 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale, Time-Synchronized Visible and Thermal Face Dataset
Jan 07, 2021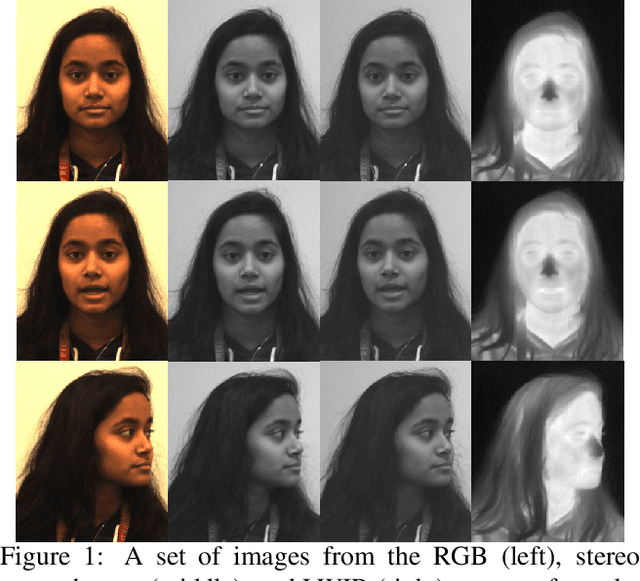


Thermal face imagery, which captures the naturally emitted heat from the face, is limited in availability compared to face imagery in the visible spectrum. To help address this scarcity of thermal face imagery for research and algorithm development, we present the DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF). With over 500,000 images from 395 subjects, the ARL-VTF dataset represents, to the best of our knowledge, the largest collection of paired visible and thermal face images to date. The data was captured using a modern long wave infrared (LWIR) camera mounted alongside a stereo setup of three visible spectrum cameras. Variability in expressions, pose, and eyewear has been systematically recorded. The dataset has been curated with extensive annotations, metadata, and standardized protocols for evaluation. Furthermore, this paper presents extensive benchmark results and analysis on thermal face landmark detection and thermal-to-visible face verification by evaluating state-of-the-art models on the ARL-VTF dataset.
Cross-Domain Identification for Thermal-to-Visible Face Recognition
Aug 19, 2020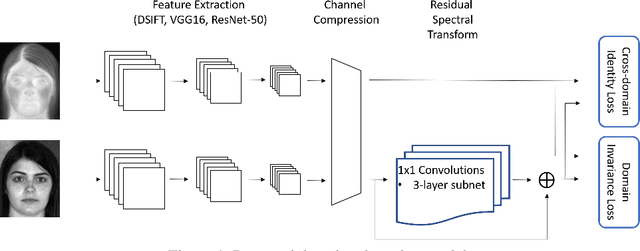
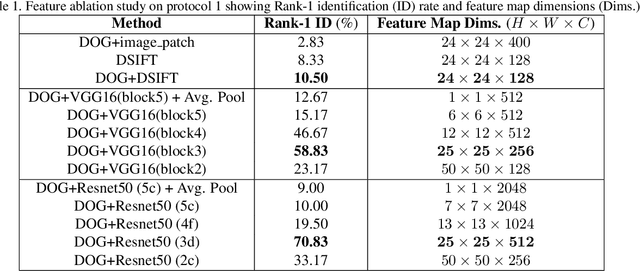
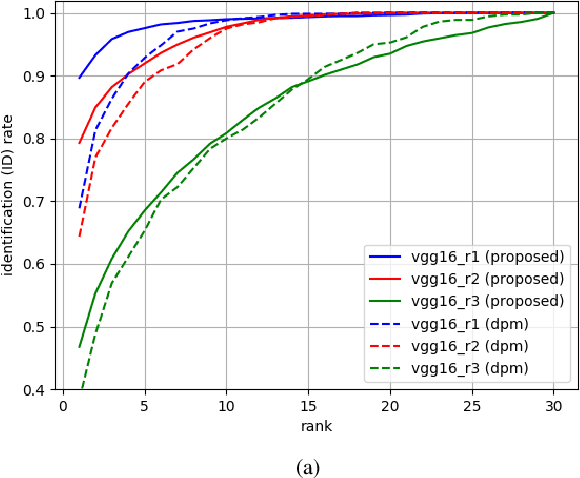
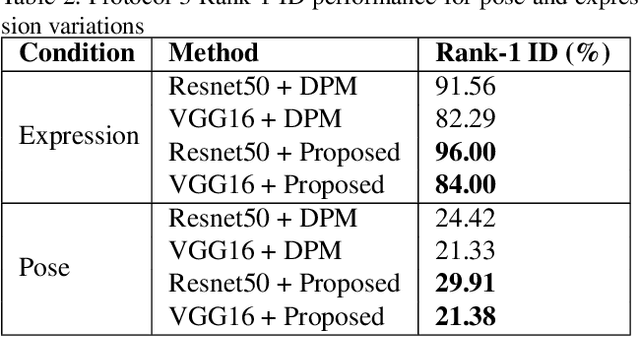
Recent advances in domain adaptation, especially those applied to heterogeneous facial recognition, typically rely upon restrictive Euclidean loss functions (e.g., $L_2$ norm) which perform best when images from two different domains (e.g., visible and thermal) are co-registered and temporally synchronized. This paper proposes a novel domain adaptation framework that combines a new feature mapping sub-network with existing deep feature models, which are based on modified network architectures (e.g., VGG16 or Resnet50). This framework is optimized by introducing new cross-domain identity and domain invariance loss functions for thermal-to-visible face recognition, which alleviates the requirement for precisely co-registered and synchronized imagery. We provide extensive analysis of both features and loss functions used, and compare the proposed domain adaptation framework with state-of-the-art feature based domain adaptation models on a difficult dataset containing facial imagery collected at varying ranges, poses, and expressions. Moreover, we analyze the viability of the proposed framework for more challenging tasks, such as non-frontal thermal-to-visible face recognition.
