 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetraTSDF: 3D human reconstruction from a single image with a tetrahedral outer shell
Apr 22, 2020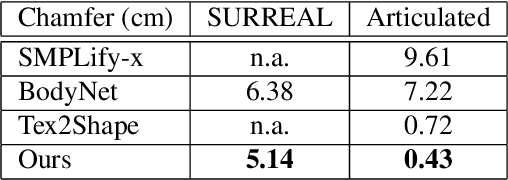
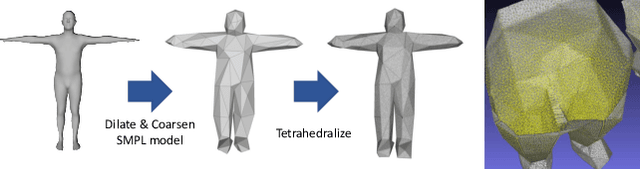

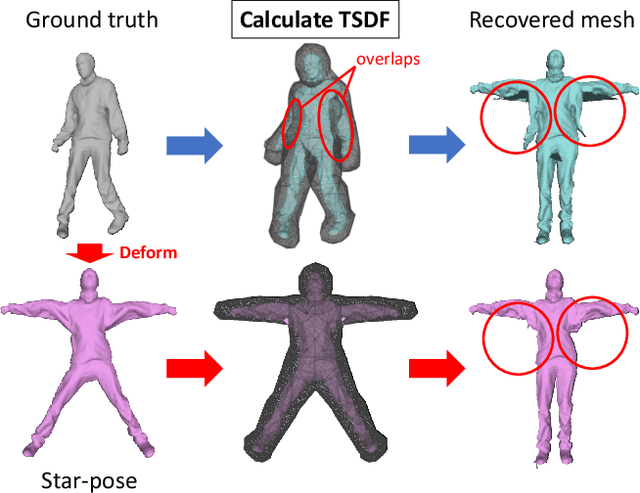
Recovering the 3D shape of a person from its 2D appearance is ill-posed due to ambiguities. Nevertheless, with the help of convolutional neural networks (CNN) and prior knowledge on the 3D human body, it is possible to overcome such ambiguities to recover detailed 3D shapes of human bodies from single images. Current solutions, however, fail to reconstruct all the details of a person wearing loose clothes. This is because of either (a) huge memory requirement that cannot be maintained even on modern GPUs or (b) the compact 3D representation that cannot encode all the details. In this paper, we propose the tetrahedral outer shell volumetric truncated signed distance function (TetraTSDF) model for the human body, and its corresponding part connection network (PCN) for 3D human body shape regression. Our proposed model is compact, dense, accurate, and yet well suited for CNN-based regression task. Our proposed PCN allows us to learn the distribution of the TSDF in the tetrahedral volume from a single image in an end-to-end manner. Results show that our proposed method allows to reconstruct detailed shapes of humans wearing loose clothes from single RGB images.
TransCut: Transparent Object Segmentation from a Light-Field Image
Nov 21, 2015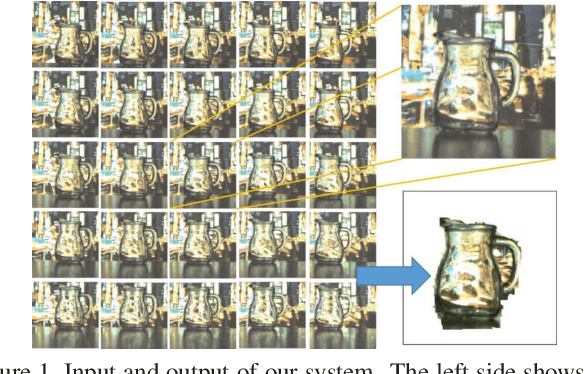
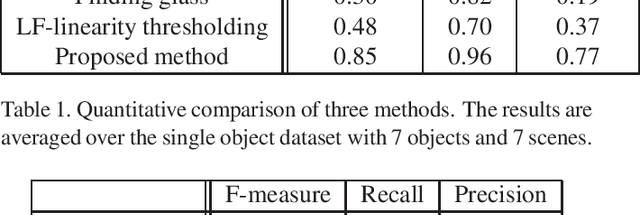
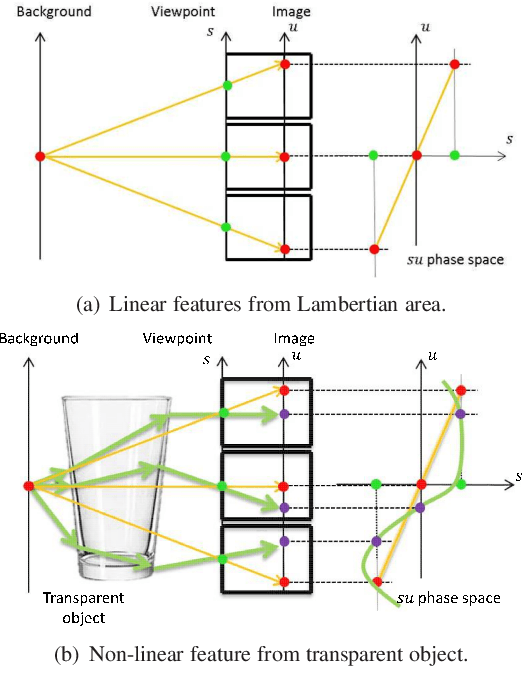
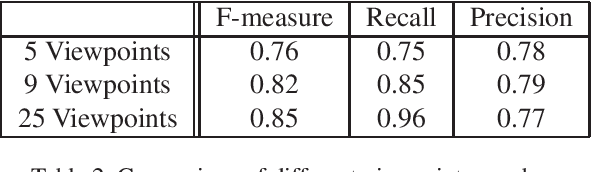
The segmentation of transparent objects can be very useful in computer vision applications. However, because they borrow texture from their background and have a similar appearance to their surroundings, transparent objects are not handled well by regular image segmentation methods. We propose a method that overcomes these problems using the consistency and distortion properties of a light-field image. Graph-cut optimization is applied for the pixel labeling problem. The light-field linearity is used to estimate the likelihood of a pixel belonging to the transparent object or Lambertian background, and the occlusion detector is used to find the occlusion boundary. We acquire a light field dataset for the transparent object, and use this dataset to evaluate our method. The results demonstrate that the proposed method successfully segments transparent objects from the background.
Mobile Camera Array Calibration for Light Field Acquisition
Jul 16, 2014



The light field camera is useful for computer graphics and vision applications. Calibration is an essential step for these applications. After calibration, we can rectify the captured image by using the calibrated camera parameters. However, the large camera array calibration method, which assumes that all cameras are on the same plane, ignores the orientation and intrinsic parameters. The multi-camera calibration technique usually assumes that the working volume and viewpoints are fixed. In this paper, we describe a calibration algorithm suitable for a mobile camera array based light field acquisition system. The algorithm performs in Zhang's style by moving a checkerboard, and computes the initial parameters in closed form. Global optimization is then applied to refine all the parameters simultaneously. Our implementation is rather flexible in that users can assign the number of viewpoints and refinement of intrinsic parameters is optional. Experiments on both simulated data and real data acquired by a commercial product show that our method yields good results. Digital refocusing application shows the calibrated light field can well focus to the target object we desired.