 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 24, 2023


In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
ESSYS* Sharing #UC: An Emotion-driven Audiovisual Installation
Sep 07, 2022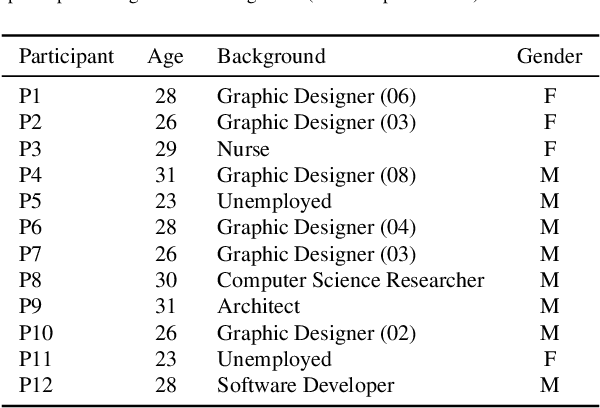


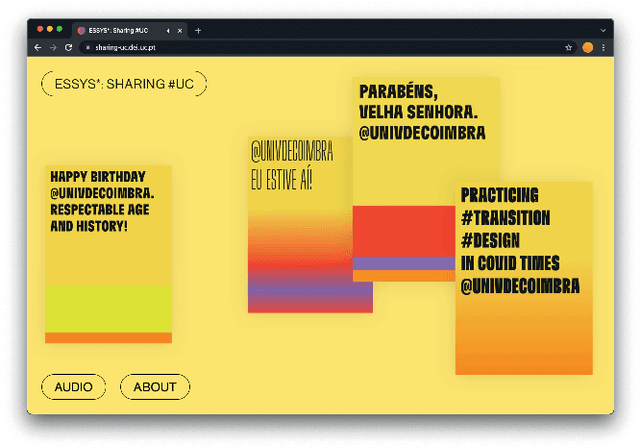
We present ESSYS* Sharing #UC, an audiovisual installation artwork that reflects upon the emotional context related to the university and the city of Coimbra, based on the data shared about them on Twitter. The installation was presented in an urban art gallery of C\'irculo de Artes Pl\'asticas de Coimbra during the summer and autumn of 2021. In the installation space, one may see a collection of typographic posters displaying the tweets and listening to an ever-changing ambient sound. The present audiovisuals are created by an autonomous computational creative approach, which employs a neural classifier to recognize the emotional context of a tweet and uses this resulting data as feedstock for the audiovisual generation. The installation's space is designed to promote an approach and blend between the online and physical perceptions of the same location. We applied multiple experiments with the proposed approach to evaluate the capability and performance. Also, we conduct interview-based evaluation sessions to understand how the installation elements, especially poster designs, are experienced by people regarding diversity, expressiveness and possible employment in other commercial and social scenarios.
* Paper to be published in 2022 IEEE VIS Arts Program (VISAP 2022). For the associated supplementary materials, see https://cdv.dei.uc.pt/essys_sharing_uc/
Optimal Decision Diagrams for Classification
May 28, 2022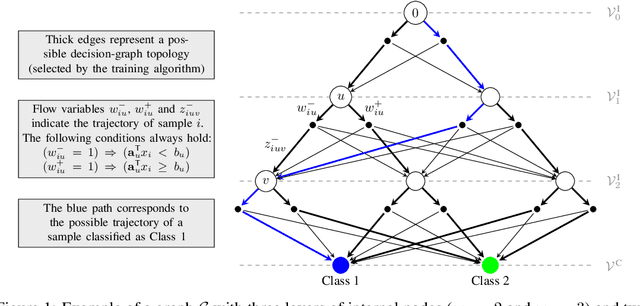
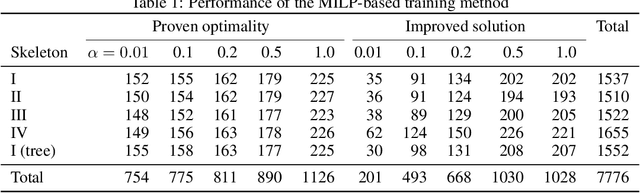
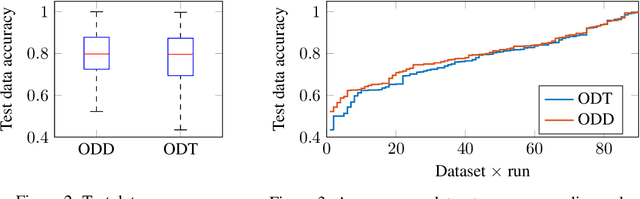
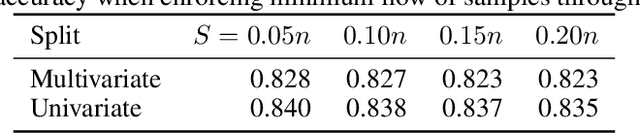
Decision diagrams for classification have some notable advantages over decision trees, as their internal connections can be determined at training time and their width is not bound to grow exponentially with their depth. Accordingly, decision diagrams are usually less prone to data fragmentation in internal nodes. However, the inherent complexity of training these classifiers acted as a long-standing barrier to their widespread adoption. In this context, we study the training of optimal decision diagrams (ODDs) from a mathematical programming perspective. We introduce a novel mixed-integer linear programming model for training and demonstrate its applicability for many datasets of practical importance. Further, we show how this model can be easily extended for fairness, parsimony, and stability notions. We present numerical analyses showing that our model allows training ODDs in short computational times, and that ODDs achieve better accuracy than optimal decision trees, while allowing for improved stability without significant accuracy losses.
A Pig, an Angel and a Cactus Walk Into a Blender: A Descriptive Approach to Visual Blending
Nov 30, 2017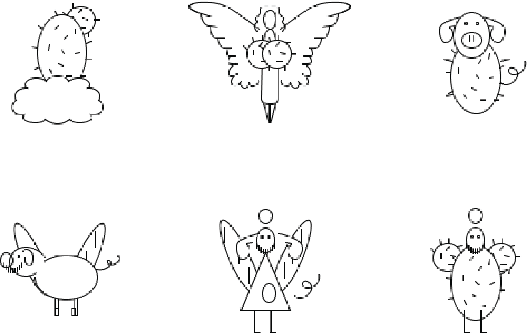
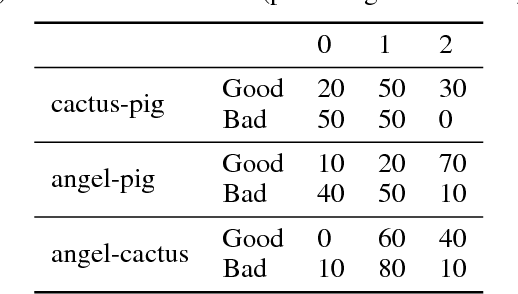
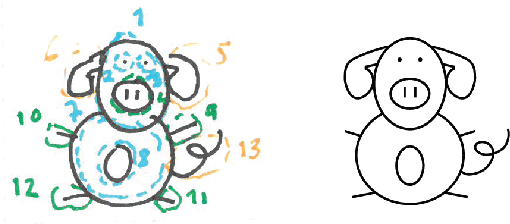
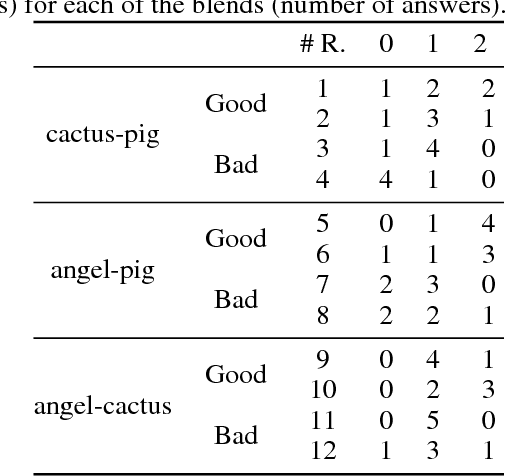
A descriptive approach for automatic generation of visual blends is presented. The implemented system, the Blender, is composed of two components: the Mapper and the Visual Blender. The approach uses structured visual representations along with sets of visual relations which describe how the elements (in which the visual representation can be decomposed) relate among each other. Our system is a hybrid blender, as the blending process starts at the Mapper (conceptual level) and ends at the Visual Blender (visual representation level). The experimental results show that the Blender is able to create analogies from input mental spaces and produce well-composed blends, which follow the rules imposed by its base-analogy and its relations. The resulting blends are visually interesting and some can be considered as unexpected.
High-Speed Tracking with Kernelized Correlation Filters
Nov 05, 2014
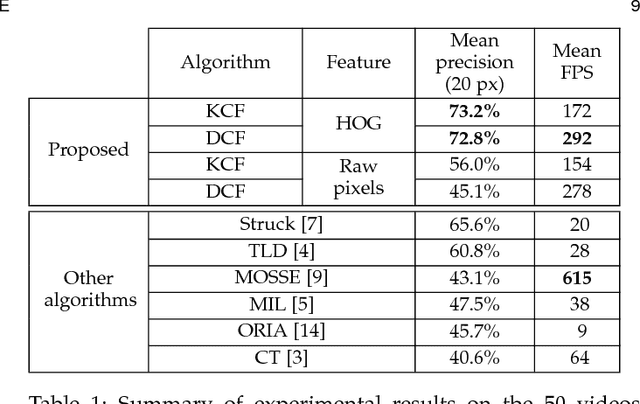

