 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton Sequence and RGB Frame Based Multi-Modality Feature Fusion Network for Action Recognition
Paper and Code
Feb 23, 2022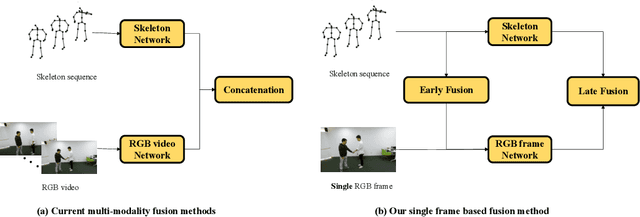
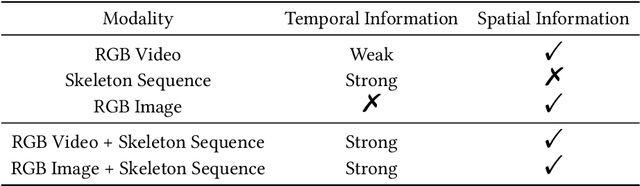
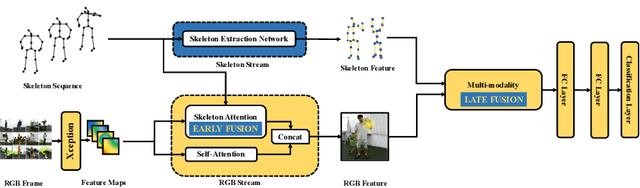
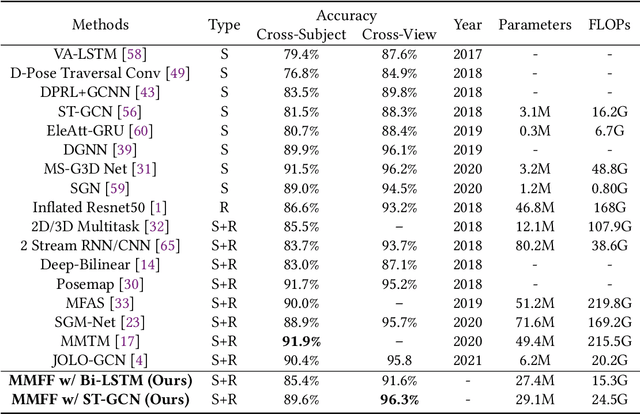
Action recognition has been a heated topic in computer vision for its wide application in vision systems. Previous approaches achieve improvement by fusing the modalities of the skeleton sequence and RGB video. However, such methods have a dilemma between the accuracy and efficiency for the high complexity of the RGB video network. To solve the problem, we propose a multi-modality feature fusion network to combine the modalities of the skeleton sequence and RGB frame instead of the RGB video, as the key information contained by the combination of skeleton sequence and RGB frame is close to that of the skeleton sequence and RGB video. In this way, the complementary information is retained while the complexity is reduced by a large margin. To better explore the correspondence of the two modalities, a two-stage fusion framework is introduced in the network. In the early fusion stage, we introduce a skeleton attention module that projects the skeleton sequence on the single RGB frame to help the RGB frame focus on the limb movement regions. In the late fusion stage, we propose a cross-attention module to fuse the skeleton feature and the RGB feature by exploiting the correlation. Experiments on two benchmarks NTU RGB+D and SYSU show that the proposed model achieves competitive performance compared with the state-of-the-art methods while reduces the complexity of the network.