 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Performance of ML/DL Architectures on the MNIST-1D Dataset
Feb 12, 2026Small datasets like MNIST have historically been instrumental in advancing machine learning research by providing a controlled environment for rapid experimentation and model evaluation. However, their simplicity often limits their utility for distinguishing between advanced neural network architectures. To address these challenges, Greydanus et al. introduced the MNIST-1D dataset, a one-dimensional adaptation of MNIST designed to explore inductive biases in sequential data. This dataset maintains the advantages of small-scale datasets while introducing variability and complexity that make it ideal for studying advanced architectures. In this paper, we extend the exploration of MNIST-1D by evaluating the performance of Residual Networks (ResNet), Temporal Convolutional Networks (TCN), and Dilated Convolutional Neural Networks (DCNN). These models, known for their ability to capture sequential patterns and hierarchical features, were implemented and benchmarked alongside previously tested architectures such as logistic regression, MLPs, CNNs, and GRUs. Our experimental results demonstrate that advanced architectures like TCN and DCNN consistently outperform simpler models, achieving near-human performance on MNIST-1D. ResNet also shows significant improvements, highlighting the importance of leveraging inductive biases and hierarchical feature extraction in small structured datasets. Through this study, we validate the utility of MNIST-1D as a robust benchmark for evaluating machine learning architectures under computational constraints. Our findings emphasize the role of architectural innovations in improving model performance and offer insights into optimizing deep learning models for resource-limited environments.
How Can LLMs and Knowledge Graphs Contribute to Robot Safety? A Few-Shot Learning Approach
Dec 16, 2024Large Language Models (LLMs) are transforming the robotics domain by enabling robots to comprehend and execute natural language instructions. The cornerstone benefits of LLM include processing textual data from technical manuals, instructions, academic papers, and user queries based on the knowledge provided. However, deploying LLM-generated code in robotic systems without safety verification poses significant risks. This paper outlines a safety layer that verifies the code generated by ChatGPT before executing it to control a drone in a simulated environment. The safety layer consists of a fine-tuned GPT-4o model using Few-Shot learning, supported by knowledge graph prompting (KGP). Our approach improves the safety and compliance of robotic actions, ensuring that they adhere to the regulations of drone operations.
Explaining Agent's Decision-making in a Hierarchical Reinforcement Learning Scenario
Dec 14, 2022Reinforcement learning is a machine learning approach based on behavioral psychology. It is focused on learning agents that can acquire knowledge and learn to carry out new tasks by interacting with the environment. However, a problem occurs when reinforcement learning is used in critical contexts where the users of the system need to have more information and reliability for the actions executed by an agent. In this regard, explainable reinforcement learning seeks to provide to an agent in training with methods in order to explain its behavior in such a way that users with no experience in machine learning could understand the agent's behavior. One of these is the memory-based explainable reinforcement learning method that is used to compute probabilities of success for each state-action pair using an episodic memory. In this work, we propose to make use of the memory-based explainable reinforcement learning method in a hierarchical environment composed of sub-tasks that need to be first addressed to solve a more complex task. The end goal is to verify if it is possible to provide to the agent the ability to explain its actions in the global task as well as in the sub-tasks. The results obtained showed that it is possible to use the memory-based method in hierarchical environments with high-level tasks and compute the probabilities of success to be used as a basis for explaining the agent's behavior.