Multi-Scale Thermal to Visible Face Verification via Attribute Guided Synthesis
Apr 20, 2020



Thermal-to-visible face verification is a challenging problem due to the large domain discrepancy between the modalities. Existing approaches either attempt to synthesize visible faces from thermal faces or extract robust features from these modalities for cross-modal matching. In this paper, we use attributes extracted from visible images to synthesize the attributepreserved visible images from thermal imagery for cross-modal matching. A pre-trained VGG-Face network is used to extract the attributes from the visible image. Then, a novel multi-scale generator is proposed to synthesize the visible image from the thermal image guided by the extracted attributes. Finally, a pretrained VGG-Face network is leveraged to extract features from the synthesized image and the input visible image for verification. An extended dataset consisting of polarimetric thermal faces of 121 subjects is also introduced. Extensive experiments evaluated on various datasets and protocols demonstrate that the proposed method achieves state-of-the-art per-formance.
Polarimetric Thermal to Visible Face Verification via Self-Attention Guided Synthesis
Apr 15, 2019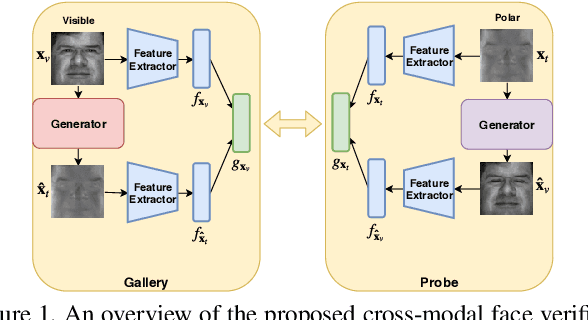


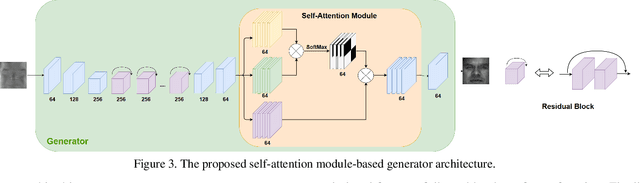
Polarimetric thermal to visible face verification entails matching two images that contain significant domain differences. Several recent approaches have attempted to synthesize visible faces from thermal images for cross-modal matching. In this paper, we take a different approach in which rather than focusing only on synthesizing visible faces from thermal faces, we also propose to synthesize thermal faces from visible faces. Our intuition is based on the fact that thermal images also contain some discriminative information about the person for verification. Deep features from a pre-trained Convolutional Neural Network (CNN) are extracted from the original as well as the synthesized images. These features are then fused to generate a template which is then used for verification. The proposed synthesis network is based on the self-attention generative adversarial network (SAGAN) which essentially allows efficient attention-guided image synthesis. Extensive experiments on the ARL polarimetric thermal face dataset demonstrate that the proposed method achieves state-of-the-art performance.
