 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBROTHER: Behavioral Recognition Optimized Through Heterogeneous Ensemble Regularization for Ambivalence and Hesitancy
Mar 15, 2026Recognizing complex behavioral states such as Ambivalence and Hesitancy (A/H) in naturalistic video settings remains a significant challenge in affective computing. Unlike basic facial expressions, A/H manifests as subtle, multimodal conflicts that require deep contextual and temporal understanding. In this paper, we propose a highly regularized, multimodal fusion pipeline to predict A/H at the video level. We extract robust unimodal features from visual, acoustic, and linguistic data, introducing a specialized statistical text modality explicitly designed to capture temporal speech variations and behavioral cues. To identify the most effective representations, we evaluate 15 distinct modality combinations across a committee of machine learning classifiers (MLP, Random Forest, and GBDT), selecting the most well-calibrated models based on validation Binary Cross-Entropy (BCE) loss. Furthermore, to optimally fuse these heterogeneous models without overfitting to the training distribution, we implement a Particle Swarm Optimization (PSO) hard-voting ensemble. The PSO fitness function dynamically incorporates a train-validation gap penalty (lambda) to actively suppress redundant or overfitted classifiers. Our comprehensive evaluation demonstrates that while linguistic features serve as the strongest independent predictor of A/H, our heavily regularized PSO ensemble (lambda = 0.2) effectively harnesses multimodal synergies, achieving a peak Macro F1-score of 0.7465 on the unseen test set. These results emphasize that treating ambivalence and hesitancy as a multimodal conflict, evaluated through an intelligently weighted committee, provides a robust framework for in-the-wild behavioral analysis.
Explaining Agent's Decision-making in a Hierarchical Reinforcement Learning Scenario
Dec 14, 2022Reinforcement learning is a machine learning approach based on behavioral psychology. It is focused on learning agents that can acquire knowledge and learn to carry out new tasks by interacting with the environment. However, a problem occurs when reinforcement learning is used in critical contexts where the users of the system need to have more information and reliability for the actions executed by an agent. In this regard, explainable reinforcement learning seeks to provide to an agent in training with methods in order to explain its behavior in such a way that users with no experience in machine learning could understand the agent's behavior. One of these is the memory-based explainable reinforcement learning method that is used to compute probabilities of success for each state-action pair using an episodic memory. In this work, we propose to make use of the memory-based explainable reinforcement learning method in a hierarchical environment composed of sub-tasks that need to be first addressed to solve a more complex task. The end goal is to verify if it is possible to provide to the agent the ability to explain its actions in the global task as well as in the sub-tasks. The results obtained showed that it is possible to use the memory-based method in hierarchical environments with high-level tasks and compute the probabilities of success to be used as a basis for explaining the agent's behavior.
Reinforcement Learning for UAV control with Policy and Reward Shaping
Dec 06, 2022In recent years, unmanned aerial vehicle (UAV) related technology has expanded knowledge in the area, bringing to light new problems and challenges that require solutions. Furthermore, because the technology allows processes usually carried out by people to be automated, it is in great demand in industrial sectors. The automation of these vehicles has been addressed in the literature, applying different machine learning strategies. Reinforcement learning (RL) is an automation framework that is frequently used to train autonomous agents. RL is a machine learning paradigm wherein an agent interacts with an environment to solve a given task. However, learning autonomously can be time consuming, computationally expensive, and may not be practical in highly-complex scenarios. Interactive reinforcement learning allows an external trainer to provide advice to an agent while it is learning a task. In this study, we set out to teach an RL agent to control a drone using reward-shaping and policy-shaping techniques simultaneously. Two simulated scenarios were proposed for the training; one without obstacles and one with obstacles. We also studied the influence of each technique. The results show that an agent trained simultaneously with both techniques obtains a lower reward than an agent trained using only a policy-based approach. Nevertheless, the agent achieves lower execution times and less dispersion during training.