Explainable Deep Reinforcement Learning Using Introspection in a Non-episodic Task
Aug 18, 2021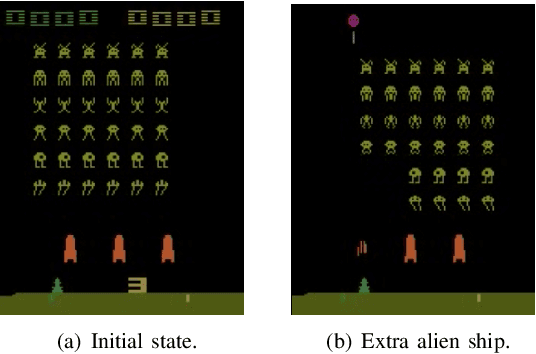
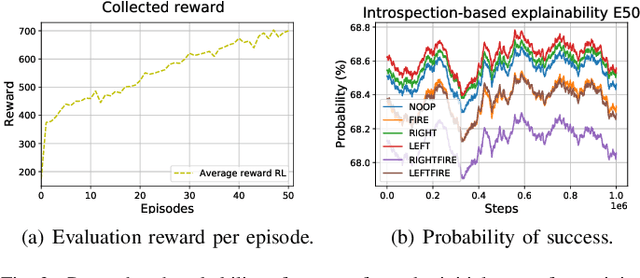
Explainable reinforcement learning allows artificial agents to explain their behavior in a human-like manner aiming at non-expert end-users. An efficient alternative of creating explanations is to use an introspection-based method that transforms Q-values into probabilities of success used as the base to explain the agent's decision-making process. This approach has been effectively used in episodic and discrete scenarios, however, to compute the probability of success in non-episodic and more complex environments has not been addressed yet. In this work, we adapt the introspection method to be used in a non-episodic task and try it in a continuous Atari game scenario solved with the Rainbow algorithm. Our initial results show that the probability of success can be computed directly from the Q-values for all possible actions.
Unmanned Aerial Vehicle Control Through Domain-based Automatic Speech Recognition
Sep 09, 2020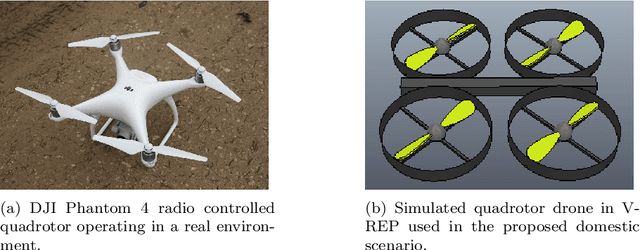
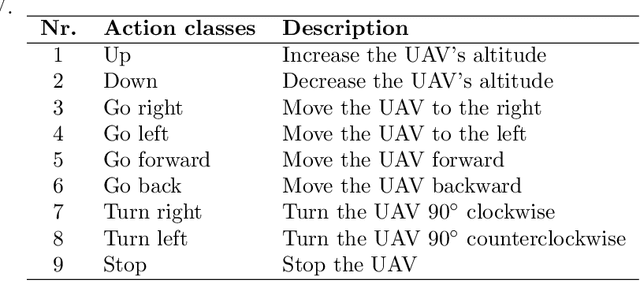
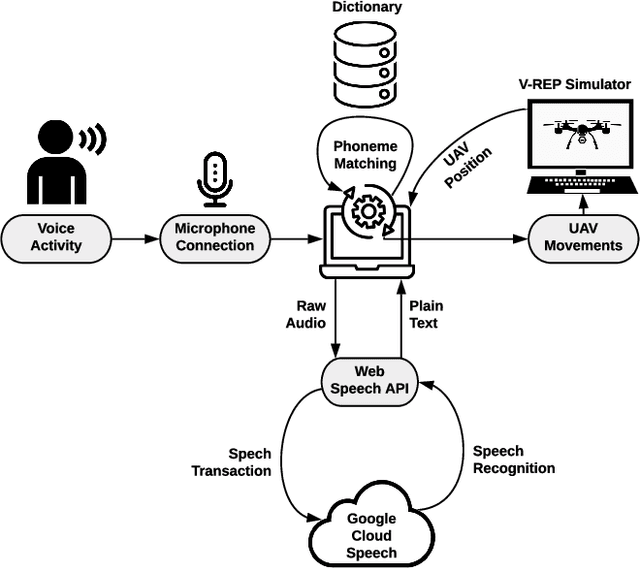
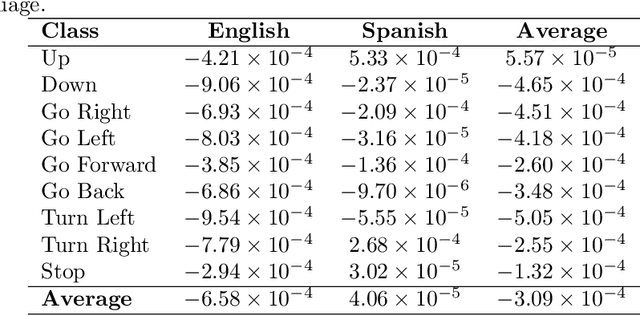
Currently, unmanned aerial vehicles, such as drones, are becoming a part of our lives and reaching out to many areas of society, including the industrialized world. A common alternative to control the movements and actions of the drone is through unwired tactile interfaces, for which different remote control devices can be found. However, control through such devices is not a natural, human-like communication interface, which sometimes is difficult to master for some users. In this work, we present a domain-based speech recognition architecture to effectively control an unmanned aerial vehicle such as a drone. The drone control is performed using a more natural, human-like way to communicate the instructions. Moreover, we implement an algorithm for