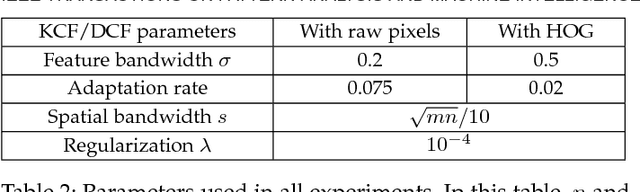
The core component of most modern trackers is a discriminative classifier, tasked with distinguishing between the target and the surrounding environment. To cope with natural image changes, this classifier is typically trained with translated and scaled sample patches. Such sets of samples are riddled with redundancies -- any overlapping pixels are constrained to be the same. Based on this simple observation, we propose an analytic model for datasets of thousands of translated patches. By showing that the resulting data matrix is circulant, we can diagonalize it with the Discrete Fourier Transform, reducing both storage and computation by several orders of magnitude. Interestingly, for linear regression our formulation is equivalent to a correlation filter, used by some of the fastest competitive trackers. For kernel regression, however, we derive a new Kernelized Correlation Filter (KCF), that unlike other kernel algorithms has the exact same complexity as its linear counterpart. Building on it, we also propose a fast multi-channel extension of linear correlation filters, via a linear kernel, which we call Dual Correlation Filter (DCF). Both KCF and DCF outperform top-ranking trackers such as Struck or TLD on a 50 videos benchmark, despite running at hundreds of frames-per-second, and being implemented in a few lines of code (Algorithm 1). To encourage further developments, our tracking framework was made open-source.