 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Spectral Attention for Unsupervised RGB-IR Face Verification and Person Re-identification
Nov 28, 2024



Cross-spectral biometrics, such as matching imagery of faces or persons from visible (RGB) and infrared (IR) bands, have rapidly advanced over the last decade due to increasing sensitivity, size, quality, and ubiquity of IR focal plane arrays and enhanced analytics beyond the visible spectrum. Current techniques for mitigating large spectral disparities between RGB and IR imagery often include learning a discriminative common subspace by exploiting precisely curated data acquired from multiple spectra. Although there are challenges with determining robust architectures for extracting common information, a critical limitation for supervised methods is poor scalability in terms of acquiring labeled data. Therefore, we propose a novel unsupervised cross-spectral framework that combines (1) a new pseudo triplet loss with cross-spectral voting, (2) a new cross-spectral attention network leveraging multiple subspaces, and (3) structured sparsity to perform more discriminative cross-spectral clustering. We extensively compare our proposed RGB-IR biometric learning framework (and its individual components) with recent and previous state-of-the-art models on two challenging benchmark datasets: DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF) and RegDB person re-identification dataset, and, in some cases, achieve performance superior to completely supervised methods.
Learning Domain and Pose Invariance for Thermal-to-Visible Face Recognition
Nov 17, 2022Interest in thermal to visible face recognition has grown significantly over the last decade due to advancements in thermal infrared cameras and analytics beyond the visible spectrum. Despite large discrepancies between thermal and visible spectra, existing approaches bridge domain gaps by either synthesizing visible faces from thermal faces or by learning the cross-spectrum image representations. These approaches typically work well with frontal facial imagery collected at varying ranges and expressions, but exhibit significantly reduced performance when matching thermal faces with varying poses to frontal visible faces. We propose a novel Domain and Pose Invariant Framework that simultaneously learns domain and pose invariant representations. Our proposed framework is composed of modified networks for extracting the most correlated intermediate representations from off-pose thermal and frontal visible face imagery, a sub-network to jointly bridge domain and pose gaps, and a joint-loss function comprised of cross-spectrum and pose-correction losses. We demonstrate efficacy and advantages of the proposed method by evaluating on three thermal-visible datasets: ARL Visible-to-Thermal Face, ARL Multimodal Face, and Tufts Face. Although DPIF focuses on learning to match off-pose thermal to frontal visible faces, we also show that DPIF enhances performance when matching frontal thermal face images to frontal visible face images.
A Large-Scale, Time-Synchronized Visible and Thermal Face Dataset
Jan 07, 2021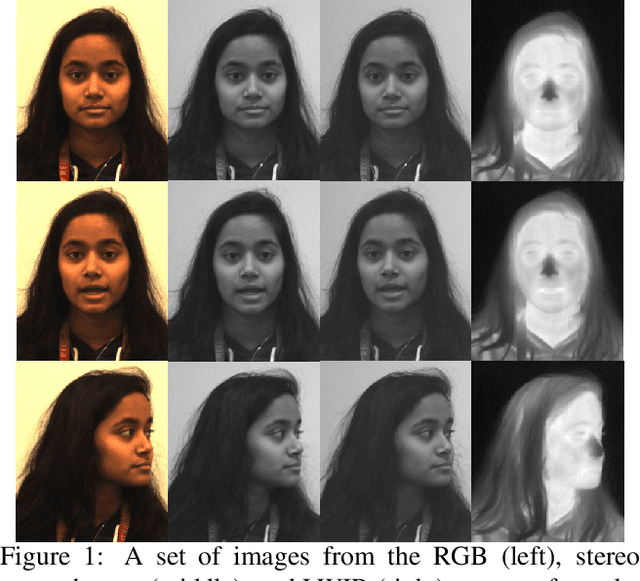
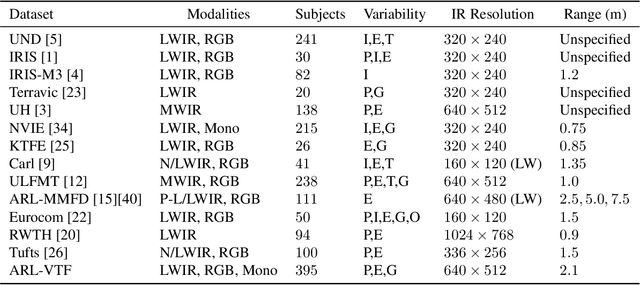


Thermal face imagery, which captures the naturally emitted heat from the face, is limited in availability compared to face imagery in the visible spectrum. To help address this scarcity of thermal face imagery for research and algorithm development, we present the DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF). With over 500,000 images from 395 subjects, the ARL-VTF dataset represents, to the best of our knowledge, the largest collection of paired visible and thermal face images to date. The data was captured using a modern long wave infrared (LWIR) camera mounted alongside a stereo setup of three visible spectrum cameras. Variability in expressions, pose, and eyewear has been systematically recorded. The dataset has been curated with extensive annotations, metadata, and standardized protocols for evaluation. Furthermore, this paper presents extensive benchmark results and analysis on thermal face landmark detection and thermal-to-visible face verification by evaluating state-of-the-art models on the ARL-VTF dataset.
