 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering EV Charging Site Archetypes Through Few Shot Forecasting: The First U.S.-Wide Study
Oct 30, 2025The decarbonization of transportation relies on the widespread adoption of electric vehicles (EVs), which requires an accurate understanding of charging behavior to ensure cost-effective, grid-resilient infrastructure. Existing work is constrained by small-scale datasets, simple proximity-based modeling of temporal dependencies, and weak generalization to sites with limited operational history. To overcome these limitations, this work proposes a framework that integrates clustering with few-shot forecasting to uncover site archetypes using a novel large-scale dataset of charging demand. The results demonstrate that archetype-specific expert models outperform global baselines in forecasting demand at unseen sites. By establishing forecast performance as a basis for infrastructure segmentation, we generate actionable insights that enable operators to lower costs, optimize energy and pricing strategies, and support grid resilience critical to climate goals.
2D-3D Attention and Entropy for Pose Robust 2D Facial Recognition
May 14, 2025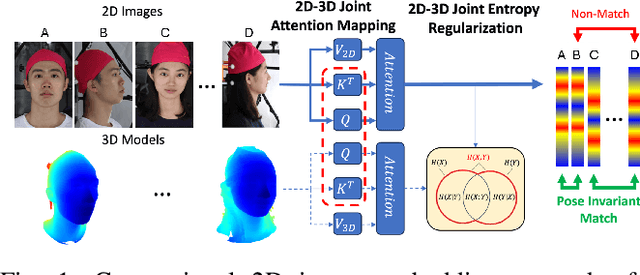



Despite recent advances in facial recognition, there remains a fundamental issue concerning degradations in performance due to substantial perspective (pose) differences between enrollment and query (probe) imagery. Therefore, we propose a novel domain adaptive framework to facilitate improved performances across large discrepancies in pose by enabling image-based (2D) representations to infer properties of inherently pose invariant point cloud (3D) representations. Specifically, our proposed framework achieves better pose invariance by using (1) a shared (joint) attention mapping to emphasize common patterns that are most correlated between 2D facial images and 3D facial data and (2) a joint entropy regularizing loss to promote better consistency$\unicode{x2014}$enhancing correlations among the intersecting 2D and 3D representations$\unicode{x2014}$by leveraging both attention maps. This framework is evaluated on FaceScape and ARL-VTF datasets, where it outperforms competitive methods by achieving profile (90$\unicode{x00b0}$$\unicode{x002b}$) TAR @ 1$\unicode{x0025}$ FAR improvements of at least 7.1$\unicode{x0025}$ and 1.57$\unicode{x0025}$, respectively.
Cross-Spectral Attention for Unsupervised RGB-IR Face Verification and Person Re-identification
Nov 28, 2024



Cross-spectral biometrics, such as matching imagery of faces or persons from visible (RGB) and infrared (IR) bands, have rapidly advanced over the last decade due to increasing sensitivity, size, quality, and ubiquity of IR focal plane arrays and enhanced analytics beyond the visible spectrum. Current techniques for mitigating large spectral disparities between RGB and IR imagery often include learning a discriminative common subspace by exploiting precisely curated data acquired from multiple spectra. Although there are challenges with determining robust architectures for extracting common information, a critical limitation for supervised methods is poor scalability in terms of acquiring labeled data. Therefore, we propose a novel unsupervised cross-spectral framework that combines (1) a new pseudo triplet loss with cross-spectral voting, (2) a new cross-spectral attention network leveraging multiple subspaces, and (3) structured sparsity to perform more discriminative cross-spectral clustering. We extensively compare our proposed RGB-IR biometric learning framework (and its individual components) with recent and previous state-of-the-art models on two challenging benchmark datasets: DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF) and RegDB person re-identification dataset, and, in some cases, achieve performance superior to completely supervised methods.
