 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Representation Learning in Healthcare
Jan 29, 2026Medical multimodal representation learning aims to integrate heterogeneous data into unified patient representations to support clinical outcome prediction. However, real-world medical datasets commonly contain systematic biases from multiple sources, which poses significant challenges for medical multimodal representation learning. Existing approaches typically focus on effective multimodal fusion, neglecting inherent biased features that affect the generalization ability. To address these challenges, we propose a Dual-Stream Feature Decorrelation Framework that identifies and handles the biases through structural causal analysis introduced by latent confounders. Our method employs a causal-biased decorrelation framework with dual-stream neural networks to disentangle causal features from spurious correlations, utilizing generalized cross-entropy loss and mutual information minimization for effective decorrelation. The framework is model-agnostic and can be integrated into existing medical multimodal learning methods. Comprehensive experiments on MIMIC-IV, eICU, and ADNI datasets demonstrate consistent performance improvements.
Embracing Aleatoric Uncertainty in Medical Multimodal Learning with Missing Modalities
Jan 29, 2026Medical multimodal learning faces significant challenges with missing modalities prevalent in clinical practice. Existing approaches assume equal contribution of modality and random missing patterns, neglecting inherent uncertainty in medical data acquisition. In this regard, we propose the Aleatoric Uncertainty Modeling (AUM) that explicitly quantifies unimodal aleatoric uncertainty to address missing modalities. Specifically, AUM models each unimodal representation as a multivariate Gaussian distribution to capture aleatoric uncertainty and enable principled modality reliability quantification. To adaptively aggregate captured information, we develop a dynamic message-passing mechanism within a bipartite patient-modality graph using uncertainty-aware aggregation mechanism. Through this process, missing modalities are naturally accommodated, while more reliable information from available modalities is dynamically emphasized to guide representation generation. Our AUM framework achieves an improvement of 2.26% AUC-ROC on MIMIC-IV mortality prediction and 2.17% gain on eICU, outperforming existing state-of-the-art approaches.
A Survey on Video Analytics in Cloud-Edge-Terminal Collaborative Systems
Feb 10, 2025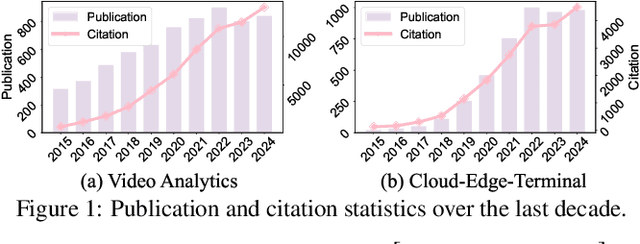
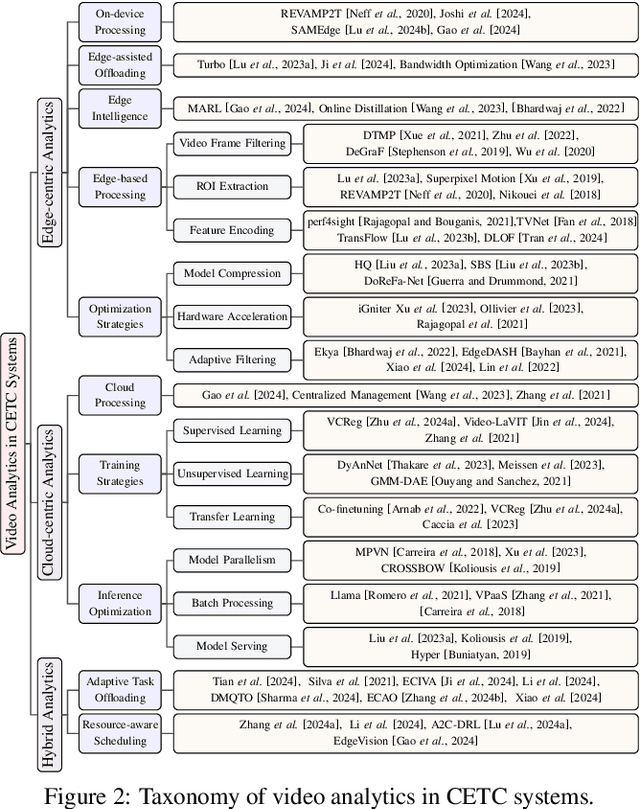
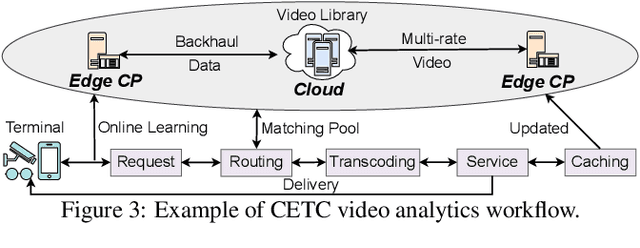
The explosive growth of video data has driven the development of distributed video analytics in cloud-edge-terminal collaborative (CETC) systems, enabling efficient video processing, real-time inference, and privacy-preserving analysis. Among multiple advantages, CETC systems can distribute video processing tasks and enable adaptive analytics across cloud, edge, and terminal devices, leading to breakthroughs in video surveillance, autonomous driving, and smart cities. In this survey, we first analyze fundamental architectural components, including hierarchical, distributed, and hybrid frameworks, alongside edge computing platforms and resource management mechanisms. Building upon these foundations, edge-centric approaches emphasize on-device processing, edge-assisted offloading, and edge intelligence, while cloud-centric methods leverage powerful computational capabilities for complex video understanding and model training. Our investigation also covers hybrid video analytics incorporating adaptive task offloading and resource-aware scheduling techniques that optimize performance across the entire system. Beyond conventional approaches, recent advances in large language models and multimodal integration reveal both opportunities and challenges in platform scalability, data protection, and system reliability. Future directions also encompass explainable systems, efficient processing mechanisms, and advanced video analytics, offering valuable insights for researchers and practitioners in this dynamic field.