 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPITU: A Benchmark for Evaluating Instruction-Following in Brazilian Portuguese with Literary Context
Mar 23, 2026We introduce CAPITU, a benchmark for evaluating instruction-following capabilities of Large Language Models (LLMs) in Brazilian Portuguese. Unlike existing benchmarks that focus on English or use generic prompts, CAPITU contextualizes all tasks within eight canonical works of Brazilian literature, combining verifiable instruction constraints with culturally-grounded content. The benchmark comprises 59 instruction types organized into seven categories, all designed to be automatically verifiable without requiring LLM judges or human evaluation. Instruction types include Portuguese-specific linguistic constraints (word termination patterns like -ando/-endo/-indo, -inho/-inha, -mente) and structural requirements. We evaluate 18 state-of-the-art models across single-turn and multi-turn settings. Our results show that frontier reasoning models achieve strong performance (GPT-5.2 with reasoning: 98.5% strict accuracy), while Portuguese-specialized models offer competitive cost-efficiency (Sabiazinho-4: 87.0% at \$0.13 vs Claude-Haiku-4.5: 73.5% at \$1.12). Multi-turn evaluation reveals significant variation in constraint persistence, with conversation-level accuracy ranging from 60% to 96% across models. We identify specific challenges in morphological constraints, exact counting, and constraint persistence degradation across turns. We release the complete benchmark, evaluation code, and baseline results to facilitate research on instruction-following in Portuguese.
Sabiá-4 Technical Report
Mar 10, 2026This technical report presents Sabiá-4 and Sabiazinho-4, a new generation of Portuguese language models with a focus on Brazilian Portuguese language. The models were developed through a four-stage training pipeline: continued pre-training on Portuguese and Brazilian legal corpora, long-context extension to 128K tokens, supervised fine-tuning on instruction data spanning chat, code, legal tasks, and function calling, and preference alignment. We evaluate the models on six benchmark categories: conversational capabilities in Brazilian Portuguese, knowledge of Brazilian legislation, long-context understanding, instruction following, standardized exams, and agentic capabilities including tool use and web navigation. Results show that Sabiá-4 and Sabiazinho-4 achieve a favorable cost-performance trade-off compared to other models, positioning them in the upper-left region of the pricing-accuracy chart. The models show improvements over previous generations in legal document drafting, multi-turn dialogue quality, and agentic task completion.
Ticket-Bench: A Kickoff for Multilingual and Regionalized Agent Evaluation
Sep 17, 2025
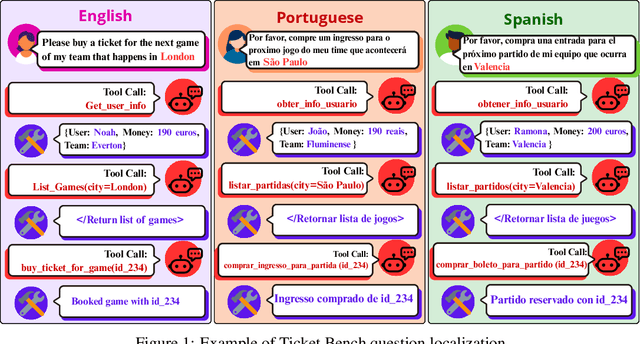
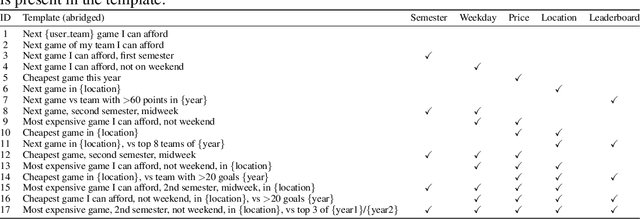
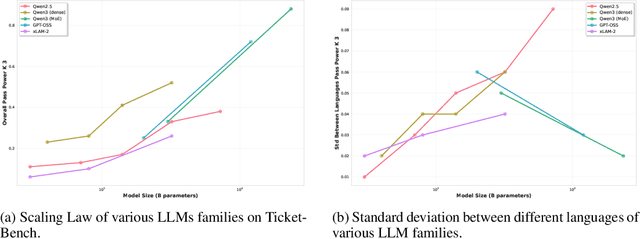
Large language models (LLMs) are increasingly deployed as task-oriented agents, where success depends on their ability to generate accurate function calls under realistic, multilingual conditions. However, existing agent evaluations largely overlook cultural and linguistic diversity, often relying on monolingual or naively translated benchmarks. We introduce Ticket-Bench, a benchmark for multilingual agent evaluation in task-oriented scenarios. Ticket-Bench simulates the domain of soccer ticket purchases across six major languages: Portuguese, English, Spanish, German, Italian, and French. Using localized teams, cities, and user profiles to provide a higher level of realism. We evaluate a wide range of commercial and open-source LLMs, measuring function-calling accuracy and consistency across languages. Results show that reasoning-oriented models (e.g., GPT-5, Qwen3-235B) dominate performance but still exhibit notable cross-lingual disparities. These findings underscore the need for culturally aware, multilingual benchmarks to guide the development of robust LLM agents.