command interpretation using both Spanish and English languages, as well as to control the movements of the drone in a simulated domestic environment. The conducted experiments involve participants giving voice commands to the drone in both languages in order to compare the effectiveness of each of them, considering the mother tongue of the participants in the experiment. Additionally, different levels of distortion have been applied to the voice commands in order to test the proposed approach when facing noisy input signals. The obtained results show that the unmanned aerial vehicle is capable of interpreting user voice instructions achieving an improvement in speech-to-action recognition for both languages when using phoneme matching in comparison to only using the cloud-based algorithm without domain-based instructions. Using raw audio inputs, the cloud-based approach achieves 74.81% and 97.04% accuracy for English and Spanish instructions respectively, whereas using our phoneme matching approach the results are improved achieving 93.33% and 100.00% accuracy for English and Spanish languages.
KutralNet: A Portable Deep Learning Model for Fire Recognition
Aug 16, 2020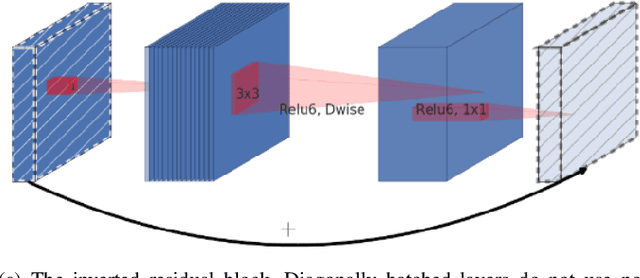
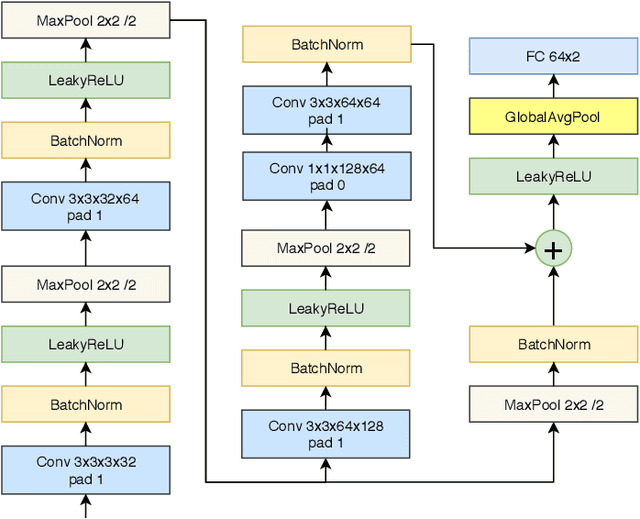
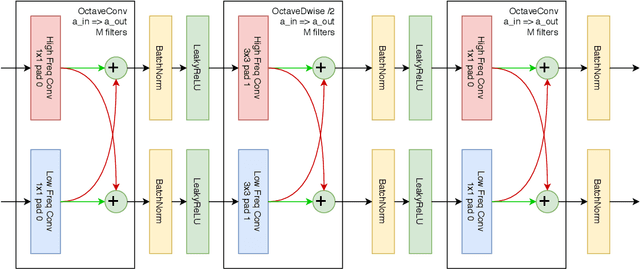
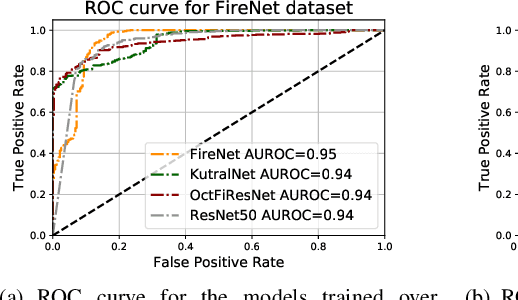
Most of the automatic fire alarm systems detect the fire presence through sensors like thermal, smoke, or flame. One of the new approaches to the problem is the use of images to perform the detection. The image approach is promising since it does not need specific sensors and can be easily embedded in different devices. However, besides the high performance, the computational cost of the used deep learning methods is a challenge to their deployment in portable devices. In this work, we propose a new deep learning architecture that requires fewer floating-point operations (flops) for fire recognition. Additionally, we propose a portable approach for fire recognition and the use