 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification
Oct 02, 2023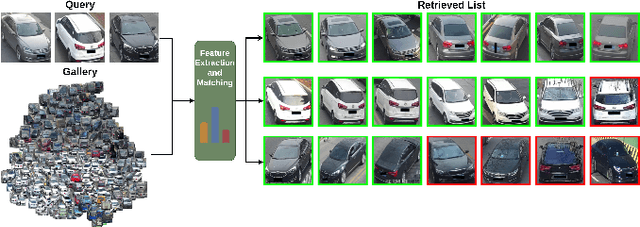
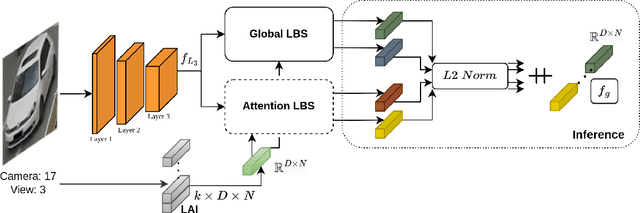
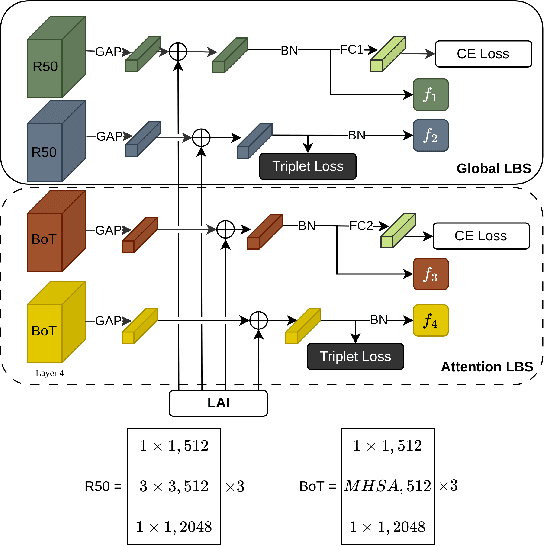
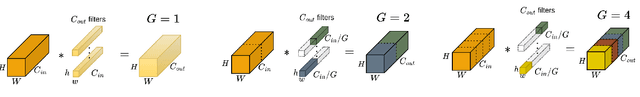
This paper presents an efficient and lightweight multi-branch deep architecture to improve vehicle re-identification (V-ReID). While most V-ReID work uses a combination of complex multi-branch architectures to extract robust and diversified embeddings towards re-identification, we advocate that simple and lightweight architectures can be designed to fulfill the Re-ID task without compromising performance. We propose a combination of Grouped-convolution and Loss-Branch-Split strategies to design a multi-branch architecture that improve feature diversity and feature discriminability. We combine a ResNet50 global branch architecture with a BotNet self-attention branch architecture, both designed within a Loss-Branch-Split (LBS) strategy. We argue that specialized loss-branch-splitting helps to improve re-identification tasks by generating specialized re-identification features. A lightweight solution using grouped convolution is also proposed to mimic the learning of loss-splitting into multiple embeddings while significantly reducing the model size. In addition, we designed an improved solution to leverage additional metadata, such as camera ID and pose information, that uses 97% less parameters, further improving re-identification performance. In comparison to state-of-the-art (SoTA) methods, our approach outperforms competing solutions in Veri-776 by achieving 85.6% mAP and 97.7% CMC1 and obtains competitive results in Veri-Wild with 88.1% mAP and 96.3% CMC1. Overall, our work provides important insights into improving vehicle re-identification and presents a strong basis for other retrieval tasks. Our code is available at the https://github.com/videturfortuna/vehicle_reid_itsc2023.
Lifting Object Detection Datasets into 3D
Jul 31, 2016
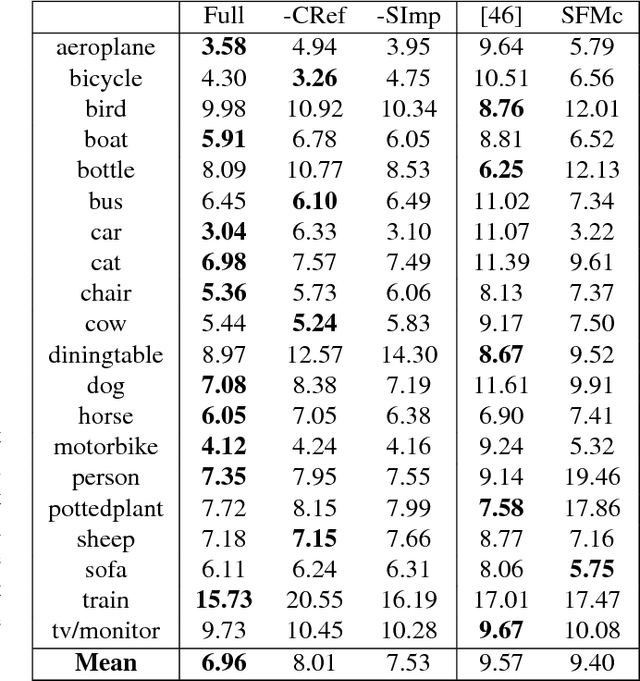
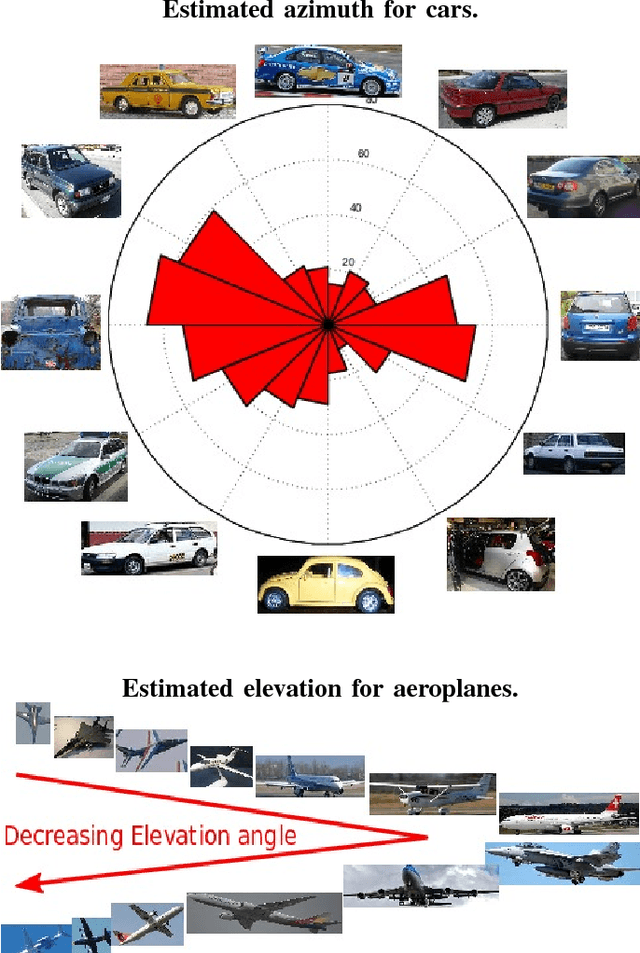
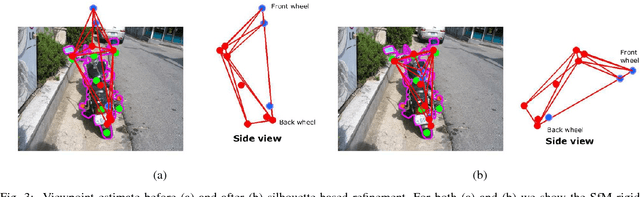
While data has certainly taken the center stage in computer vision in recent years, it can still be difficult to obtain in certain scenarios. In particular, acquiring ground truth 3D shapes of objects pictured in 2D images remains a challenging feat and this has hampered progress in recognition-based object reconstruction from a single image. Here we propose to bypass previous solutions such as 3D scanning or manual design, that scale poorly, and instead