HashReID: Dynamic Network with Binary Codes for Efficient Person Re-identification
Aug 23, 2023



Biometric applications, such as person re-identification (ReID), are often deployed on energy constrained devices. While recent ReID methods prioritize high retrieval performance, they often come with large computational costs and high search time, rendering them less practical in real-world settings. In this work, we propose an input-adaptive network with multiple exit blocks, that can terminate computation early if the retrieval is straightforward or noisy, saving a lot of computation. To assess the complexity of the input, we introduce a temporal-based classifier driven by a new training strategy. Furthermore, we adopt a binary hash code generation approach instead of relying on continuous-valued features, which significantly improves the search process by a factor of 20. To ensure similarity preservation, we utilize a new ranking regularizer that bridges the gap between continuous and binary features. Extensive analysis of our proposed method is conducted on three datasets: Market1501, MSMT17 (Multi-Scene Multi-Time), and the BGC1 (BRIAR Government Collection). Using our approach, more than 70% of the samples with compact hash codes exit early on the Market1501 dataset, saving 80% of the networks computational cost and improving over other hash-based methods by 60%. These results demonstrate a significant improvement over dynamic networks and showcase comparable accuracy performance to conventional ReID methods. Code will be made available.
Weakly Supervised Face and Whole Body Recognition in Turbulent Environments
Aug 22, 2023



Face and person recognition have recently achieved remarkable success under challenging scenarios, such as off-pose and cross-spectrum matching. However, long-range recognition systems are often hindered by atmospheric turbulence, leading to spatially and temporally varying distortions in the image. Current solutions rely on generative models to reconstruct a turbulent-free image, but often preserve photo-realism instead of discriminative features that are essential for recognition. This can be attributed to the lack of large-scale datasets of turbulent and pristine paired images, necessary for optimal reconstruction. To address this issue, we propose a new weakly supervised framework that employs a parameter-efficient self-attention module to generate domain agnostic representations, aligning turbulent and pristine images into a common subspace. Additionally, we introduce a new tilt map estimator that predicts geometric distortions observed in turbulent images. This estimate is used to re-rank gallery matches, resulting in up to 13.86\% improvement in rank-1 accuracy. Our method does not require synthesizing turbulent-free images or ground-truth paired images, and requires significantly fewer annotated samples, enabling more practical and rapid utility of increasingly large datasets. We analyze our framework using two datasets -- Long-Range Face Identification Dataset (LRFID) and BRIAR Government Collection 1 (BGC1) -- achieving enhanced discriminability under varying turbulence and standoff distance.
Learning Domain and Pose Invariance for Thermal-to-Visible Face Recognition
Nov 17, 2022



Interest in thermal to visible face recognition has grown significantly over the last decade due to advancements in thermal infrared cameras and analytics beyond the visible spectrum. Despite large discrepancies between thermal and visible spectra, existing approaches bridge domain gaps by either synthesizing visible faces from thermal faces or by learning the cross-spectrum image representations. These approaches typically work well with frontal facial imagery collected at varying ranges and expressions, but exhibit significantly reduced performance when matching thermal faces with varying poses to frontal visible faces. We propose a novel Domain and Pose Invariant Framework that simultaneously learns domain and pose invariant representations. Our proposed framework is composed of modified networks for extracting the most correlated intermediate representations from off-pose thermal and frontal visible face imagery, a sub-network to jointly bridge domain and pose gaps, and a joint-loss function comprised of cross-spectrum and pose-correction losses. We demonstrate efficacy and advantages of the proposed method by evaluating on three thermal-visible datasets: ARL Visible-to-Thermal Face, ARL Multimodal Face, and Tufts Face. Although DPIF focuses on learning to match off-pose thermal to frontal visible faces, we also show that DPIF enhances performance when matching frontal thermal face images to frontal visible face images.