of modern techniques such as inverted residual block, convolutions like depth-wise, and octave, to reduce the model's computational cost. The experiments show that our model keeps high accuracy while substantially reducing the number of parameters and flops. One of our models presents 71\% fewer parameters than FireNet, while still presenting competitive accuracy and AUROC performance. The proposed methods are evaluated on FireNet and FiSmo datasets. The obtained results are promising for the implementation of the model in a mobile device, considering the reduced number of flops and parameters acquired.
A Comparison of Humanoid Robot Simulators: A Quantitative Approach
Aug 11, 2020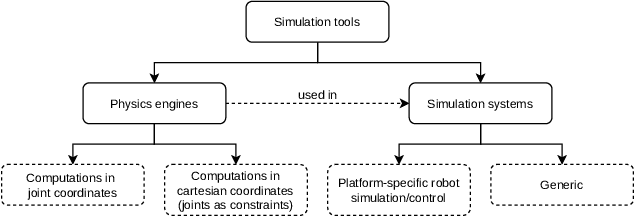

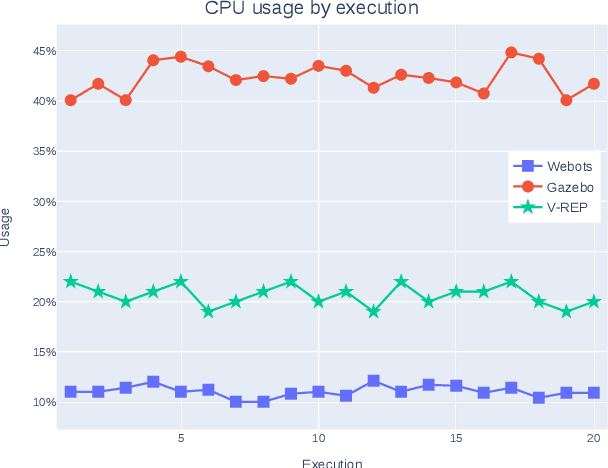
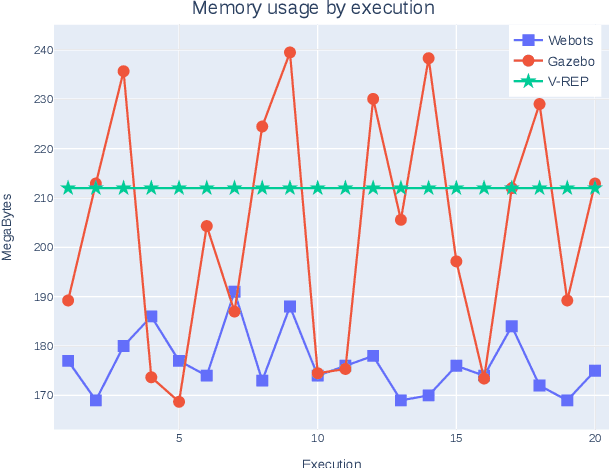
Research on humanoid robotic systems involves a considerable amount of computational resources, not only for the involved design but also for its development and subsequent implementation. For robotic systems to be implemented in real-world scenarios, in several situations, it is preferred to develop and test them under controlled environments in order to reduce the risk of errors and unexpected behavior. In this regard, a more accessible and efficient alternative is to implement the environment using robotic simulation tools. This paper presents a quantitative comparison of Gazebo, Webots, and V-REP, three simulators widely used by the research community to develop robotic systems. To compare the performance of these three simulators, elements such as CPU, memory footprint, and disk access are used to measure and compare them to each other. In order to measure the use of resources, each simulator executes 20 times a robotic scenario composed by a NAO robot that must navigate to a goal position avoiding a specific obstacle. In general terms, our results show that Webots is the simulator with the lowest use of resources, followed by V-REP, which has advantages over Gazebo, mainly because of the CPU use.