BRoverbs -- Measuring how much LLMs understand Portuguese proverbs
Sep 10, 2025
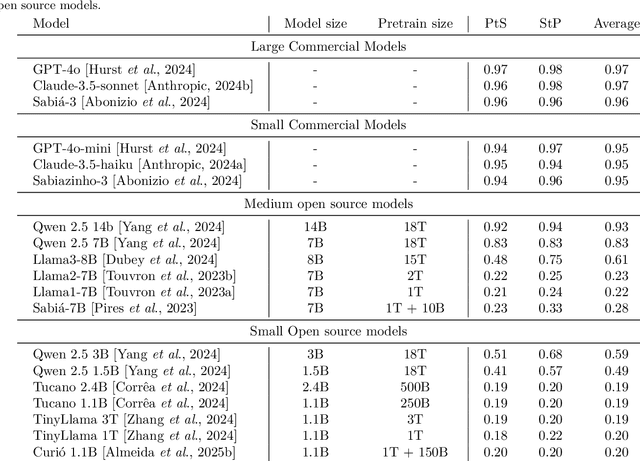
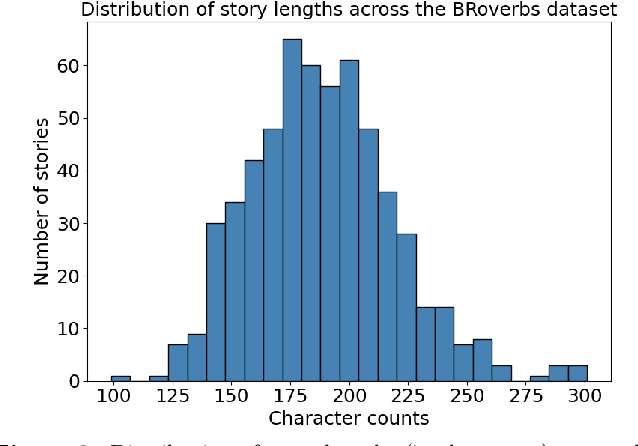
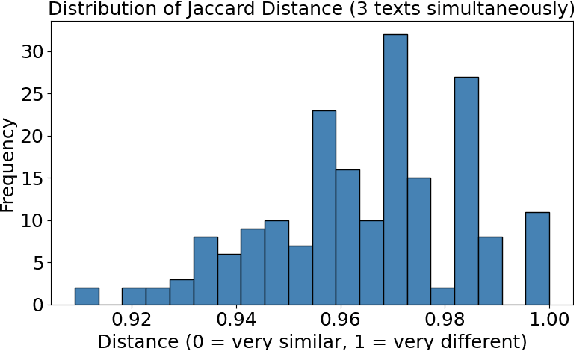
Large Language Models (LLMs) exhibit significant performance variations depending on the linguistic and cultural context in which they are applied. This disparity signals the necessity of mature evaluation frameworks that can assess their capabilities in specific regional settings. In the case of Portuguese, existing evaluations remain limited, often relying on translated datasets that may not fully capture linguistic nuances or cultural references. Meanwhile, native Portuguese-language datasets predominantly focus on structured national exams or sentiment analysis of social media interactions, leaving gaps in evaluating broader linguistic understanding. To address this limitation, we introduce BRoverbs, a dataset specifically designed to assess LLM performance through Brazilian proverbs. Proverbs serve as a rich linguistic resource, encapsulating cultural wisdom, figurative expressions, and complex syntactic structures that challenge the model comprehension of regional expressions. BRoverbs aims to provide a new evaluation tool for Portuguese-language LLMs, contributing to advancing regionally informed benchmarking. The benchmark is available at https://huggingface.co/datasets/Tropic-AI/BRoverbs.