Understanding Cross Domain Presentation Attack Detection for Visible Face Recognition
Nov 03, 2021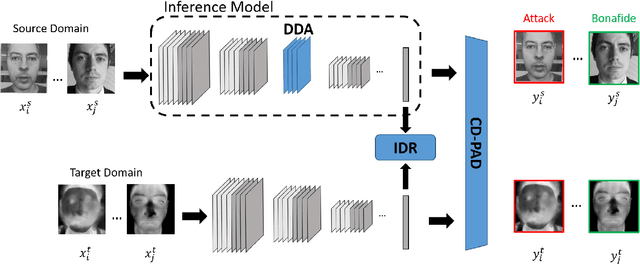
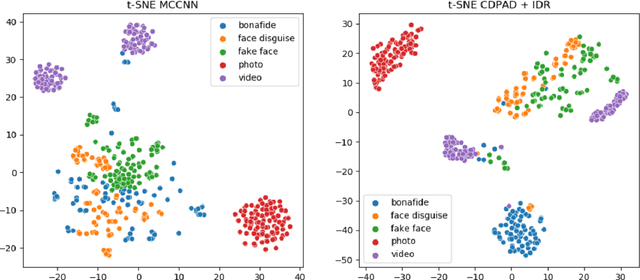
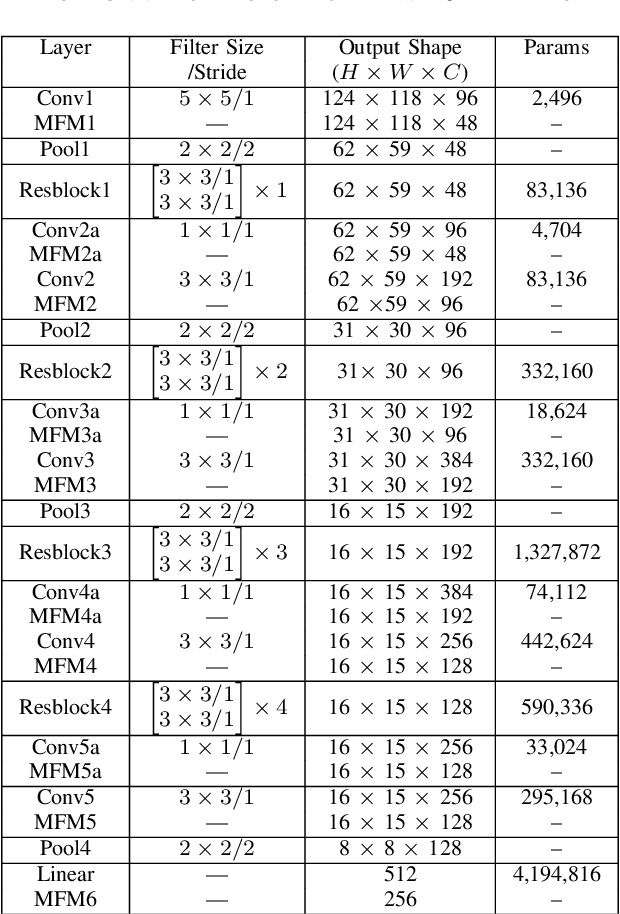

Face signatures, including size, shape, texture, skin tone, eye color, appearance, and scars/marks, are widely used as discriminative, biometric information for access control. Despite recent advancements in facial recognition systems, presentation attacks on facial recognition systems have become increasingly sophisticated. The ability to detect presentation attacks or spoofing attempts is a pressing concern for the integrity, security, and trust of facial recognition systems. Multi-spectral imaging has been previously introduced as a way to improve presentation attack detection by utilizing sensors that are sensitive to different regions of the electromagnetic spectrum (e.g., visible, near infrared, long-wave infrared). Although multi-spectral presentation attack detection systems may be discriminative, the need for additional sensors and computational resources substantially increases complexity and costs. Instead, we propose a method that exploits information from infrared imagery during training to increase the discriminability of visible-based presentation attack detection systems. We introduce (1) a new cross-domain presentation attack detection framework that increases the separability of bonafide and presentation attacks using only visible spectrum imagery, (2) an inverse domain regularization technique for added training stability when optimizing our cross-domain presentation attack detection framework, and (3) a dense domain adaptation subnetwork to transform representations between visible and non-visible domains.