* 9 pages, 9 figures, Preprint accepted at the 41st International Conference of the Chilean Computer Science Society, SCCC 2022, Santiago, Chile, 2022
Explainable Deep Reinforcement Learning Using Introspection in a Non-episodic Task
Aug 18, 2021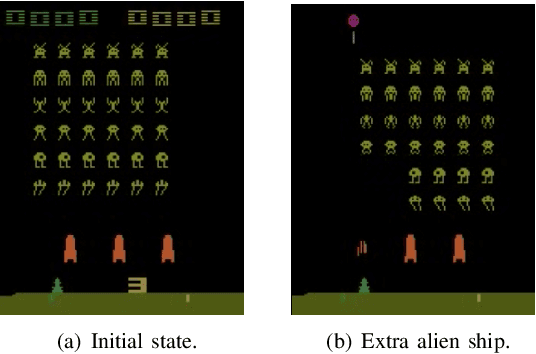
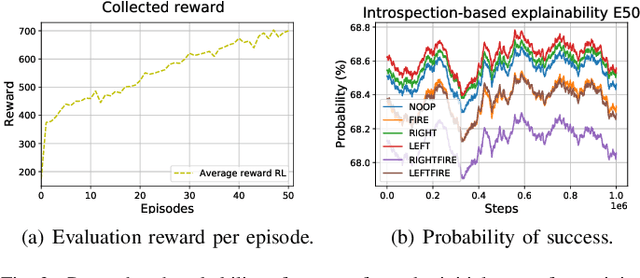
Explainable reinforcement learning allows artificial agents to explain their behavior in a human-like manner aiming at non-expert end-users. An efficient alternative of creating explanations is to use an introspection-based method that transforms Q-values into probabilities of success used as the base to explain the agent's decision-making process. This approach has been effectively used in episodic and discrete scenarios, however, to compute the probability of success in non-episodic and more complex environments has not been addressed yet. In this work, we adapt the introspection method to be used in a non-episodic task and try it in a continuous Atari game scenario solved with the Rainbow algorithm. Our initial results show that the probability of success can be computed directly from the Q-values for all possible actions.
Learning Proxemic Behavior Using Reinforcement Learning with Cognitive Agents
Aug 08, 2021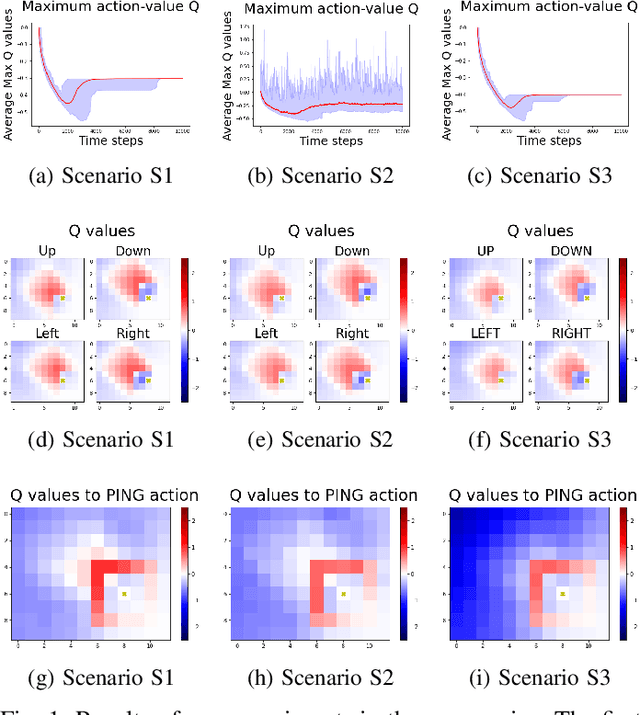
Proxemics is a branch of non-verbal communication concerned with studying the spatial behavior of people and animals. This behavior is an essential part of the communication process due to delimit the acceptable distance to interact with another being. With increasing research on human-agent interaction, new alternatives are needed that allow optimal communication, avoiding agents feeling uncomfortable. Several works consider proxemic behavior with cognitive agents, where human-robot interaction techniques and machine learning are implemented. However, environments consider fixed personal space and that the agent previously knows it. In this work, we aim to study how agents behave in environments based on proxemic behavior, and propose a modified gridworld to that aim. This environment considers an issuer with proxemic behavior that provides a disagreement signal to the agent. Our results show that the learning agent can identify the proxemic space when the issuer gives feedback about agent performance.