populate object category detection datasets semi-automatically with dense, per-object 3D reconstructions, bootstrapped from:(i) class labels, (ii) ground truth figure-ground segmentations and (iii) a small set of keypoint annotations. Our proposed algorithm first estimates camera viewpoint using rigid structure-from-motion and then reconstructs object shapes by optimizing over visual hull proposals guided by loose within-class shape similarity assumptions. The visual hull sampling process attempts to intersect an object's projection cone with the cones of minimal subsets of other similar objects among those pictured from certain vantage points. We show that our method is able to produce convincing per-object 3D reconstructions and to accurately estimate cameras viewpoints on one of the most challenging existing object-category detection datasets, PASCAL VOC. We hope that our results will re-stimulate interest on joint object recognition and 3D reconstruction from a single image.
High-Speed Tracking with Kernelized Correlation Filters
Nov 05, 2014
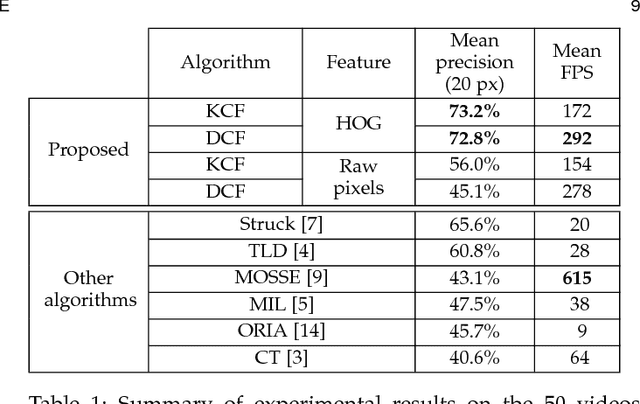

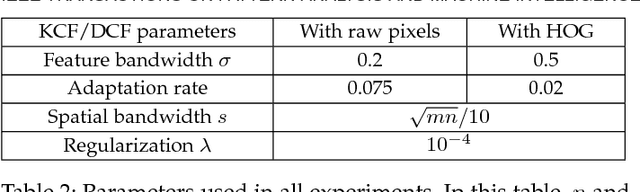
The core component of most modern trackers is a discriminative classifier, tasked with distinguishing between the target and the surrounding environment. To cope with natural image changes, this classifier is typically trained with translated and scaled sample patches. Such sets of samples are riddled with redundancies -- any overlapping pixels are constrained to be the same. Based on this simple observation, we propose an analytic model for datasets of thousands of translated patches. By showing that the resulting data matrix is circulant, we can diagonalize it with the Discrete Fourier Transform, reducing both storage and computation by several orders of magnitude. Interestingly, for linear regression our formulation is equivalent to a correlation filter, used by some of the fastest competitive trackers. For kernel regression, however, we derive a new Kernelized Correlation Filter (KCF), that unlike other kernel algorithms has the exact same complexity as its linear counterpart. Building on it, we also propose a fast multi-channel extension of linear correlation filters, via a linear kernel, which we call Dual Correlation Filter (DCF). Both KCF and DCF outperform top-ranking trackers such as Struck or TLD on a 50 videos benchmark, despite running at hundreds of frames-per-second, and being implemented in a few lines of code (Algorithm 1). To encourage further developments, our tracking framework was made open-source.