 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
Mar 11, 2020

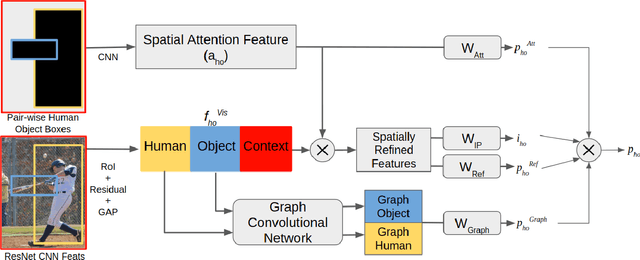

Comprehensive visual understanding requires detection frameworks that can effectively learn and utilize object interactions while analyzing objects individually. This is the main objective in Human-Object Interaction (HOI) detection task. In particular, relative spatial reasoning and structural connections between objects are essential cues for analyzing interactions, which is addressed by the proposed Visual-Spatial-Graph Network (VSGNet) architecture. VSGNet extracts visual features from the human-object pairs, refines the features with spatial configurations of the pair, and utilizes the structural connections between the pair via graph convolutions. The performance of VSGNet is thoroughly evaluated using the Verbs in COCO (V-COCO) and HICO-DET datasets. Experimental results indicate that VSGNet outperforms state-of-the-art solutions by 8% or 4 mAP in V-COCO and 16% or 3 mAP in HICO-DET.
Actor Conditioned Attention Maps for Video Action Detection
Dec 30, 2018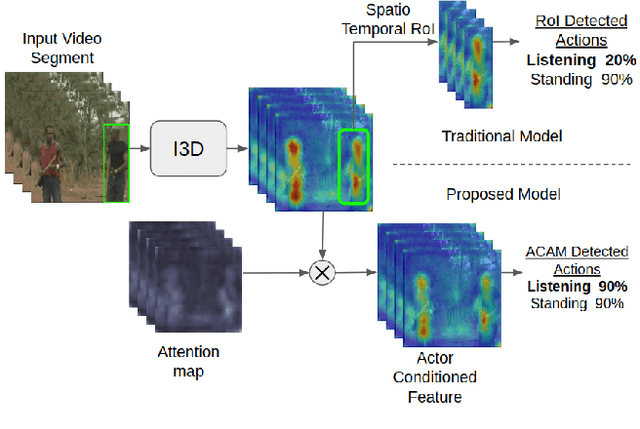
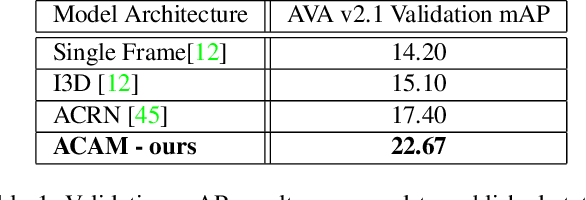

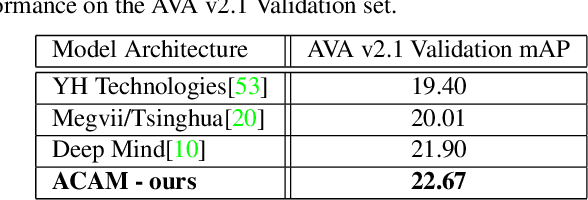
Interactions with surrounding objects and people contain important information towards understanding human actions. In order to model such interactions explicitly, we propose to generate attention maps that rank each spatio-temporal region's importance to a detected actor. We refer to these as Actor-Conditioned Attention Maps (ACAM), and these maps serve as weights to the features extracted from the whole scene. These resulting actor-conditioned features help focus the learned model on regions that are important/relevant to the conditioned actor. Another novelty of our approach is in the use of pre-trained object detectors, instead of region proposals, that generalize better to videos from different sources. Detailed experimental results on the AVA 2.1 datasets demonstrate the importance of interactions, with a performance improvement of 5 mAP with respect to state of the art published results.
Object Localization and Size Estimation from RGB-D Images
Aug 02, 2018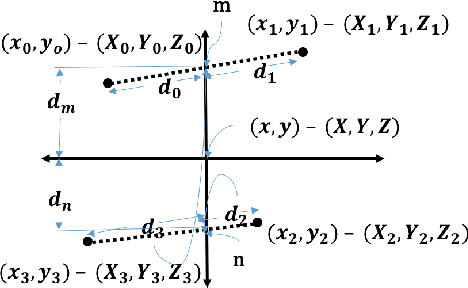



Depth sensing cameras (e.g., Kinect sensor, Tango phone) can acquire color and depth images that are registered to a common viewpoint. This opens the possibility of developing algorithms that exploit the advantages of both sensing modalities. Traditionally, cues from color images have been used for object localization (e.g., YOLO). However, the addition of a depth image can be further used to segment images that might otherwise have identical color information. Further, the depth image can be used for object size (height/width) estimation (in real-world measurements units, such as meters) as opposed to image based segmentation that would only support drawing bounding boxes around objects of interest. In this paper, we first collect color camera information along with depth information using a custom Android application on Tango Phab2 phone. Second, we perform timing and spatial alignment between the two data sources. Finally, we evaluate several ways of measuring the height of the object of interest within the captured images under a variety of settings.
An Order Preserving Bilinear Model for Person Detection in Multi-Modal Data
Jan 11, 2018
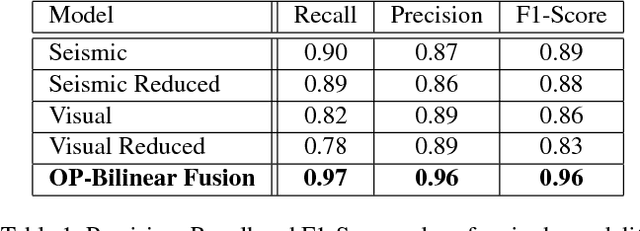
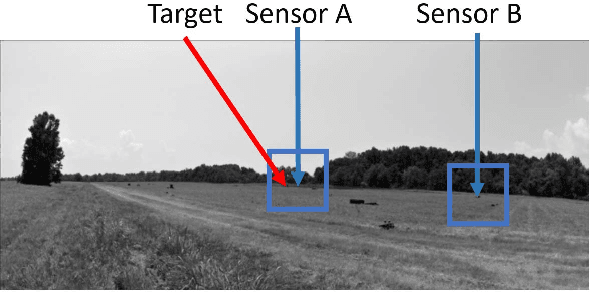

We propose a new order preserving bilinear framework that exploits low-resolution video for person detection in a multi-modal setting using deep neural networks. In this setting cameras are strategically placed such that less robust sensors, e.g. geophones that monitor seismic activity, are located within the field of views (FOVs) of cameras. The primary challenge is being able to leverage sufficient information from videos where there are less than 40 pixels on targets, while also taking advantage of less discriminative information from other modalities, e.g. seismic. Unlike state-of-the-art methods, our bilinear framework retains spatio-temporal order when computing the vector outer products between pairs of features. Despite the high dimensionality of these outer products, we demonstrate that our order preserving bilinear framework yields better performance than recent orderless bilinear models and alternative fusion methods.