 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experiment on an automated literature survey of data-driven speech enhancement methods
Oct 10, 2023



The increasing number of scientific publications in acoustics, in general, presents difficulties in conducting traditional literature surveys. This work explores the use of a generative pre-trained transformer (GPT) model to automate a literature survey of 116 articles on data-driven speech enhancement methods. The main objective is to evaluate the capabilities and limitations of the model in providing accurate responses to specific queries about the papers selected from a reference human-based survey. While we see great potential to automate literature surveys in acoustics, improvements are needed to address technical questions more clearly and accurately.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 24, 2023


In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
Feb 21, 2022
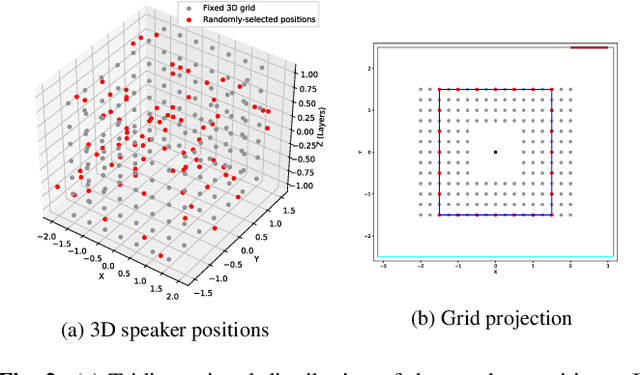
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model's efficiency and overcome the major difficulties encountered by the participants of the previous challenge. We updated the baseline model of Task 1, using the architecture that ranked first in the previous challenge edition. We wrote a new supporting API, improving its clarity and ease-of-use. In the end, we present and discuss the results submitted by all participants. L3DAS22 Challenge website: www.l3das.com/icassp2022.