A Large-Scale, Time-Synchronized Visible and Thermal Face Dataset
Jan 07, 2021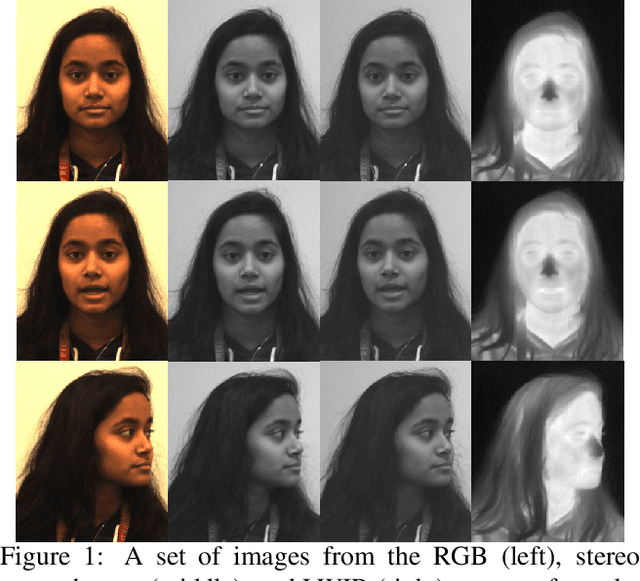
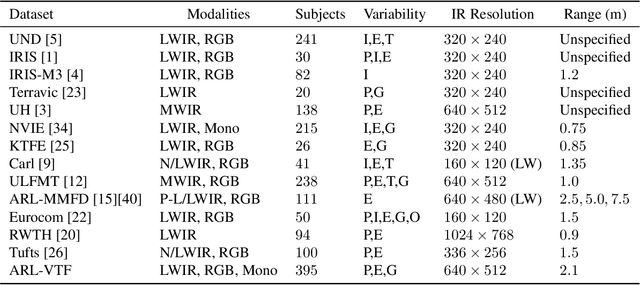


Thermal face imagery, which captures the naturally emitted heat from the face, is limited in availability compared to face imagery in the visible spectrum. To help address this scarcity of thermal face imagery for research and algorithm development, we present the DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF). With over 500,000 images from 395 subjects, the ARL-VTF dataset represents, to the best of our knowledge, the largest collection of paired visible and thermal face images to date. The data was captured using a modern long wave infrared (LWIR) camera mounted alongside a stereo setup of three visible spectrum cameras. Variability in expressions, pose, and eyewear has been systematically recorded. The dataset has been curated with extensive annotations, metadata, and standardized protocols for evaluation. Furthermore, this paper presents extensive benchmark results and analysis on thermal face landmark detection and thermal-to-visible face verification by evaluating state-of-the-art models on the ARL-VTF dataset.
Unsupervised Attention Based Instance Discriminative Learning for Person Re-Identification
Nov 03, 2020
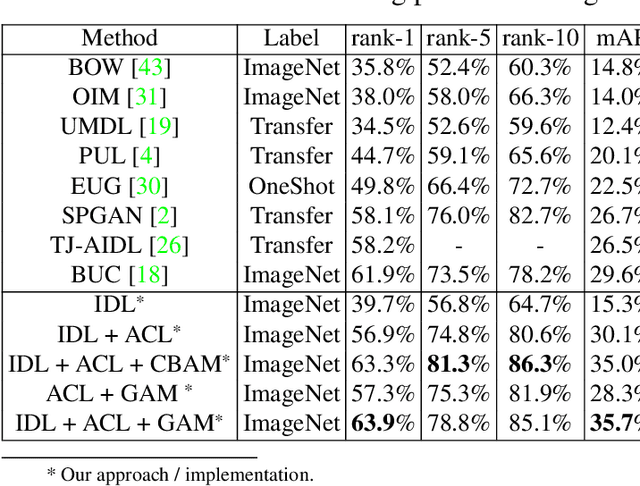
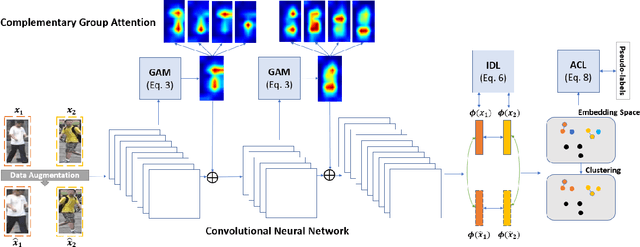

Recent advances in person re-identification have demonstrated enhanced discriminability, especially with supervised learning or transfer learning. However, since the data requirements---including the degree of data curations---are becoming increasingly complex and laborious, there is a critical need for unsupervised methods that are robust to large intra-class variations, such as changes in perspective, illumination, articulated motion, resolution, etc. Therefore, we propose an unsupervised framework for person re-identification which is trained in an end-to-end manner without any pre-training. Our proposed framework leverages a new attention mechanism that combines group convolutions to (1) enhance spatial attention at multiple scales and (2) reduce the number of trainable parameters by 59.6%. Additionally, our framework jointly optimizes the network with agglomerative clustering and instance learning to tackle hard samples. We perform extensive analysis using the Market1501 and DukeMTMC-reID datasets to demonstrate that our method consistently outperforms the state-of-the-art methods (with and without pre-trained weights).
