 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor Conditioned Attention Maps for Video Action Detection
Paper and Code
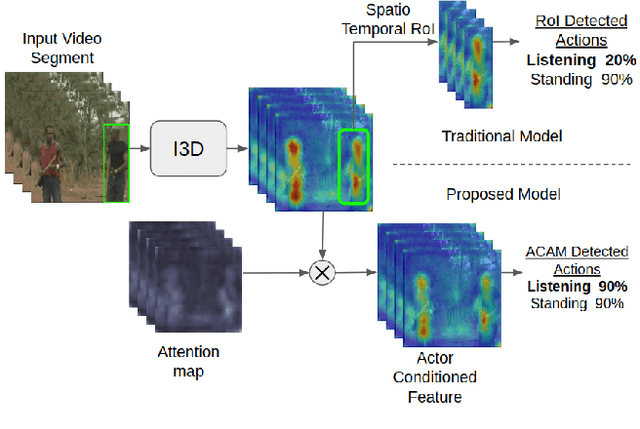
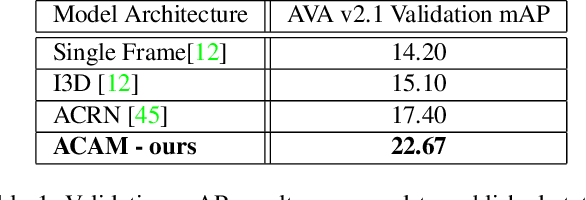

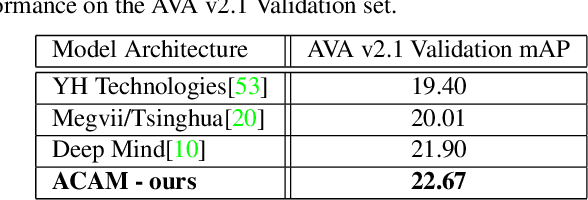
Interactions with surrounding objects and people contain important information towards understanding human actions. In order to model such interactions explicitly, we propose to generate attention maps that rank each spatio-temporal region's importance to a detected actor. We refer to these as Actor-Conditioned Attention Maps (ACAM), and these maps serve as weights to the features extracted from the whole scene. These resulting actor-conditioned features help focus the learned model on regions that are important/relevant to the conditioned actor. Another novelty of our approach is in the use of pre-trained object detectors, instead of region proposals, that generalize better to videos from different sources. Detailed experimental results on the AVA 2.1 datasets demonstrate the importance of interactions, with a performance improvement of 5 mAP with respect to state of the art published results.