 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Matched Collage Generation for Underwater Invertebrate Detection
Nov 15, 2022The quality and size of training sets often limit the performance of many state of the art object detectors. However, in many scenarios, it can be difficult to collect images for training, not to mention the costs associated with collecting annotations suitable for training these object detectors. For these reasons, on challenging video datasets such as the Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), budgets may only allow for collecting and providing partial annotations. To aid in the challenges associated with training with limited and partial annotations, we introduce Context Matched Collages, which leverage explicit context labels to combine unused background examples with existing annotated data to synthesize additional training samples that ultimately improve object detection performance. By combining a set of our generated collage images with the original training set, we see improved performance using three different object detectors on DUSIA, ultimately achieving state of the art object detection performance on the dataset.
Context-Driven Detection of Invertebrate Species in Deep-Sea Video
Jun 01, 2022

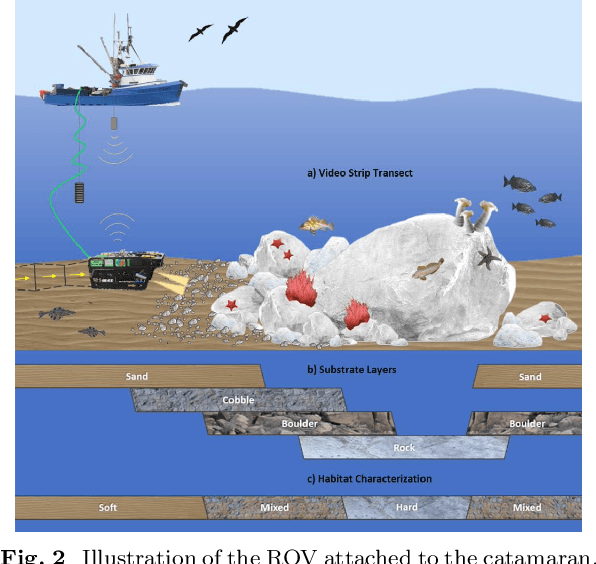
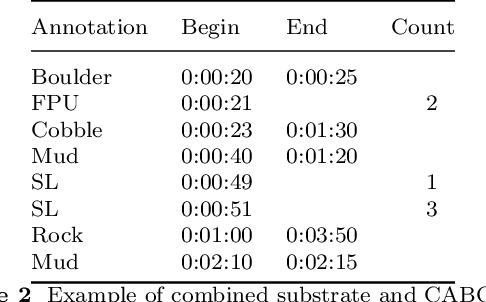
Each year, underwater remotely operated vehicles (ROVs) collect thousands of hours of video of unexplored ocean habitats revealing a plethora of information regarding biodiversity on Earth. However, fully utilizing this information remains a challenge as proper annotations and analysis require trained scientists time, which is both limited and costly. To this end, we present a Dataset for Underwater Substrate and Invertebrate Analysis (DUSIA), a benchmark suite and growing large-scale dataset to train, validate, and test methods for temporally localizing four underwater substrates as well as temporally and spatially localizing 59 underwater invertebrate species. DUSIA currently includes over ten hours of footage across 25 videos captured in 1080p at 30 fps by an ROV following pre planned transects across the ocean floor near the Channel Islands of California. Each video includes annotations indicating the start and end times of substrates across the video in addition to counts of species of interest. Some frames are annotated with precise bounding box locations for invertebrate species of interest, as seen in Figure 1. To our knowledge, DUSIA is the first dataset of its kind for deep sea exploration, with video from a moving camera, that includes substrate annotations and invertebrate species that are present at significant depths where sunlight does not penetrate. Additionally, we present the novel context-driven object detector (CDD) where we use explicit substrate classification to influence an object detection network to simultaneously predict a substrate and species class influenced by that substrate. We also present a method for improving training on partially annotated bounding box frames. Finally, we offer a baseline method for automating the counting of invertebrate species of interest.