KutralNet: A Portable Deep Learning Model for Fire Recognition
Aug 16, 2020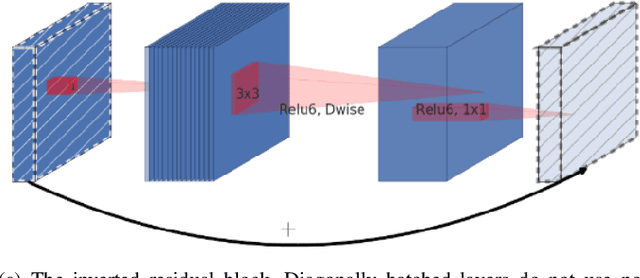
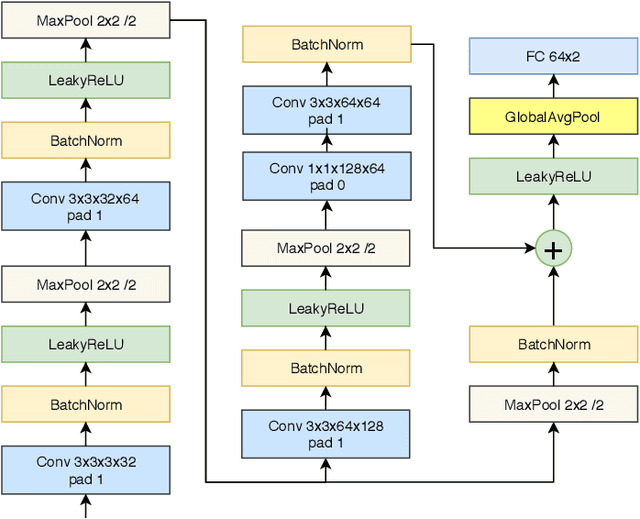
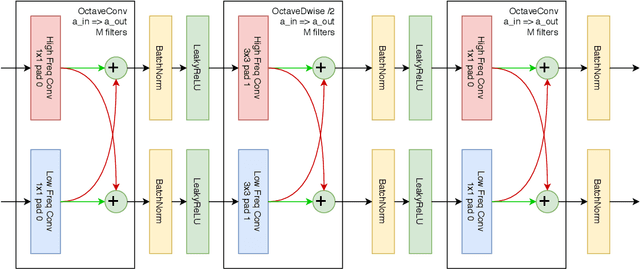
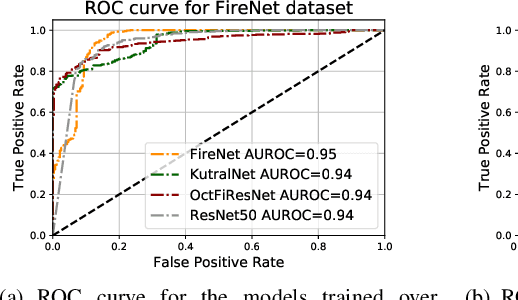
Most of the automatic fire alarm systems detect the fire presence through sensors like thermal, smoke, or flame. One of the new approaches to the problem is the use of images to perform the detection. The image approach is promising since it does not need specific sensors and can be easily embedded in different devices. However, besides the high performance, the computational cost of the used deep learning methods is a challenge to their deployment in portable devices. In this work, we propose a new deep learning architecture that requires fewer floating-point operations (flops) for fire recognition. Additionally, we propose a portable approach for fire recognition and the use of modern techniques such as inverted residual block, convolutions like depth-wise, and octave, to reduce the model's computational cost. The experiments show that our model keeps high accuracy while substantially reducing the number of parameters and flops. One of our models presents 71\% fewer parameters than FireNet, while still presenting competitive accuracy and AUROC performance. The proposed methods are evaluated on FireNet and FiSmo datasets. The obtained results are promising for the implementation of the model in a mobile device, considering the reduced number of flops and parameters acquired.
A Comparison of Humanoid Robot Simulators: A Quantitative Approach
Aug 11, 2020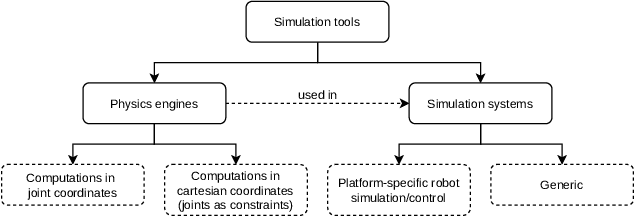

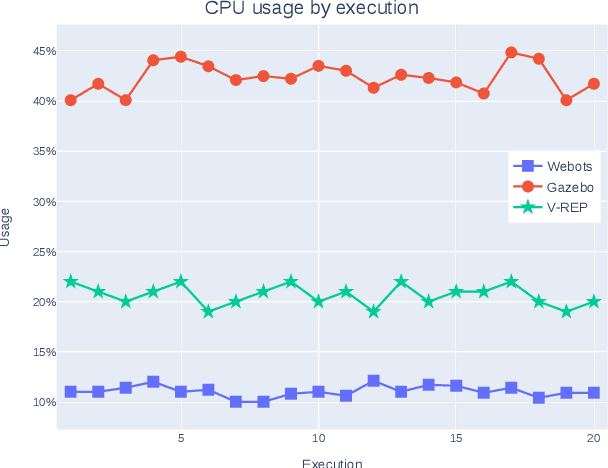
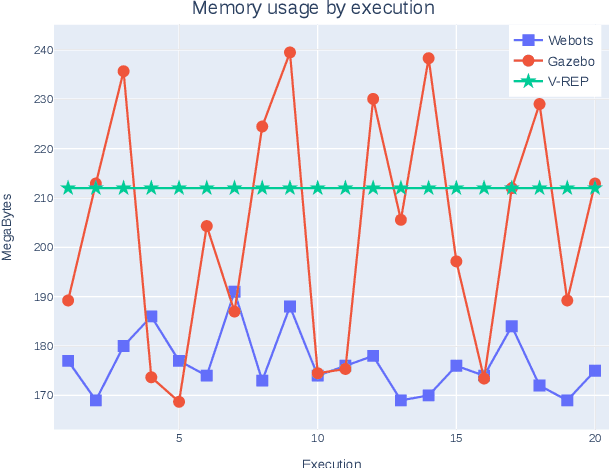
Research on humanoid robotic systems involves a considerable amount of computational resources, not only for the involved design but also for its development and subsequent implementation. For robotic systems to be implemented in real-world scenarios, in several situations, it is preferred to develop and test them under controlled environments in order to reduce the risk of errors and unexpected behavior. In this regard, a more accessible and efficient alternative is to implement the environment using robotic simulation tools. This paper presents a quantitative comparison of Gazebo, Webots, and V-REP, three simulators widely used by the