TiEBe: A Benchmark for Assessing the Current Knowledge of Large Language Models
Jan 13, 2025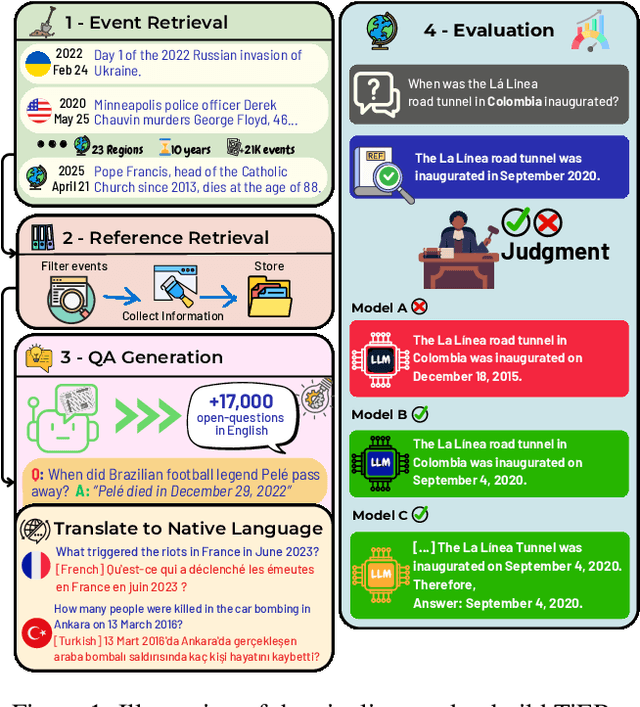
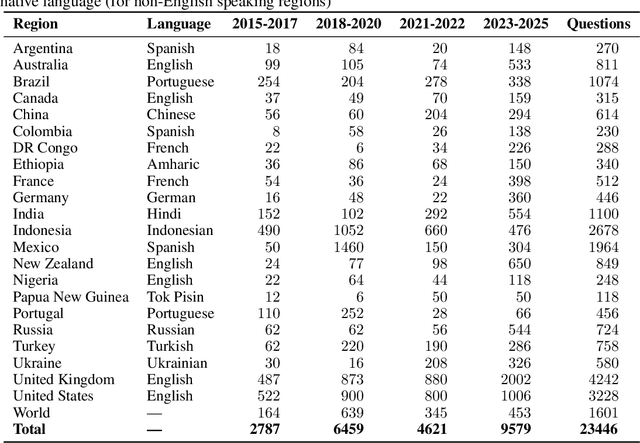

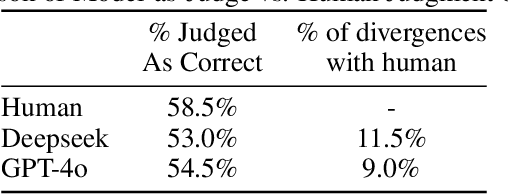
In a rapidly evolving knowledge landscape and the increasing adoption of large language models, a need has emerged to keep these models continuously updated with current events. While existing benchmarks evaluate general factual recall, they often overlook two critical aspects: the ability of models to integrate evolving knowledge through continual learning and the significant regional disparities in their performance. To address these gaps, we introduce the Timely Events Benchmark (TiEBe), a dataset containing over 11,000 question-answer pairs focused on globally and regionally significant events. TiEBe leverages structured retrospective data from Wikipedia, enabling continuous updates to assess LLMs' knowledge of evolving global affairs and their understanding of events across different regions. Our benchmark demonstrates that LLMs exhibit substantial geographic disparities in factual recall, emphasizing the need for more balanced global knowledge representation. Furthermore, TiEBe serves as a tool for evaluating continual learning strategies, providing insights into models' ability to acquire new information without forgetting past knowledge.
Sabiá-3 Technical Report
Oct 15, 2024This report presents Sabi\'a-3, our new flagship language model trained on a large brazilian-centric corpus. Evaluations across diverse professional and academic benchmarks show a strong performance on Portuguese and Brazil-related tasks. Sabi\'a-3 shows large improvements in comparison to our previous best of model, Sabi\'a-2 Medium, especially in reasoning-intensive tasks. Notably, Sabi\'a-3's average performance matches frontier LLMs, while it is offered at a three to four times lower cost per token, reinforcing the benefits of domain specialization.