Cross-Domain Identification for Thermal-to-Visible Face Recognition
Aug 19, 2020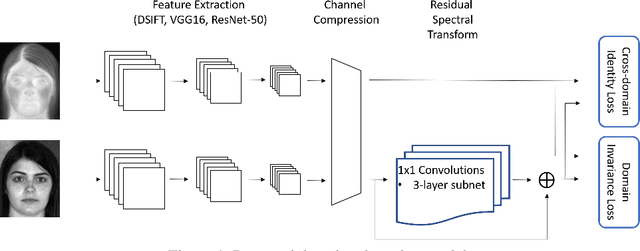
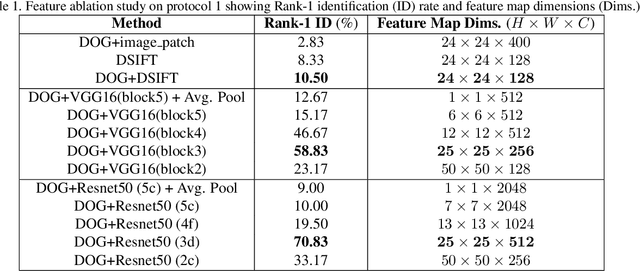
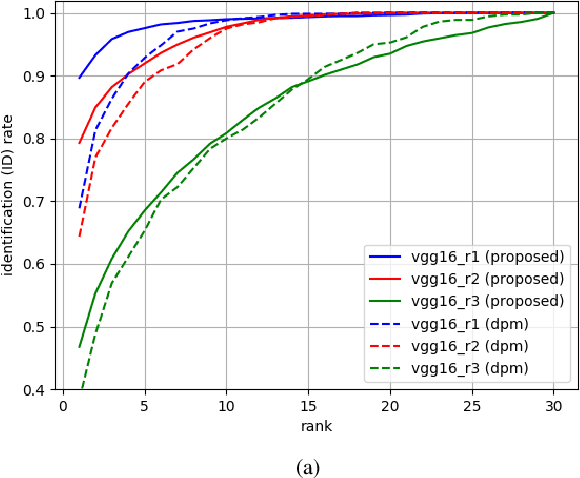
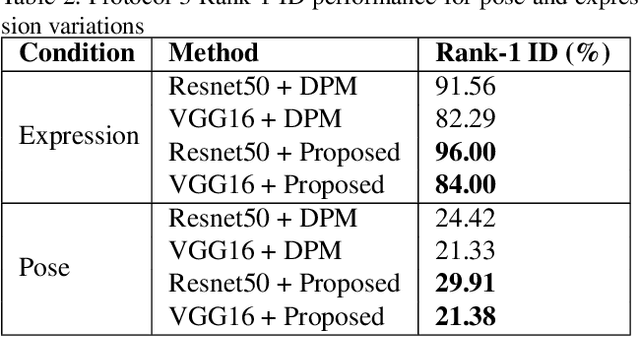
Recent advances in domain adaptation, especially those applied to heterogeneous facial recognition, typically rely upon restrictive Euclidean loss functions (e.g., $L_2$ norm) which perform best when images from two different domains (e.g., visible and thermal) are co-registered and temporally synchronized. This paper proposes a novel domain adaptation framework that combines a new feature mapping sub-network with existing deep feature models, which are based on modified network architectures (e.g., VGG16 or Resnet50). This framework is optimized by introducing new cross-domain identity and domain invariance loss functions for thermal-to-visible face recognition, which alleviates the requirement for precisely co-registered and synchronized imagery. We provide extensive analysis of both features and loss functions used, and compare the proposed domain adaptation framework with state-of-the-art feature based domain adaptation models on a difficult dataset containing facial imagery collected at varying ranges, poses, and expressions. Moreover, we analyze the viability of the proposed framework for more challenging tasks, such as non-frontal thermal-to-visible face recognition.