Deep Reinforcement Learning with Interactive Feedback in a Human-Robot Environment
Jul 07, 2020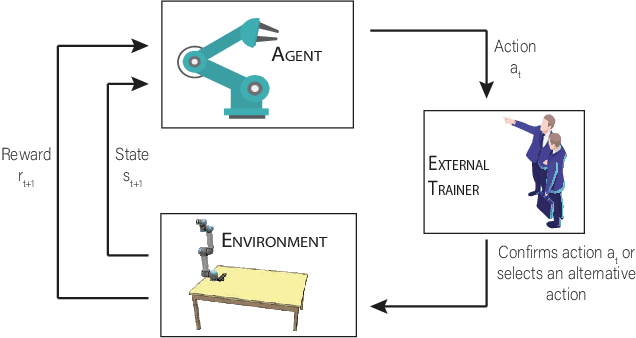
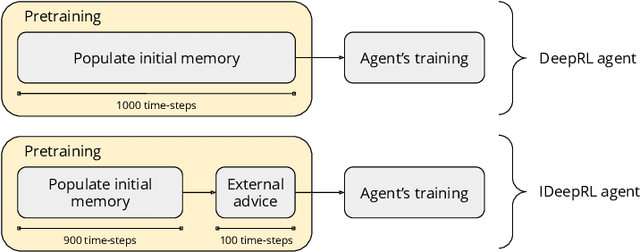
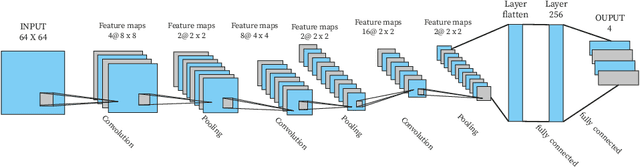

Robots are extending their presence in domestic environments every day, being more common to see them carrying out tasks in home scenarios. In the future, robots are expected to increasingly perform more complex tasks and, therefore, be able to acquire experience from different sources as quickly as possible. A plausible approach to address this issue is interactive feedback, where a trainer advises a learner on which actions should be taken from specific states to speed up the learning process. Moreover, deep reinforcement learning has been recently widely utilized in robotics to learn the environment and acquire new skills autonomously. However, an open issue when using deep reinforcement learning is the excessive time needed to learn a task from raw input images. In this work, we propose a deep reinforcement learning approach with interactive feedback to learn a domestic task in a human-robot scenario. We compare three different learning methods using a simulated robotic arm for the task of organizing different objects; the proposed methods are (i) deep reinforcement learning (DeepRL); (ii) interactive deep reinforcement learning using a previously trained artificial agent as an advisor (agent-IDeepRL); and (iii) interactive deep reinforcement learning using a human advisor (human-IDeepRL). We demonstrate that interactive approaches provide advantages for the learning process. The obtained results show that a learner agent, using either agent-IDeepRL or human-IDeepRL, completes the given task earlier and has fewer mistakes compared to the autonomous DeepRL approach.