Synthesis of High-Quality Visible Faces from Polarimetric Thermal Faces using Generative Adversarial Networks
Dec 12, 2018


The large domain discrepancy between faces captured in polarimetric (or conventional) thermal and visible domain makes cross-domain face verification a highly challenging problem for human examiners as well as computer vision algorithms. Previous approaches utilize either a two-step procedure (visible feature estimation and visible image reconstruction) or an input-level fusion technique, where different Stokes images are concatenated and used as a multi-channel input to synthesize the visible image given the corresponding polarimetric signatures. Although these methods have yielded improvements, we argue that input-level fusion alone may not be sufficient to realize the full potential of the available Stokes images. We propose a Generative Adversarial Networks (GAN) based multi-stream feature-level fusion technique to synthesize high-quality visible images from prolarimetric thermal images. The proposed network consists of a generator sub-network, constructed using an encoder-decoder network based on dense residual blocks, and a multi-scale discriminator sub-network. The generator network is trained by optimizing an adversarial loss in addition to a perceptual loss and an identity preserving loss to enable photo realistic generation of visible images while preserving discriminative characteristics. An extended dataset consisting of polarimetric thermal facial signatures of 111 subjects is also introduced. Multiple experiments evaluated on different experimental protocols demonstrate that the proposed method achieves state-of-the-art performance. Code will be made available at https://github.com/hezhangsprinter.
Thermal to Visible Synthesis of Face Images using Multiple Regions
Mar 20, 2018
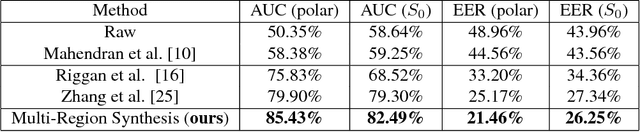
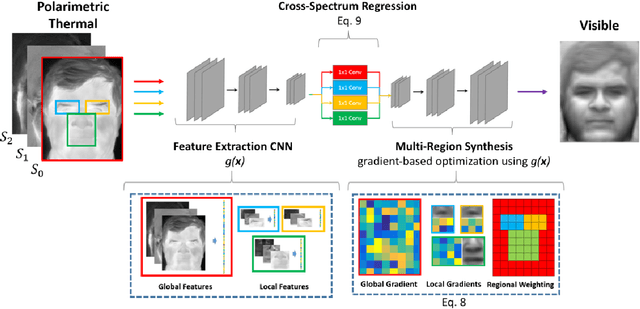
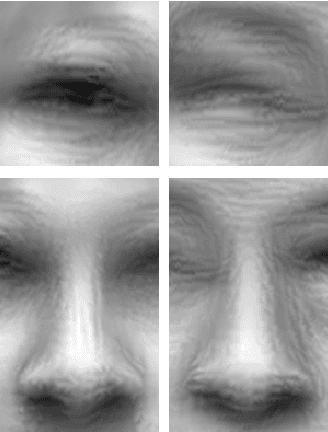
Synthesis of visible spectrum faces from thermal facial imagery is a promising approach for heterogeneous face recognition; enabling existing face recognition software trained on visible imagery to be leveraged, and allowing human analysts to verify cross-spectrum matches more effectively. We propose a new synthesis method to enhance the discriminative quality of synthesized visible face imagery by leveraging both global (e.g., entire face) and local regions (e.g., eyes, nose, and mouth). Here, each region provides (1) an independent representation for the corresponding area, and (2) additional regularization terms, which impact the overall quality of synthesized images. We analyze the effects of using multiple regions to synthesize a visible face image from a thermal face. We demonstrate that our approach improves cross-spectrum verification rates over recently published synthesis approaches. Moreover, using our synthesized imagery, we report the results on facial landmark detection-commonly used for image registration-which is a critical part of the face recognition process.