GTNet:Guided Transformer Network for Detecting Human-Object Interactions
Aug 03, 2021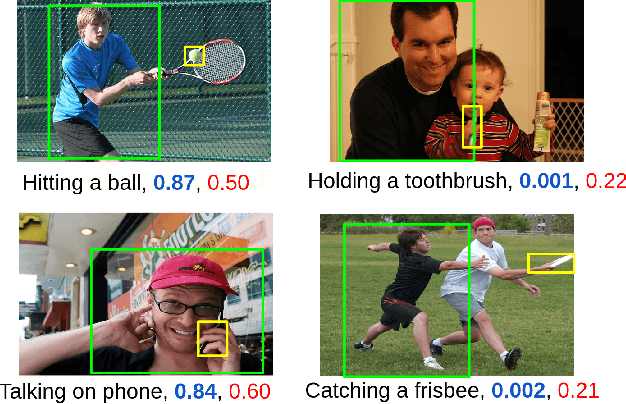
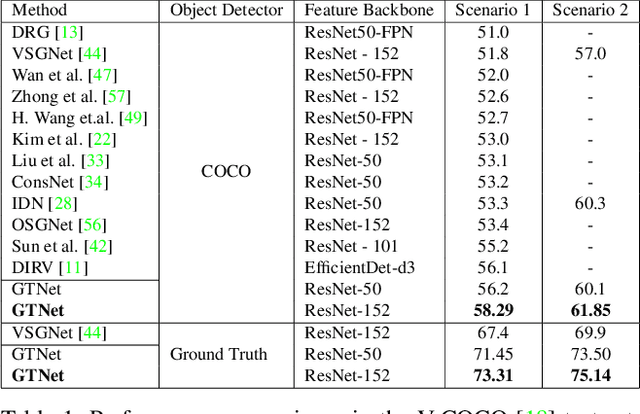
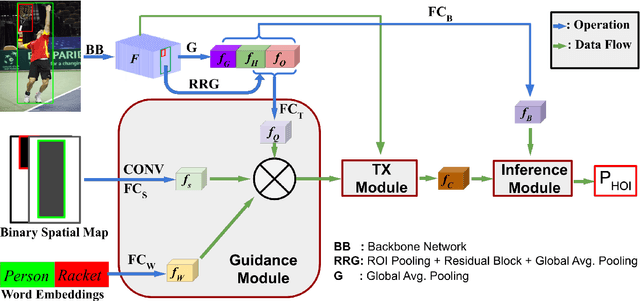
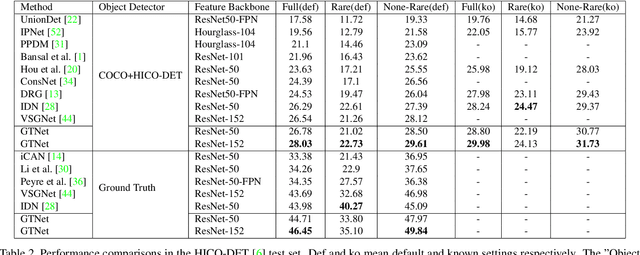
The human-object interaction (HOI) detection task refers to localizing humans, localizing objects, and predicting the interactions between each human-object pair. HOI is considered one of the fundamental steps in truly understanding complex visual scenes. For detecting HOI, it is important to utilize relative spatial configurations and object semantics to find salient spatial regions of images that highlight the interactions between human object pairs. This issue is addressed by the proposed self-attention based guided transformer network, GTNet. GTNet encodes this spatial contextual information in human and object visual features via self-attention while achieving a 4%-6% improvement over previous state of the art results on both the V-COCO and HICO-DET datasets. Code will be made available online.
PCAMs: Weakly Supervised Semantic Segmentation Using Point Supervision
Jul 10, 2020



Current state of the art methods for generating semantic segmentation rely heavily on a large set of images that have each pixel labeled with a class of interest label or background. Coming up with such labels, especially in domains that require an expert to do annotations, comes at a heavy cost in time and money. Several methods have shown that we can learn semantic segmentation from less expensive image-level labels, but the effectiveness of point level labels, a healthy compromise between all pixels labelled and none, still remains largely unexplored. This paper presents a novel procedure for producing semantic segmentation from images given some point level annotations. This method includes point annotations in the training of a convolutional neural network (CNN) for producing improved localization and class activation maps. Then, we use another CNN for predicting semantic affinities in order to propagate rough class labels and create pseudo semantic segmentation labels. Finally, we propose training a CNN that is normally fully supervised using our pseudo labels in place of ground truth labels, which further improves performance and simplifies the inference process by requiring just one CNN during inference rather than two. Our method achieves state of the art results for point supervised semantic segmentation on the PASCAL VOC 2012 dataset \cite{everingham2010pascal}, even outperforming state of the art methods for stronger bounding box and squiggle supervision.