additionally, we provide open access to research resources such as benchmark datasets and available code. Finally, we discuss key challenges and future opportunities from the perspectives of AI development and P2VAD deployment, aiming to guide future work in the field.
Learning Appearance-motion Normality for Video Anomaly Detection
Jul 27, 2022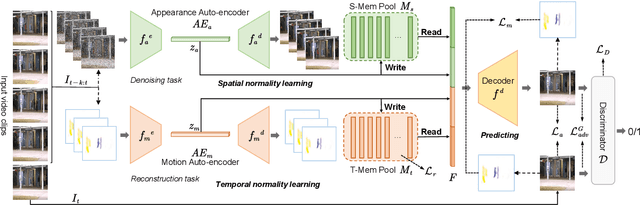
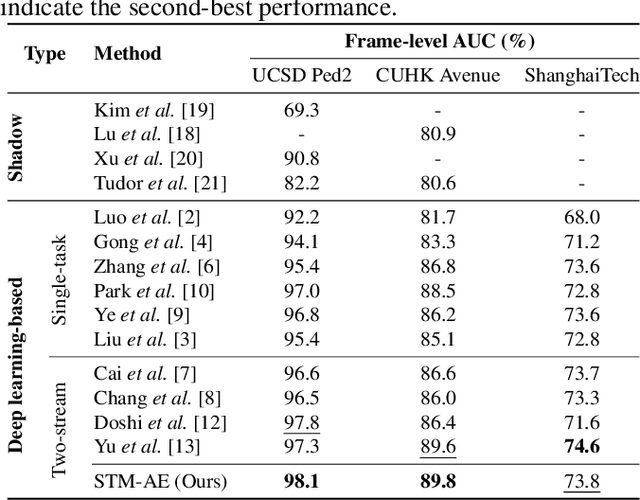

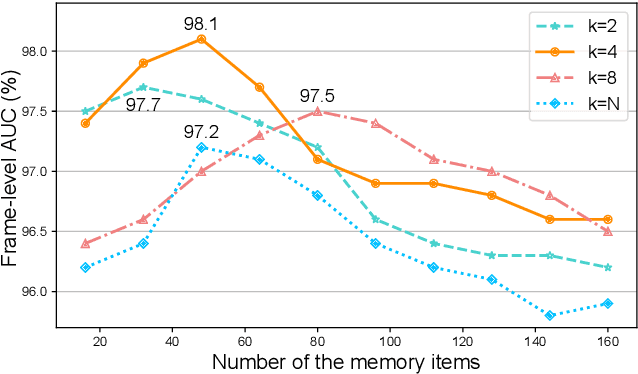
Video anomaly detection is a challenging task in the computer vision community. Most single task-based methods do not consider the independence of unique spatial and temporal patterns, while two-stream structures lack the exploration of the correlations. In this paper, we propose spatial-temporal memories augmented two-stream auto-encoder framework, which learns the appearance normality and motion normality independently and explores the correlations via adversarial learning. Specifically, we first design two proxy tasks to train the two-stream structure to extract appearance and motion features in isolation. Then, the prototypical features are recorded in the corresponding spatial and temporal memory pools. Finally, the encoding-decoding network performs adversarial learning with the discriminator to explore the correlations between spatial and temporal patterns. Experimental results show that our framework outperforms the state-of-the-art methods, achieving AUCs of 98.1% and 89.8% on UCSD Ped2 and CUHK Avenue datasets.
Rethinking Saliency Map: An Context-aware Perturbation Method to Explain EEG-based Deep Learning Model
May 30, 2022
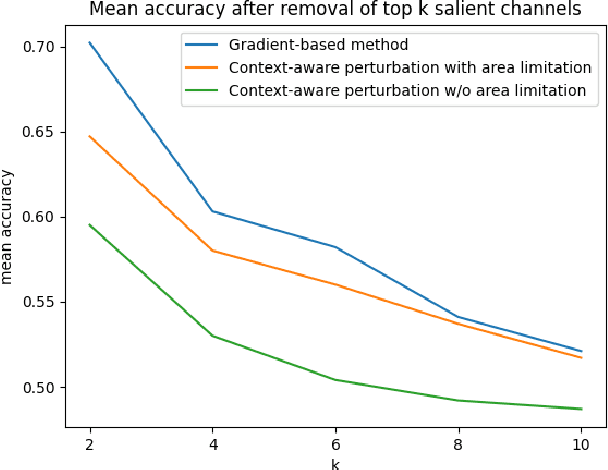
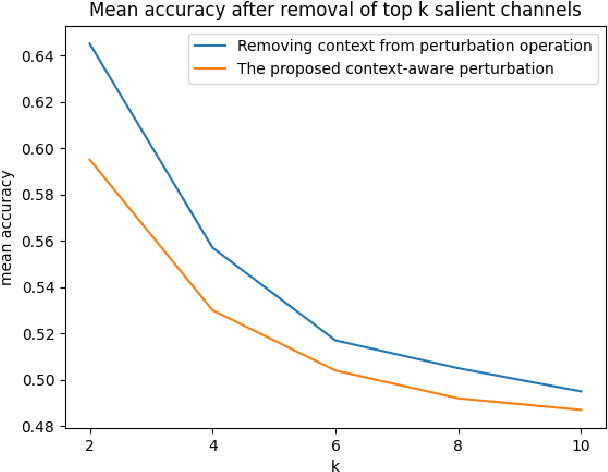
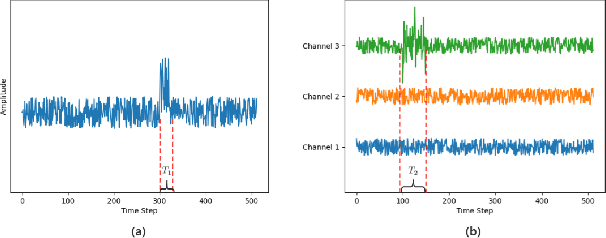
Deep learning is widely used to decode the electroencephalogram (EEG) signal. However, there are few attempts to specifically investigate how to explain the EEG-based deep learning models. We conduct a review to summarize the existing works explaining the EEG-based deep learning model. Unfortunately, we find that there is no appropriate method to explain them. Based on the characteristic of EEG data, we suggest a context-aware perturbation method to generate a saliency map from the perspective of the raw EEG signal. Moreover, we also justify that the context information can be used to suppress the artifacts in the EEG-based deep learning model. In practice, some users might want a simple version of the explanation, which only indicates a few features as salient points. To this end, we propose an optional area limitation strategy to restrict the highlighted region. To validate our idea and make a comparison with the other methods, we select three representative EEG-based models to implement experiments on the emotional EEG dataset DEAP. The results of the experiments support the advantages of our method.