 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Weighted Parameter Fusion with CLIP for Class-Incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables the model to incrementally absorb knowledge from new classes and build a generic classifier across all previously encountered classes. When the model optimizes with new classes, the knowledge of previous classes is inevitably erased, leading to catastrophic forgetting. Addressing this challenge requires making a trade-off between retaining old knowledge and accommodating new information. However, this balancing process often requires sacrificing some information, which can lead to a partial loss in the model's ability to discriminate between classes. To tackle this issue, we design the adaptive weighted parameter fusion with Contrastive Language-Image Pre-training (CLIP), which not only takes into account the variability of the data distribution of different tasks, but also retains all the effective information of the parameter matrix to the greatest extent. In addition, we introduce a balance factor that can balance the data distribution alignment and distinguishability of adjacent tasks. Experimental results on several traditional benchmarks validate the superiority of the proposed method.
Feature Calibration enhanced Parameter Synthesis for CLIP-based Class-incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables models to continuously learn new class knowledge while memorizing previous classes, facilitating their adaptation and evolution in dynamic environments. Traditional CIL methods are mainly based on visual features, which limits their ability to handle complex scenarios. In contrast, Vision-Language Models (VLMs) show promising potential to promote CIL by integrating pretrained knowledge with textual features. However, previous methods make it difficult to overcome catastrophic forgetting while preserving the generalization capabilities of VLMs. To tackle these challenges, we propose Feature Calibration enhanced Parameter Synthesis (FCPS) in this paper. Specifically, our FCPS employs a specific parameter adjustment mechanism to iteratively refine the proportion of original visual features participating in the final class determination, ensuring the model's foundational generalization capabilities. Meanwhile, parameter integration across different tasks achieves a balance between learning new class knowledge and retaining old knowledge. Experimental results on popular benchmarks (e.g., CIFAR100 and ImageNet100) validate the superiority of the proposed method.
A Survey on Video Analytics in Cloud-Edge-Terminal Collaborative Systems
Feb 10, 2025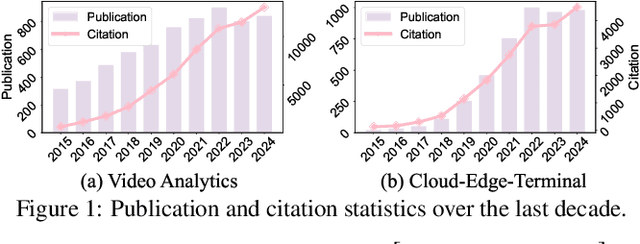
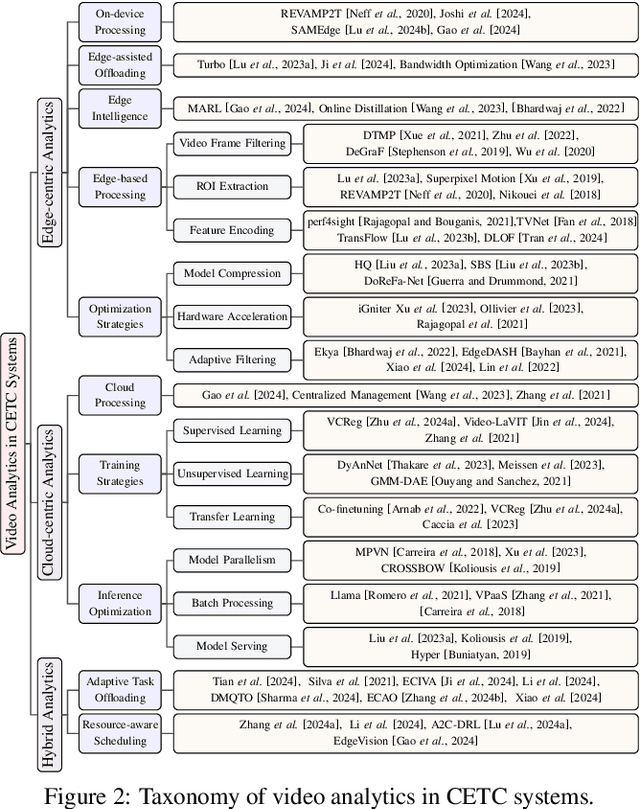
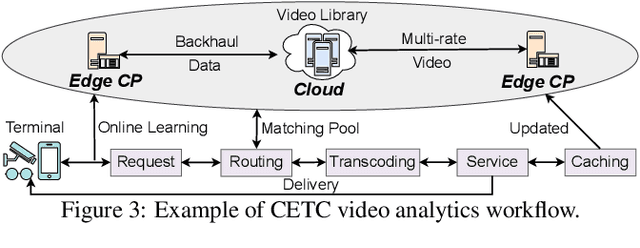
The explosive growth of video data has driven the development of distributed video analytics in cloud-edge-terminal collaborative (CETC) systems, enabling efficient video processing, real-time inference, and privacy-preserving analysis. Among multiple advantages, CETC systems can distribute video processing tasks and enable adaptive analytics across cloud, edge, and terminal devices, leading to breakthroughs in video surveillance, autonomous driving, and smart cities. In this survey, we first analyze fundamental architectural components, including hierarchical, distributed, and hybrid frameworks, alongside edge computing platforms and resource management mechanisms. Building upon these foundations, edge-centric approaches emphasize on-device processing, edge-assisted offloading, and edge intelligence, while cloud-centric methods leverage powerful computational capabilities for complex video understanding and model training. Our investigation also covers hybrid video analytics incorporating adaptive task offloading and resource-aware scheduling techniques that optimize performance across the entire system. Beyond conventional approaches, recent advances in large language models and multimodal integration reveal both opportunities and challenges in platform scalability, data protection, and system reliability. Future directions also encompass explainable systems, efficient processing mechanisms, and advanced video analytics, offering valuable insights for researchers and practitioners in this dynamic field.