Cross-Domain Identification for Thermal-to-Visible Face Recognition
Aug 19, 2020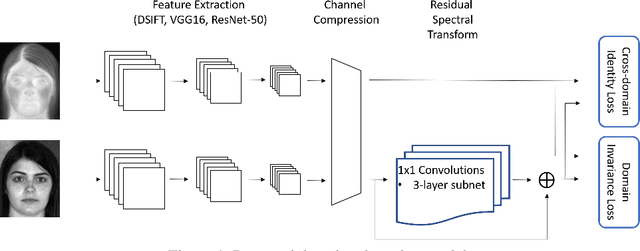
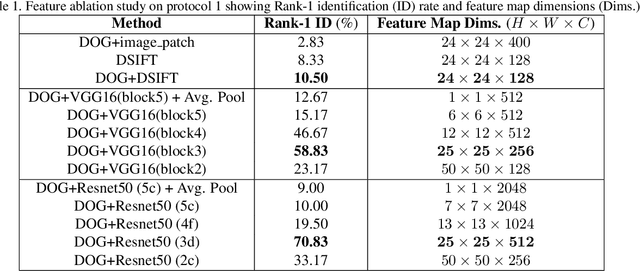
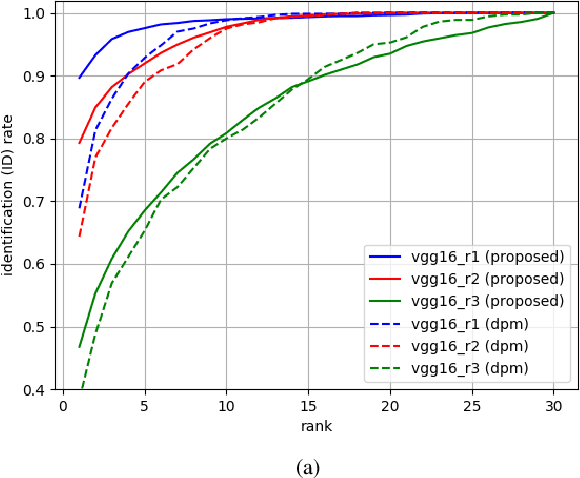
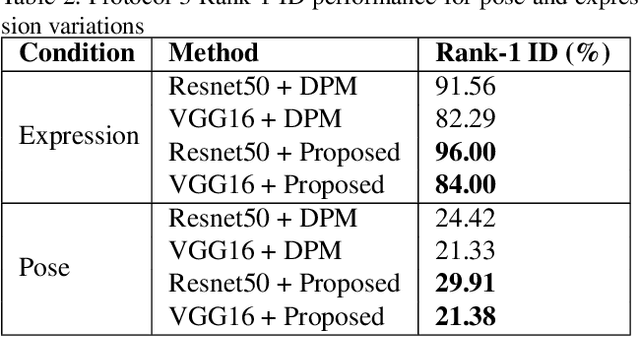
Recent advances in domain adaptation, especially those applied to heterogeneous facial recognition, typically rely upon restrictive Euclidean loss functions (e.g., $L_2$ norm) which perform best when images from two different domains (e.g., visible and thermal) are co-registered and temporally synchronized. This paper proposes a novel domain adaptation framework that combines a new feature mapping sub-network with existing deep feature models, which are based on modified network architectures (e.g., VGG16 or Resnet50). This framework is optimized by introducing new cross-domain identity and domain invariance loss functions for thermal-to-visible face recognition, which alleviates the requirement for precisely co-registered and synchronized imagery. We provide extensive analysis of both features and loss functions used, and compare the proposed domain adaptation framework with state-of-the-art feature based domain adaptation models on a difficult dataset containing facial imagery collected at varying ranges, poses, and expressions. Moreover, we analyze the viability of the proposed framework for more challenging tasks, such as non-frontal thermal-to-visible face recognition.