research community to develop robotic systems. To compare the performance of these three simulators, elements such as CPU, memory footprint, and disk access are used to measure and compare them to each other. In order to measure the use of resources, each simulator executes 20 times a robotic scenario composed by a NAO robot that must navigate to a goal position avoiding a specific obstacle. In general terms, our results show that Webots is the simulator with the lowest use of resources, followed by V-REP, which has advantages over Gazebo, mainly because of the CPU use.
Deep Reinforcement Learning with Interactive Feedback in a Human-Robot Environment
Jul 07, 2020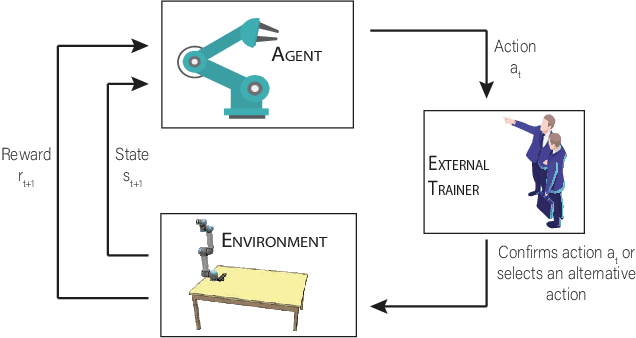
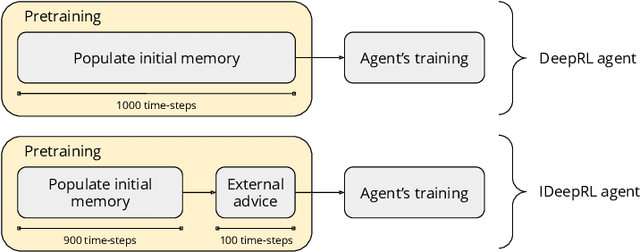
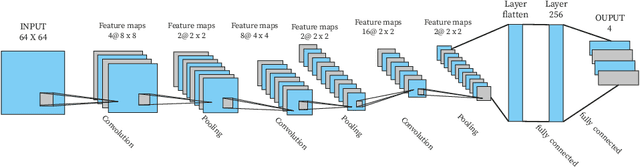

Robots are extending their presence in domestic environments every day, being more common to see them carrying out tasks in home scenarios. In the future, robots are expected to increasingly perform more complex tasks and, therefore, be able to acquire experience from different sources as quickly as possible. A plausible approach to address this issue is interactive feedback, where a trainer advises a learner on which actions should be taken from specific states to speed up the learning process. Moreover, deep reinforcement learning has been recently widely utilized in robotics to learn the environment and acquire new skills autonomously. However, an open issue when using deep reinforcement learning is the excessive time needed to learn a task from raw input images. In this work, we propose a deep reinforcement learning approach with interactive feedback to learn a domestic task in a human-robot scenario. We compare three different learning methods using a simulated robotic arm for the task of organizing different objects; the proposed methods are (i) deep reinforcement learning (DeepRL); (ii) interactive deep reinforcement learning using a previously trained artificial agent as an advisor (agent-IDeepRL); and (iii) interactive deep reinforcement learning using a human advisor (human-IDeepRL). We demonstrate that interactive approaches provide advantages for the learning process. The obtained results show that a learner agent, using either agent-IDeepRL or human-IDeepRL, completes the given task earlier and has fewer mistakes compared to the autonomous DeepRL approach.